正则表达式
什么是正则表达式
正则表达式是一组由字母和符号组成的特殊文本,它可以用来从文本中找出满足你想要的格式的句子。
Unix系统偏好于以可读的文本处理,例如vi、emacs、grep、sed、awk都支持正则表达式。
Posix标准中RE分为:
- BRE
- ERE
RE字符集
RE将字符分为普通字符和元字符,元字符不代表他们本身的字面意思,他们都有特殊的含义。一些元字符写在方括号中的时候有一些特殊的意思。以下是一些元字符的介绍:
| 字符 | BRE/ERE | 含义 |
|---|---|---|
| \ | Both | 转义 |
| . | Both | 匹配单个字符 |
| * | Both | 匹配任意次,可以是0次。a表示匹配任意多次a,.表示任意字符串 |
| ^ | Both | 锚定匹配位置,从一行的行首开始 |
| $ | Both | 锚定匹配位置,到一行的行尾 |
| […] | Both | 匹配中括号内的某个字符。x-y表示一个范围;[^…]表示不匹配中括号中的任意字符。[开括号后跟-或],-]转义为普通字符 |
| {n,m} | BRE | 匹配次数为[n,m],{n}匹配n次,{n,}最小匹配次数为n |
| () | BRE | 定义一个匹配位置,在后部可以引用该位置。例如,(ab).*\1表示ab字符串包夹了一个任意字符串。 |
| \n | BRE | 引用已经定义的位置,可以从\1到\9 |
| {n,m} | ERE | 与BRE的{n,m}相同 |
| + | ERE | 匹配至少1次 |
| ? | ERE | 匹配0或1次 |
| | | ERE | 或 |
| () | ERE | 匹配括号内的整个字符串 |
其中[ ]表达式是选择匹配中任意一个字符,.* 即贪婪匹配,会在满足条件下尽可能多匹配。
c[aeiouy]t,匹配可以是cat、cet、cot等[0123456789]表示为[0-9]\([[:alpha:]_][[:alnum:]_]*\) = \1c语言赋值语句\(why\).*\1whyXXwhy
特别需要记忆的:
- [[:alnum:]] 字符+数字
- [[:alpha:]] 字符
- [[:digit:]] 数字
- [[:lower:]] 小写字符
- [[:upper:]] 大写字符
- [[:space:]] 空字符:空格、tab等
一个在线练习regex的网站:
Markdown文件中# (#后跟一个空格)表示一级标题,## 表示二级标题,匹配所有标题的BRE正则表达式
^#{1,}
匹配html、xml文件中标记<…>的正则表达式
<[^>]*>
vi中使用正则表达式
在上一篇文章末尾我们就提到过搜索替换要配合正则表达式才能达到最优效果,现在我们学习在vi中使用正则表达式
首先需要明确一点,vi中的正则表达式和先前学的不一定完全一致,最好先使用:help pattern得到更多帮助。
查询
首先检查magic变量,一般是magic。
:set magic?
/或?后跟一个RE表达式即可完成查询
替换
查询的通用格式是:
:range s/from/to/flags
flags为g表示行中所有的匹配项都替换,c则先要通过用户确认才替换。
实例有:
| 实例 | 含义 |
|---|---|
| :n1,n2s/word1/word2/g | n1 n2为数字,在第n1行与n2行之间寻找word1这个字符串并将其替换为word2 |
| :1,$s/word1/word2/g | 从第一行到最后一行寻找word1字符串,并将字符串替换为word2 |
| :1,$s/word1/word2/gc | 从第一行到最后一行寻找word1字符串,并将字符串替换为word2,在取代前显示提示字符给用户确认是否替换 |
关于range,有下面的规定:
- 如果不指定range,则表示当前行。
m,n: 从m行到n行。0: 最开始一行(可能是这样)。$: 最后一行.: 当前行%: 所有行
:%s/from/to/g就是在全文替换from为to,也是最常用的操作。
重定向与文件操作
重定向
重定向和管道是UNIX中非常重要的一部分,可以将我们之前所学部分连接起来。shell提供的最有用的功能之一就是”shell重定向操作符”,shell重定向操作符允许把进程的输出保存到文件中,或者用文件作为进程的输入。在Unix系统中,文件是io的基本抽象。标准输入、标准输出、错误输出可以替换为其它文件。
标准输出重定向:
- command > file
- command >> file 追加
标准输入重定向:
- command < file
- command << EOF 标准输入,当碰到EOF字符串时,输入结束
标准错误输出重定向:
- command 2> file 将command的错误输出重定向到file文件
- command 2>> file 追加重定向
重定向标准输出+标准错误输出:
- command &> file
- command &>> file 追加重定向
Unix中特别的文件,/dev/null,其作为bit垃圾桶
使用重定向的几个例子:
- cat myfirst mysecond > mythird
- cat > myfirst << EOF
管道操作符
管道符使用”丨”代表。管道符也是用来连接多条命令的,如”命令1丨命令2”,用管道符连接的命令,命令 1 的正确输出作为命令 2 的操作对象。这里需要注意,命令 1 必须有正确输出,而命令 2 必须可以处理命令 1 的输出结果;而且命令 2 只能处理命令 1 的正确输出,而不能处理错误输出。
command A | command B,两条命令之间是以一个匿名文件传输
例:ls –al | grep -e “^d”
Shell如何实现管道?
- pipe()函数创建一个两个文件描述符,一个输入,一个输出
- fork创建子进程,子进程继承父进程的文件描述符
- 父进程关闭管道的输出端,子进程将标准输入替换为管道输入,随后子进程关闭管道输入和输出。
- 父进程写完数据后,关闭管道输出。子进程从父进程收到EOF,输入数据完毕
将父进程的标准输出替换为pipe输出,子进程的标准输入替换为pipe输入
文件操作
文件操作命令
在先前我们就学习了一些有关文件的命令,现在我们将继续学习
cp拷贝源文件成目标文件
- -b 如果目标文件存在备份
- -i 如果目标文件存在,提示
- -r 递归拷贝
mv移动文件,也可以用来重命名文件
- -b 如果目标文件存在,则备份
- -i 如果目标文件存在,提示
- -f 强制移动
wc统计字数
- -l 统计行数
- -w 统计单词数量
- -c 统计字符数量
head/tail 显示文件头部/尾部,默认显示10行
- -n 显示头部n行
- -c n 显示头部n个字符
more命令分页显示文件内容,可以向后翻,但不能向前翻
less命令是more的改进,可以向前翻
ln在文件之间建立连接
在Unix世界里有两个’link’(连接)概念,一般称之为硬连接和软连接。一个硬连接仅仅是一个文件名。一个软连接(或符号连接)是完全不同的:它是一个包含了路径信息的小小的指定文件。因此, 软连接可以指向不同文件系统里的文件,甚至可以指向一个不一定确实存在的文件,软链接完全可以当作 Windows 的快捷方式来对待,它的特点和快捷方式一样。
默认不带参数的情况下,ln创建的是硬链接,带-s参数的ln命令创建的是软链接,使用ls –i显示节点,ls -l中,第二列的数字就是显示连接数。
它们之间的区别在于
- 硬链接不度能对目录进行创建,只可对文件创建
- 软链接可知对文件或目录创建
- 删除一个硬链接文件并不影响其他有相同 inode 号的文件
硬链接不会建立自己的 inode 索引和 block(数据块),而是直接指向源文件的 inode 信息和 block,所以硬链接和源文件的 inode 号是一致的,只是增加引用计数。
而软链接会真正建立自己的 inode 索引和 block,所以软链接和源文件的 inode 号是不一致的,而且在软链接的 block 中,写的不是真正的数据,而仅仅是源文件的文件名及 inode 号。
Shell路径元字符
在Shell中也有存在需要操作大量文件的时候,因此shell支持“文件替换”,允许用户选择那些文件名与指定模式相匹配的文件。这些支持指定模式,具有特殊意义的字符被称为元字符(通配符)。注意,他与vi中的正则表达式相似但是不同。
| 元字符 | 功能 |
|---|---|
| ? | 匹配路径名的单个字符 |
| * | 匹配路径名的任意长度的字符串 |
| [list] | 匹配list中任意一个字符 |
| [!list] | 匹配不在list中的任意一个字符 |
通配符和正则表达式比较
(1)通配符和正则表达式看起来有点像,不能混淆。可以简单的理解为通配符只有*,?,[],{}这4种,而正则表达式复杂多了。
(2)*在通配符和正则表达式中有其不一样的地方,在通配符中*可以匹配任意的0个或多个字符,而在正则表达式中他是匹配之前的一个或者多个字符,不能独立使用的。比如通配符可以用*来匹配任意字符,而正则表达式不行,他只匹配任意长度的前面的字符。
其他文件操作命令
寻找文件 find
find命令用来在目录中定位一组与给定标准相匹配的文件。标准可以是文件名,在找到文件后,用户可以将命令定向到删除、重命名等其他文件操作,总的来说,find命令是一个有用且重要的命令。
find命令的格式与其他UNIX命令不同,他的语法为:
find pathname searchfile options action option
pathname表明find开始搜索的目录,然后会向下继续搜索他的子目录,除了用绝对路径表示外,可以用~表示home目录,.表示当前目录
搜索选项有:
| 选项 | 功能 |
|---|---|
| -name filename | 根据给定的filename做匹配查找,要加“” |
| -size +/-n | 查找大于或者小于n的文件 |
| -type filetype | 查找指定类型filetype的文件 |
| -atime +/-n | 查找n天以前/以内访问的文件 |
| -mtime +/-n | 查找n天以前/以内更改的文件 |
例:
find . -name “first.c” -print
find . -name “*.c” -print
Action选项有:
| 选项 | 功能 |
|---|---|
| 打印输出 | |
| -exec command; | 执行命令 |
| -ok command; | 在执行命令前要求确认 |
重点讲一下-exec选项,-exec允许用户给出一个命令,作用于发现的文件,-exec后跟指定命令,空格,反斜杠和分号,用户可以用一对大括号({})表示发现的文件名,当然后面会学到xargs来取代-exec,例子有:
find . -name "first.c" -mtime +90 -exec rm -i {} \;
寻找并删除当前目录下所有大于90天且名为first.c的文件,删除前要先确认
cut命令
cut命令纵向输出文件的某个列,一般与cat配合管道符联用。
| 选项 | 功能 |
|---|---|
| -f LIST | 指定剪切的域 |
| -d x | 指定域的分隔符 |
| -c LIST | 指定剪切字符位置 |
使用且只使用 -c 或 -f 中的一个选项,LIST由一个范围 (range) 或 逗号隔开的多个范围组成. 如下形式
- n 第n个字符或字段,从1开始计数
- n- 从第n个字符或字段到结束
- -n 从第1个字符或字段到第n个(包括第n)字符或字段结束
- n-m 表示[n,m]的域
- n,m 表示n和m域
默认的分隔符是TAB制表键
以/etc/passwd为例
cat /etc/passwd | cut -c 1-4 |head -5 #输出文件的前四个字符
cat /etc/passwd | cut -f1 -d ':' |head -5 #以:分割文件,输出第一个字段
paste命令
paste命令横向连接两个文件
| 选项 | 功能 |
|---|---|
| -d x | 指定域分隔符 |
默认的分隔符是TAB制表键
sort命令
sort命令排序按照行做字典序排列文件内容
| 选项 | 功能 |
|---|---|
| -b | 忽略行首的空格 |
| -d | 在字典序比较中,忽略标点符号和控制符号 |
| -t | 指定域分隔符 |
| -n | 数字以数值排序 |
| -r | 逆序排列 |
| -o | 指定输出文件 |
按照字典序,大写字母比小写字母更靠前
例
按照uid排列所有用户(0开始计数)
sort -t “:” -n +2 /etc/passwd
grep命令
grep是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
格式为: grep [OPTION…] PATTERNS [FILE…]
| 选项 | 功能 |
|---|---|
| -c | 只显示匹配的行数 |
| -i | 忽略大小写匹配 |
| -G | BRE,grep默认选项 |
| -E | ERE,egrep默认选项 |
| -e PATTERNS | 指定一个或多个RE |
| -v | 显示不匹配的行 |
| -n | 输出行号 |
以/etc/passwd为例,匹配以root开头或者以zhang开头的行,注意反斜杠
cat /etc/passwd |grep '^\(root\|zhang\)'
xargs
xargs 又称管道命令,构造参数等。是给命令传递参数的一个过滤器,也是组合多个命令的一个工具 它把一个数据流分割为一些足够小的块,以方便过滤器和命令进行处理 。简单的说 就是把 其他命令的给它的数据 传递给它后面的命令作为参数,xargs的格式为:
xargs [command [initial-arguments]]
xargs从标准输入上读,将标准输入文件按照空格/TAB拆解成参数,作为command执行参数,经常与find和awk或者tr配合使用
一个典型的例子:查找epoll_wait函数在那个文件:
find /usr/include –name “*.h” -type f | xargs grep “epoll_wait”
文件系统原理
Unix有三大抽象
- 进程、线程对执行过程
- 文件对io
- 地址空间对内存
有四种io:文件系统、块设备、字符设备、socket
- 块设备和字符设备出现在文件系统的名字空间
- Socket仅表现为文件
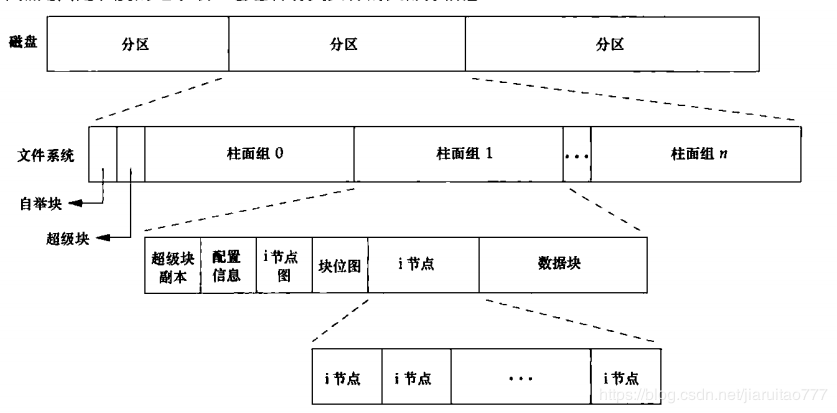
UNIX磁盘结构
UNIX里面,磁盘是一个标准块设备,一个UNIX磁盘被分成四个块:
- 主引导块
- 保存着引导程序,系统启动时激活。
- 超级块
- 包含磁盘自身的信息,包括磁盘总块数,空闲块数,块大小和使用块数。
- i节点列表块
- 维护i节点的列表,列表每个条目是一个64字节存储区的i节点,规则文件或目录文件的i节点包含着所在磁盘块的位置,特殊文件的i节点包含确定外围设备的信息。i节点还有许多信息,不累述了。
- 文件和目录块
- 存放数据,由 i 节点指向。
磁盘文件组织,需要从几个维度去考虑磁盘如何组织成文件
快速访问
方便修改
节省空间
考虑磁盘的空间组织,主要有几种形式:
变长的堆
定长的记录
索引
Unix文件系统的选择:堆+索引
- 索引 key,value对,key是文件名,要求变长,
- 目录文件
整体过程
登录时,UNIX读取根目录(i-node2),找出用户主目录(homedirectory),存储用户主目录的i节点号。当用cd改变目录时, UNIX用新目录的i节点号进行替换。
用系统工具或命令(例如vi或at)访问文件或者某个程序打开文件时, UNIX查找指定文件名的目录。每个文件名与i节点列表中的一个i节点相联系。UNIX通过用户工作目录的i节点开始搜索,但是如果用户给定了全路径名,则从根目录(i-node 2)开始查找。
下一章中我们会先来学习sed和tr命令.

