概 述
RAII (Resource Acquisition Is Initialization)
RAII 要求,资源的有效期与持有资源的对象的生命期严格绑定,即由对象的构造函数完成资源的分配(获取),同时由析构函数,完成资源的释放。在这种要求下,只要对象能正确地析构,就不会出现资源泄露问题。
C++三/五法则
- 当定义一个类时,我们显式地或隐式地指定了此类型的对象在拷贝、赋值和销毁时做什么。一个类通过定义三种特殊的成员函数来控制这些操作,分别是拷贝构造函数、赋值运算符和析构函数。
- 拷贝构造函数,定义了当用同类型的另一个对象初始化新对象时做什么;赋值运算符,定义了将一个对象赋予同类型的另一个对象时做什么;析构函数,定义了此类型的对象销毁时做什么。我们将这些操作称为拷贝控制操作。
- 由于拷贝控制操作是由三个特殊的成员函数来完成的,所以我们称此为“C++三法则”。在较新的C++11标准中,为了支持移动语义,又增加了移动构造函数和移动赋值运算符,这样共有五个特殊的成员函数,所以又称为“C++五法则”。也就是说,“三法则”是针对较旧的C++98 标准说的,“五法则” 是针对较新的C++11标准说的。为了统一称呼,后来人们干把它叫做“C++ 三/五法则”。
RAII , 如果没有解构函数,在每个带有返回的分支,都要手动释放所有之前的资源;与Java Python 等自动垃圾回收语言不同(由gc延时回收),C++结构函数是显示的,当进程离开了函数作用域自动销毁之前的资源,不含糊。这样做,有好处也有坏处,对于高性能计算,利大于弊。
RAII,异常安全(exception-safe)
C++ 标准保证了当异常发生时,会调用已创建对象的解构函数,因此 C++中不需要 finally 语句。
connection c = driver.getConnection();
try {
...
} catch (SQLException e) {
...
} finally {
c.close();
}比如Java语句,需要在 finally 里显示 close资源,而 C++可以在 catch异常同时,自动释放资源。
void test() {
std::ofstream fout("a.txt");
fout << "in\n";
throw std::runtime_error("error");
fout << "out\n";
}
int main() {
try {
test();
} catch (std::exception const &e) {
std::cout << "catch" << e.what() << std::endl;
}
return 0;
}编译器自动生成的函数:全家桶
除了 拷贝构造和 拷贝赋值,编译器会自动生成特殊函数。
struct C {
C(); // 默认构造函数
C(C const &c); // 拷贝构造函数
C(C &&c); // 移动构造函数 (C++11 引入)
C &operator=(C const &c); // 拷贝赋值函数
C &operator=(C &&c); // 移动赋值函数 (C++11 引入)
~C(); // 解构函数
}; 在其他面向对象语言中是看不到这些底层的函数。
Pig()
{}
// 拷贝构造
Pig(Pig const &other)
: m_name(other.m_name)
, m_weight(other.m_weight)
{}
// 移动构造
Pig(Pig &&other)
: m_name(std::move(other.m_name))
, m_weight(std::move(other.m_weight))
{}
// 拷贝赋值
Pig &operator=(Pig const &other) {
m_name = other.m_name;
m_weight = other.m_weight;
return *this;
}
// 移动赋值
Pig &operator=(Pig &&other) {
m_name = std::move(other.m_name);
m_weight = std::move(other.m_weight);
return *this;
}
~Pig() {}C++规定,除了智能指针,都是用深拷贝。以上这些函数都是编译器默认生成的。
三五法则深入理解

从一个例子出发。
#include <iostream>
struct Vector {
size_t m_size;
int *m_data;
// Vector(size_t n) { // 构造函数 - 对象初始化时调用
// m_size = n;
// m_data = (int *)malloc(n * sizeof(int));
// }
Vector(size_t n)
: m_size(n), m_data((int *)malloc(n * sizeof(int))) {}
~Vector() { // 解构函数 - 对象销毁时调用
free(m_data);
}
size_t size() const {
return m_size;
}
void resize(size_t size) {
m_size = size;
m_data = (int *)realloc(m_data, m_size);
}
int& operator[](size_t index) { // 当 v[index] 时调用
return m_data[index];
}
};
int main() {
Vector v(2);
v[0] = 4;
v[1] = 3;
v.resize(4);
v[2] = 2;
v[3] = 1;
int sum = 0;
for (size_t i = 0; i < v.size(); i++) {
sum += v[i];
}
std::cout << sum << std::endl;
}拷贝构造函数
Vector类 并没有定义拷贝构造函数,编译器实际会发生拷贝构造,发生一次浅拷贝。如果我们使用拷贝操作,会发生什么问题吗?
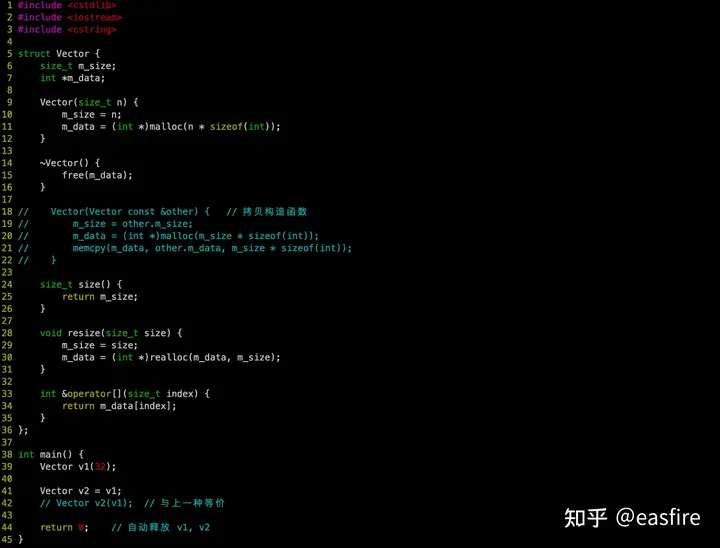
41行 Vector v2 = v1; 在执行以上语句时,编译器默认是会发生一次浅拷贝,那么在退出main函数时候,v1.m_data 会被释放两次(析构v1 v2,就会发生两次对 v1.m_data的释放;更危险的是,如果v1被释放,而v2还在被使用,空指针出现)
– 这就是为什么,一个类定义了 解构函数, 还要定义或删除 拷贝构造函数 和 拷贝赋值函数 的原因。
- 两种解决办法:
① 直接禁止用户拷贝这个类的对象,让用户拷贝时,报错
Vector(Vector const &) = delete;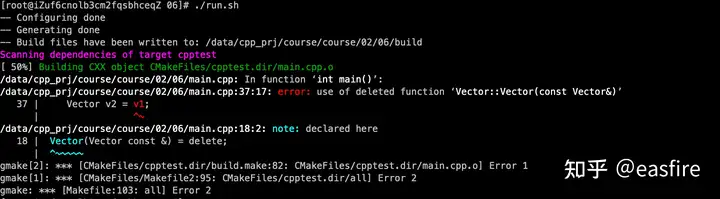
② 我们自己实现一下拷贝构造函数,通过深拷贝,解决指针双重释放的问题。– 如果要用浅拷贝,那涉及到 智能指针。
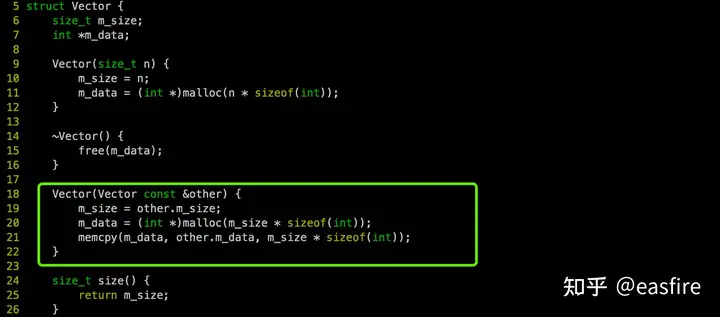
这样保证了 任何单次操作前后,对象都处于正确状态(存在或者删除),从而避免程序读到空悬指针。这就是保证了面向对象的 “封装:不变性”。
无论,size()/resize()这样的get/set模式,还是深拷贝,都是为了满足 “封装: 不变性” – 也就是ACID中的C(consistency)。一次对象的操作,要么完成,要么不完成,要保证 对象始终处于正确的状态。
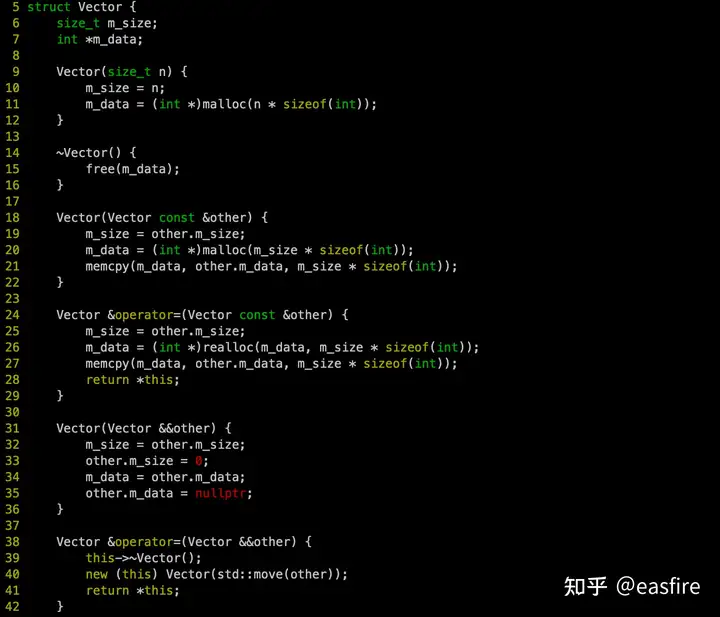
拷贝赋值函数
同理,如果使用了拷贝赋值,也需要定义拷贝赋值函数。

以上方式,先销毁,再通过 placement new,在原有this指针上构造。为了提高性能,推荐使用,realloc,从而就地利用现有m_data,避免重新分配。

m_data显然,本来就有一段内存,那么通过 realloc 可以方便在原有的指针地址上扩展内存,避免了一次销毁在分配操作。
移动构造函数 & 移动赋值函数

- std::move
调用 std::move,V1 接管了V2的这块内存的所有权。
而拷贝赋值的 复杂度为 O(n),因为分配了两块内存,v1 = v2 完成的是深拷贝。
以上两个操作,都不会产生二次free。
- std::swap
另外还有 通过 std::swap 完成两块内存内容的交换。

- 隐式发生 Move的情况
① return v2 // C++规定,return 的对象不会再使用,自然等价于 std::move 语义。
- 显式发生 拷贝的情况
① return std::as_const(v2) // 显式拷贝
② v1 = v2 // 默认拷贝

自定义移动构造、移动赋值,可以提高执行效率。

因为移动后,销毁了原对象,不存在两次free的情况,移动是浅移动。
unique_ptr
含义
对象释放,保证释放之前和之后,对象都处于正常状态。这样,不会出现 野指针(空悬指针)。
std::unique_ptr<C> p = std::make_unique<C>();在解构函数中,会自动调用 delete p 释放 p。对比 C++ 98 古老的释放对象的方法。
delete p; // 之后要设null,不然可能会被再利用。
p = nullptr;而 unique_ptr 只需要 即可提前释放对象。– 体现了封装:一致性。
p = nullptr; // 等价于 p.reset();浅拷贝问题
以下代码,unique_ptr 是删除了拷贝函数的,调用类的成员函数会报错。
struct C {
C() {
printf("%s\n", );
}
~C() {
printf("%s\n", );
}
void do_sth() {
printf();
}
};
void func(std::unique_ptr<C> p) { // 调用时,发生了浅拷贝
p->do_sth();
}
int main() {
std::unique_ptr<C> p = std::make_unique<C>();
func(p); //报错
return 0;
}因为 unique_ptr 删除了 拷贝构造函数,不能被拷贝。宁可编译器出错,不在运行时出错。按照三五法则,unique_ptr 自定义了解构函数,所以它必须删除拷贝构造函数。unique_ptr 采用的是上文提到的第一种方法,来避免 double free的情况。
- 那么如何解决这个问题,解决方法
可以这样修改,从 unique_ptr 获取 原始指针
- case 1
void func(C *p) {
p->do_sth();
}
int main() {
std::unique_ptr<C> p = std::make_unique<C>();
// 从p中 get出原始指针,并不是要夺取资源的占有权,只是调用p的成员函数,并没有接管对象生命周期。
func(p.get());
return 0;
}第一种情况,我们只是对 p做了一些事情,并不是需要获取p 的控制权,此时只需要指针的 get() 出一个原始指针,并没有修改它什么时候释放这件事。还可以这样,把 p 指针 move到全局变量。(不推荐)
- case 2
std::vector<std::unique_ptr<C>> objlist;
// 把指针放到一个全局列表,那么 p的生命周期将变得和 objlist一样长。所以需要接管p的生命周期。
void func(std::unique_ptr<C> p) {
objlist.push_back(std::move(p)); // 进一步移动到 objlist
}
int main() {
std::unique_ptr<C> p = std::make_unique<C>();
p.get(); // 不为空
func(std::move(p)); // 通过移动构造函数,转移指针控制器
p.get(); // 为空
return 0;
}但移交了p 的控制权,就不能再访问 p 这个地址了。如果还想对 移交后的指针p,调用成员函数等操作,可以这样操作(不推荐,都这样做了还用什么unique_ptr)
- case 3
int main() {
std::unique_ptr<C> p = std::make_unique<C>();
C *raw_p = p.get(); // 先把原始指针拷贝一份
func(std::move(p)); // 转移p 控制权给 objlist
// 但需要注意,要保证 raw_p的存在时间不能超过 p的生命周期,否则 会出现危险的空悬指针。
//objlist.clear();
raw_p->do_something();
return 0;
}
raw_p 返回错误值。报错分析如下图,

shared_ptr
含义
下面的例子说明了 shared_ptr 的使用特点,
#include <cstdio>
#include <memory>
#include <vector>
struct C {
int m_number;
C() {
printf("分配内存!\n");
m_number = 42;
}
~C() {
printf("释放内存!\n");
m_number = -2333333;
}
void do_something() {
printf("我的数字是 %d!\n", m_number);
}
};
std::vector<std::shared_ptr<C>> objlist;
void func(std::shared_ptr<C> p) {
objlist.push_back(std::move(p)); // 这里用移动可以更高效,但不必须
}
int main() {
std::shared_ptr<C> p = std::make_shared<C>(); // 引用计数初始化为1
func(p); // shared_ptr 允许拷贝!和当前指针共享所有权,引用计数加1
func(p); // 多次也没问题~ 多个 shared_ptr 会共享所有权,引用计数加1
p->do_something(); // 正常执行,p 指向的地址本来就没有改变
objlist.clear(); // 刚刚 p 移交给 func 的生命周期结束了!引用计数减2
p->do_something(); // 正常执行,因为引用计数还剩1,不会被释放
return 0; // 到这里最后一个引用 p 也被释放,p 指向的对象才终于释放
}unique_ptr 解决了重复释放的方式是禁止拷贝,这样虽然效率高,但导致使用困难,容易出错;
相比之下,牺牲效率换来自由度的 shared_ptr 允许拷贝,他解决重复释放的方式是通过引用计数;
1、当初始化一个 shared_ptr时,计数初始化为 1
2、shared_ptr 被拷贝一次,计数加 1
3、shared_ptr 被解构一次,计数减 1, 减到 0 则自动销毁他指向的对象,比如 main函数 return
从而保证要还有引用存在,就不会解构对象。
- 总结下 两种指针的特点,
1> unique_ptr 容易保证原子性,shared_ptr 需要硬件指令保证原子性,效率没有 unique_ptr 高;
2> shared_ptr 方便,但还有循环引用问题,接着往下看。
循环引用问题
- 一个 使用 shared_ptr 的 Bad Case
#include <memory>
struct C {
std::shared_ptr<C> m_child;
std::shared_ptr<C> m_parent;
};
int main() {
auto parent = std::make_shared<C>();
auto child = std::make_shared<C>();
// 建立相互引用
parent->m_child = child;
child->m_parent = parent;
parent = nullptr; // parent 不会被释放,child 还指向它
child = nullptr; // child 不会被释放,parent 还指向它
return 0; // 完了,直到main函数退出,这两块内存都没有被释放。
}上面实例的目的,通常 释放 parent时候,希望 child也同时被释放,但是因为产生了循环引用,导致内存泄漏。
总结一下:
动态指针 shared_ptr,可以适当减少使用者的出错概率,因为他的行为类似 GC语言的引用计数机制,但也有以下问题:
1、shared_ptr 需要维护一个 atomic 的引用计数器,效率会降低,需要额外维护一块管理内存,访问实际对象需要二级指针,而且 deleter 使用了类型擦除技术;
2、另外,全部使用 shared_ptr,可能会出现循环引用的问题,导致内存泄漏,那么要使用不影响计数的原始指针,或者 weak_ptr 来避免这个问题。
c语言有特定方法解决循环引用,c++需要改造如下: 使用 weak_ptr
weak_ptr
讲解 weak_ptr 概念
- case 1
std::vector<std::shared_ptr<C>> objlist;
void func(std::shared_ptr<C> p) {
objlist.push_back(std::move(p)); // 进一步移动到 objlist
}
int main() {
std::shared_ptr<C> p = std::make_shared<C>(); // 引用数初始化为 1
p.use_count(); // 1
std::weak_ptr<C> weak_p = p; // 创建一个不影响计数器的弱引用
p.use_count(); // 1
func(std::move(p)); // 控制权转移,p 变为 null, 引用计数不变!
if (weak_p.expired()) {
printf("%s\n", );
} else { // here
weak_p.lock()->do_sth(); // 正常执行,p 的生命周期仍然被 objlist 延续
}
objlist.clear(); // 刚刚 p移交给 objlist的生命周期结束,引用数-1 变0
if (weak_p.expired()) { // 因为 shared_ptr 指向的对象,已经释放,弱引用会失败。
printf("%s\n", ); // here
} else {
weak_p.lock()->do_sth(); // 不会执行到这.
}
return 0; // 这里最后一个弱引用 weak_p 也被释放,他指向的管理块 被释放。
}# 解决方案1
#include <memory>
struct C {
std::shared_ptr<C> m_child;
std::weak_ptr<C> m_parent;
};
int main() {
auto parent = std::make_shared<C>();
auto child = std::make_shared<C>();
// 建立相互引用
parent->m_child = child;
child->m_parent = parent;
parent = nullptr;
child = nullptr;
return 0;
}不影响 shared_ptr 计数,弱引用 weak_ptr
有时候,我们希望维护一个 shared_ptr 的弱引用 weak_ptr, 即 弱引用的拷贝与 解构不影响其引用计数器。
之后,有需要时,可以再通过 lock() 随时产生一个新的 shared_ptr 作为强引用,但不lock的时候,不影响计数。
lock(): creates a shared_ptr that manages the referenced object
如果失效了(计数器归零), 则 expired() 会返回 true,并且 lock() 会返回nullptr
可以把 C * 理解为 unique_ptr 的弱引用,weak_ptr 理解为 shared_ptr 的弱引用。但 weak_ptr 能提供 失效检测,更安全。
shared_ptr 管理的对象生命周期,取决于所有引用中,最长寿的哪一个;
unique_ptr 管理的对象生命周期长度,取决于他所属的唯一一个引用的寿命。
# 智能指针 做为类的成员变量
可以在类中使用智能指针作为成员变量,需要根据所有权情况,判断使用哪一种智能指针
1、unique_ptr: 当该对象仅仅属于我时,比如 父对象中指向子对象的指针;
2、原始指针: 当该对象不属于我,但他释放前,我必然被释放。比如:子对象中指向父对象的指针;– unique_ptr 和 原始指针 一起使用。
3、shared_ptr: 当该对象由多个对象共享,或虽然该对象仅属于我,但有使用weak_ptr的需要
4、weak_ptr: 当该对象不属于我,且他释放后,我仍可能不被释放时。比如:指向窗口中上一次被点击的元素。
5、shared_ptr 和 weak_ptr 一起使用。即使 weak_ptr 指向的原指针已失效, expired可以判断出,而不会造成报错。这一点,强于原始指针对 unique_ptr 的弱引用。
综上 ,初学者 更推荐 shared_ptr 和 weak_ptr的组合,而不是 unique_ptr 和 原始指针的组合。
# 解决方案2
#include <memory>
struct C {
std::unique_ptr<C> m_child;
C *m_parent;
};
int main() {
auto parent = std::make_unique<C>();
auto child = std::make_unique<C>();
// 建立相互引用:
parent->m_child = std::move(child); // 移交 child 的所属权给 parent
child->m_parent = parent.get();
parent = nullptr; // parent 会被释放。因为 child 指向他的是原始指针
// 此时 child 也已经被释放了,因为 child 完全隶属于 parent
return 0;
}刚才提到的 unique_ptr 的应用场景,“当该对象仅仅属于我时”。既然都是用了原始指针(假设它释放前我必然被释放),因而我们完全可以把 m_child 变成一个标志着 “完全所有权”的 unique_ptr 。
这样 也不需要, shared_ptr 维护原子计数器的开销。
C++ 中所有的拷贝都是深拷贝,除了 shared_ptr 和 weak_ptr 是浅拷贝,而 unique_ptr 禁止拷贝。
三五法则
安全和不安全的类型
① 以下类型是安全的:
- int id; // 基础类型
- std::vector
arr; // STL容器 自动调用 vector的深拷贝 - std::shared_ptr
- Object *parent; // 原始指针,前提是从 unique_ptr里 .get() 出来的弱引用,才是合理的
② 以下对象时不安全的:
- char *ptr; // 原始指针,如果是通过 malloc/free 或者 new/delete 分配的, 需要自己去删除拷贝,或者定义拷贝。
- GLint tex; // 是基础类型 int,但对应的某种资源。实际和 malloc/free函数一样是分配释放资源函数。
- std::vector<Object *> obj; // STL容器,但存储了不安全的对象。 最好,通过深拷贝,或者禁止拷贝来避免 double free 的问题。
那么什么样的类定义是安全的呢
- 如果你的类所有成员,都是安全类型。那么五大函数都不需要声明 (或声明为 = default),你的类自动就是安全的;
那么举一个安全的结构体定义
struct Mesh {
// points
std::vector<math::vec3f> vert;
// corners
std::vector<uint32_t> loop;
std::vector<math::vec2f> loop_uv;
// faces
std::vector<uint32_t> poly;
};- 最好的判断方式,如果你不需自定义解构函数,便可不担心安全问题,因为通常自定义解构函数,意味着你的类成员里,包含不安全的类型。
管理资源的类,先删除它的拷贝构造和拷贝赋值函数。
Shader(Shader const &) = delete;
Shader &operator=(Shader const &) = delete;既然,标准库已经提供了 shared_ptr,直接用 shared_ptr
对于数据结构
如果可以(它的构造函数使用 malloc()),自己定义拷贝和移动函数。
如何避免不必要的拷贝:常引用
函数的参数声明为值类型,此时,实际调用了类的拷贝构造函数。产生了一次不必要的拷贝。那么替换成 const &,常引用,从而传递了一个指针,避免了拷贝。
函数参数类型优化规则: 按引用还是按值?
① 如果参数是基础类型(int、float) 则按值传递;
float squareRoot(float val);
② 如果是原始指针(int*、Object*)则按值传递;
void doSomethingWith(Object *ptr);
③ 如果是 容器类型(vector、string)则按常引用传递;
int sumArray(std::vector const &arr);
④ 如果容器不大 (tuple)按值传递;
glm::vec3 calculate(glm::vec3 pos);
⑤ 如果智能指针(shared_ptr)且需要生命周期控制权,则按值传递;用户自己调用 std::move()
void addObject(std::shared_ptr - 只有数据容器、自定义的可拷贝的类,使用常引用的方法。
避免不必要的隐式拷贝
我们 可以将拷贝构造函数声明为 explicit (明确的),这样隐式拷贝会出错,从而发现不必要的拷贝。
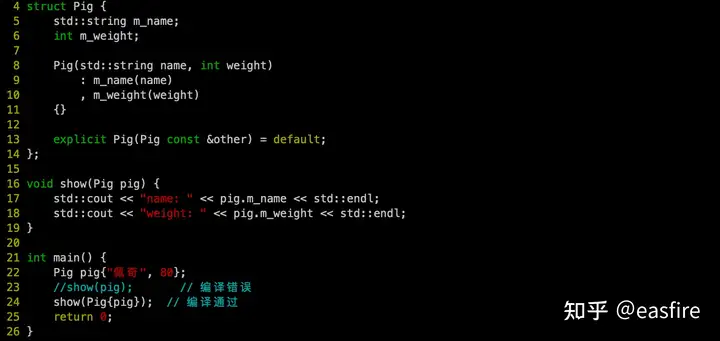
语言管理资源
为什么很多面向对象的语言,比如Java,都没有构造函数全家桶的概念呢?
- 因为,他们的业务需求大都是面向资源的,比如操作数据库,发送http请求等等。
- 这些业务往往都是和“资源”在打交道,从而,基本上都是删除了拷贝函数的那一类,解决这类需求,几乎总是在用 shared_ptr
的模式,于是 Java和Python 干脆简化:一切非基础类型的对象都是 浅拷贝,使用引用计数,同时再通过 垃圾回收机制 自动管理。
因此,以系统级编程、算法数据结构、高性能计算 为主要业务的C++,才发展出了这些思想,并将 拷贝、移动、指针、可变性、多线程 等概念作为 语言基础元素 而存在。这些在我们的业务中非常重要,所以不可替代。
扩展关键词
1、P-IMPL 的模式
2、虚函数和纯虚函数
3、拷贝如何作为虚函数
4、std::unique_ptr::release()
5、std::enable_shared_from_this
6、dynamic_cast
7、std::dynamic_pointer_cast
8、运算符重载
9、右值引用 &&
10、std::shared_ptr

