第一章-概述
计算机病毒的定义
编制或者在计算机程序中插入的破坏计算机功能或者毁坏数据,影响计算机使用,并能自我复制的一组计算机指令或者程序代码。
计算机病毒的本质属性
人为的特制程序是任何计算机病毒的固有本质属性
程序性的客观性决定了计算机病毒的可防治性和可清除性
人为性的主观性导致计算机病毒各异多变
基本特征-传染性
传染性是判别一个程序是否为计算机病毒的首要条件,传染性也即指计算机病毒把自身复制到其他程序的能力,把自身的代码强行传染到一切符合其传染条件的程序之上
基本特征-隐蔽性
传染过程与存在的隐蔽性,用户不知道病毒的存在
基本特征-可触发性
因某个事件或数值的出现,触发病毒实施感染或攻击破坏即隐藏又保持破坏力
其他特征
- 欺骗性:欺骗用户触发、激活病毒
- 非授权性:窃取系统控制权
- 寄生性:依附于宿主程序
- 衍生性:病毒变种
- 持久性:数据恢复困难、病毒清除困难
- 破坏性:数据破坏、计算机功能破坏、经济损失
- 针对性:特定软件、操作系统、硬件平台(也反映了其程序性的客观事实)
- 不可预见性:对未知病毒的预测难度(反病毒软件预防措施和技术手段往往滞后于病毒产生速度)
病毒的分类


恶意程序
未经授权便干扰或破坏计算机系统/网络的程序或代码,早期恶意代码的主要形式是计算机病毒
蠕虫
独立的可执行程序,不需要寄生在宿主程序中,通过网络分发自己的副本
病毒与蠕虫的区别:
| 病 毒 | 蠕 虫 | |
|---|---|---|
| 存在形式 | 寄生 | 独立个体 |
| 复制机制 | 插入到宿主程序(文件)中 | 自身的拷贝 |
| 传染机制 | 宿主程序运行 | 系统存在漏洞(Vulnerability) |
| 搜索机制(传染目标) | 主要是针对本地文件 | 主要针对网络上的其它计算机 |
| 触发传染 | 计算机使用者 | 程序自身 |
| 影响重点 | 文件系统 | 网络性能、系统性能 |
| 计算机使用者角色 | 病毒传播中的关键环节 | 无关 |
| 防治措施 | 从宿主程序中摘除 | 为系统打补丁(Patch) |
特洛伊木马
在远程计算机之间建立连接,使得远程计算机能通过网络控制本地计算机的非法程序。
木马系统软件一般由木马配置程序、控制程序和木马程序(服务端)三部分组成,其入侵的方式与一般病毒存在区别,而且,自身一般没有传染性。
计算机病毒的危害
计算机病毒的蓄意破坏:来自于病毒制造者目的,对数据信息的直接破坏
计算机病毒的偶然性破坏:自身错误与不可预见性、兼容性
计算机病毒的附带性破坏:抢占资源、影响计算机运行
计算机病毒造成的心理及社会的危害:声誉损失 、商业风险、心理反应
计算机病毒的传播途径
通过不可移动的计算机硬件设备进行传播
通过移动存储设备来传播
通过有线网络系统进行传播
通过无线通讯系统传播
计算机病毒的生命周期
计算机病毒的产生过程可分为:
程序设计→传播→潜伏→触发、运行→实施攻击
计算机病毒的生命周期:生成开始到完全根治
- 开发期:较短、没有经过严格的测试
- 传染期:感染流行程序,网络共享,被动到主动
- 潜伏期:静态潜伏(文件拷贝)和动态潜伏(占据内存)
- 发作期:触发,实施破坏,取决于编写者意图和编程技术
- 发现期:被检测隔离,反病毒厂家,病毒通报和描述
- 消化期:反病毒软件,检测和发现病毒
- 消亡期:升级杀毒软件,杀毒
计算机病毒的产生是必然的,软硬件脆弱性是根本原因,计算机普及 是必要环境。
第二章-代码初始
小端机:最低字节放在内存的最低地址,次低字节放内存的次低地址,依次存放。比如,0x12345678放在内存中就是78 56 34 12(最左边为内存低位)
大端机:0x12345678放在内存中就是12 34 56 78
病毒的基本能力和执行特点
- 执行(最为重要)
- 潜伏
- 破坏
- 传染
执行的特点:
病毒执行并非简单执行自己的指令,它还需要执行被感染对象正常的指令,否则无法潜伏。简单说,在正常指令执行时,需要修改执行流程获得一个执行病毒指令的能力
JMP指令解析
地址1 Jmp offset -> Offset=地址3-地址2
地址2 Push eas
...
地址3 Mov xxxJMP跳转的偏移量是:目的地址-JMP的下一条指令地址,同时JMP跳转指令占1个字节,偏移量4个字节,一共5个字节
第三章-文件系统
硬盘的物理结构
初级格式化的主要目的:划分成磁道、扇区和柱面
CHS参数:磁道/盘片/扇区
INT 13H:寻址范围为8GB
文件系统
文件系统就是组织文件的一种方式,文件管理包括文件生成,删除,目录查询等。下面介绍的FAT12主要用来管理软盘

1个FAT有9个扇区,引导扇区1个扇区,根目录区有224条记录(一个记录32字节)
- 数据区中存放用户数据,是文件和子目录数据真正存放的区域
- 根目录区中存放的是文件目录表,为记录根目录文件项的表,文件项包括文件,目录。通过它可以查找到根目录下的文件和目录信息,比名称,大小,日期等
- FAT12为文件分配表(FAT(File Allocation Table)):记录已分配的扇区和可用扇区,并通过链表依序记录一个文件占用的扇区,另外一个FAT12为备用的FAT表
- 引导扇区(DBR (DOS Boot Record)):记录磁盘和文件系统相关的各种参数,比如扇区大小,一簇的扇区数等
引导记录格式
| 名称 | 偏移 | 长度 | 内容 | 软盘参考值 |
|---|---|---|---|---|
| BS_jmpBoot | 0 | 3 | jmp LABEL_START nop | |
| BS_OEMName | 3 | 8 | 厂商名 | ‘ForrestY’ |
| BPB_BytsPerSec | 11 | 2 | 每扇区字节数 | 0x200(即十进制512) |
| BPB_SecPerClus | 13 | 1 | 每簇扇区数 | 0x01 |
| BPB_RsvdSecCnt | 14 | 2 | Boot记录占用多少扇区 | 0x01 |
| BPB_NumFATs | 16 | 1 | 共有多少FAT表 | 0x02 |
| BPB_RootEntCnt | 17 | 2 | 根目录文件数最大值 | 0xE0 (224) |
| BPB_TotSec16 | 19 | 2 | 扇区总数 | 0xB40(2880) |
| BPB_Media | 21 | 1 | 介质描述符 | 0xF0 |
| BPB_FATSz16 | 22 | 2 | 每FAT扇区数 | 0x09 |
| BPB_SecPerTrk | 24 | 2 | 每磁道扇区数 | 0x12 |
| BPB_NumHeads | 26 | 2 | 磁头数 | 0x02 |
|---|---|---|---|---|
| BPB_HiddSec | 28 | 4 | 隐藏扇区数 | 0 |
| BPB_TotSec32 | 32 | 4 | 如果BPB_TotSec16是0,由这个值记录扇区数 | 0xB40(2880) |
| BS_DrvNum | 36 | 1 | 中断13的驱动器号 | 0 |
| BS_Reserved1 | 37 | 1 | 未使用 | 0 |
| BS_BootSig | 38 | 1 | 扩展引导标记 | 0x29 |
| BS_VolD | 39 | 4 | 卷序列号 | 0 |
| BS_VolLab | 43 | 11 | 卷标 | ‘OrangeS0.02’ |
| BS_FileSysType | 54 | 8 | 文件系统类型 | ‘FAT12’ |
| 引导代码 | 62 | 448 | 引导代码、数据及其他填充字符等 | |
| 结束标志 | 510 | 2 | 0xAA55 |
从开始偏移510个字节处有两个字节55 AA代表是引导区,小端机整数表示是0xAA 55
注意到有BS_jmpBoot这个引导记录最开始的JMP指令,反汇编后的机械码为EB 3C 90,机器码EB表示JMP,后面1个字节是偏移量,偏移是指从JMP的后条指令开始,到转跳到的指令的差。这里EB 3C表示偏移为60字节(3CH),例如:JMP指令写入内存的地址是0x4011F0,验证一下:0x4011F0 + 2(JMP长2) + 3C= 0x40122E
如何定位一个文件
文件分配的最小单位是簇,哪怕只有一个字节也会分配一簇,簇由几个扇区组成在引导扇区的引导记录中定义。在FAT12文件系统中,FAT表以3个半字节(3*0.5 Byte = 1.5 Byte = 12 bit)来记录一个簇的相关情况,这也是“FAT12“文件系统中命名12的原因。
FAT表的本质是磁盘簇分配情况的数据表示,FAT表中每3个半字节为一个元素,这个元素就代表一个簇,簇号从0开始,这个元素中存放的整数值表示其链接的下一簇的簇号
查找和遍历
类似于链表的查找,以FFF为结尾,FAT12默认设置引导区占一个扇区,FAT1于其后,同时FAT表开始的3个字节没用于用户文件分配,3字节有2组12bits所以,占用了0,1两个簇号,用户的数据从簇2开始分配。
随后FAT表从头开始按3字节分成一组,但是有一点需要特别注意:
在这3个字节中,用第2字节的低半字节和第1字节形成整数表示一个簇号,用第2字节的高半字节和第3字节形成的整数来表示另一个簇号
由上面学习的内容知道,在FAT表中想要开始遍历就必须知道首簇号,而首簇号位于根目录区域中。
根目录表中的记录格式
根目录表包含多条记录,每条记录占32字节,其结构如下表所示。目前我们关注文件名(查找需要)和首簇(遍历需要)
| 名称 | 偏移 | 长度 | 描述 |
|---|---|---|---|
| DIR_Name | 0 | 0xB (11) | 文件名8字节,扩展名3字节 |
| DIR_Attr | 0xB | 1 | 文件属性 |
| 保留 | 0xC | 10 | |
| DIR_WrtTime | 0x16 | 2 | 最后修改时间 |
| DIR_WrtDate | 0x18 | 2 | 最后修改日期 |
| DIR_FstClus | 0x1A (26) | 2 | 此条目对应的开始簇号 |
| DIR_FileSize | 0x1C (28) | 4 | 文件大小 |
文件名字段,在该记录首部偏移0开始,共11字节,其中8个给文件名,3个给扩展名(不需要记录点号 “.”)
名字的结束以空格表示,即0x20
查找根目录表的算法
从磁盘0头0道1扇区读出引导区(Boot)512字节,从其中引导记录获取相关信息:Boot区占用扇区数,FAT表数目,每个FAT表的扇区数,1个扇区的字节数。
计算根目录区的起始位置为:
[ 1(Boot区扇区数)+2(FAT数目)*9(FAT扇区数)] * 512 = 0x2600
即2600h为根目录区起始位置,从引导记录获取根区记录数,缺省224条,按每条记录32字节读出所有记录。每条记录开始11个字节为文件名,比较文件名匹配则找到记录,从首簇字段(从该记录开始偏移1Ah处)获得首簇号。
系统如何区分卷标项和文件项
| 名称 | 偏移 | 长度 | 描述 |
|---|---|---|---|
| DIR_Attr | 0xB | 1 | 文件属性 |
| DIR_FstClus | 0x1A (26) | 2 | 此条目对应的开始簇号 |
每一条记录,从该记录开始偏移0xB处有个字节指示出文件的类型,对于多级目录来说,则是存放在数据区内,原理和根目录查找目录类似,只不过是多层嵌套,查找到的是另一个目录表。
查找a:\tem\tem.txt

总结文件查找算法
STEP1. 根据文件路径的第一项(1),先查看根目录表 ,是否有匹配的项,如果有,通过对应项的首簇段(0x1A) 获取该子目录表(1) 的首簇号
STEP2. 通过首簇号和FAT表获得子目录表(1) 的全部内容,根据文件路径的第二项(2),遍历子目录表(1),一次偏移32字节用名字匹配 的方法查找记录项(2), 如果找到,则类似STEP1和STEP2继续查找文件路径中的下一项 ,否则说明找不到,结束
如果在最后一层目录表(路径的倒数第二项,最后一项是文件名)中找到了被查文件的项,从中获取首簇号,即可通过FAT表访问该文件整个相关簇
第四章-硬盘数据结构
学习完之前有关文件的管理之后,学习有关硬盘的分区信息。
主引导扇区
- 主引导记录(Master Boot Record, MBR)446字节为主引导记录
- 分区表( Disk Partition Table, DPT)后面存放了一个分区表
相对扇区数,是相对于引导记录头部的偏移扇区数
主引导扇区中有主引导记录(其中存放了启动时的引导代码),分区表项, 如何根据分区表项定位到分区入口, 对于放在硬盘头部的MBR和拓展分区与EBR中的计算有所不同.
分区表项的第一个字节表示是否被激活。

扩展分区
虚拟扩展分区(Extended MBR,即EBR)的目的是为了增加更多的分区,核心想法是形成一个分区链,如图所示的分区中,MBR定义的主分区表本来有4条分区记录,用第一条描述自己分区的信息,用第2条指向下一个分区。下一分区也如此处理,形成链。
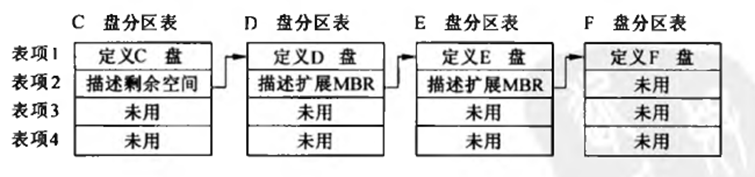
扩展分区的引导记录没有内容,而主分区开始之前有MBR和保留扇区,主分区的相对扇区相对于MBR,通过MBR和相对扇区就可以定位每一个主分区
注意:
为了完全兼容MBR的格式,EBR完全复用了引导扇区的格式,即起始446字节给引导记录EBR,但在EBR中,这些内容全为0。同样的,从446偏移开始为分区表,16字节为一项,共4项,后两条无效(但占空间),EBR定义的扇区最后两字节也是结束标识55 AA。主分区表中最后一个有效主分区记录指向的磁盘空间(也叫主扩展分区)将用EBR进行划分,分成N个逻辑盘,形成EBR链。

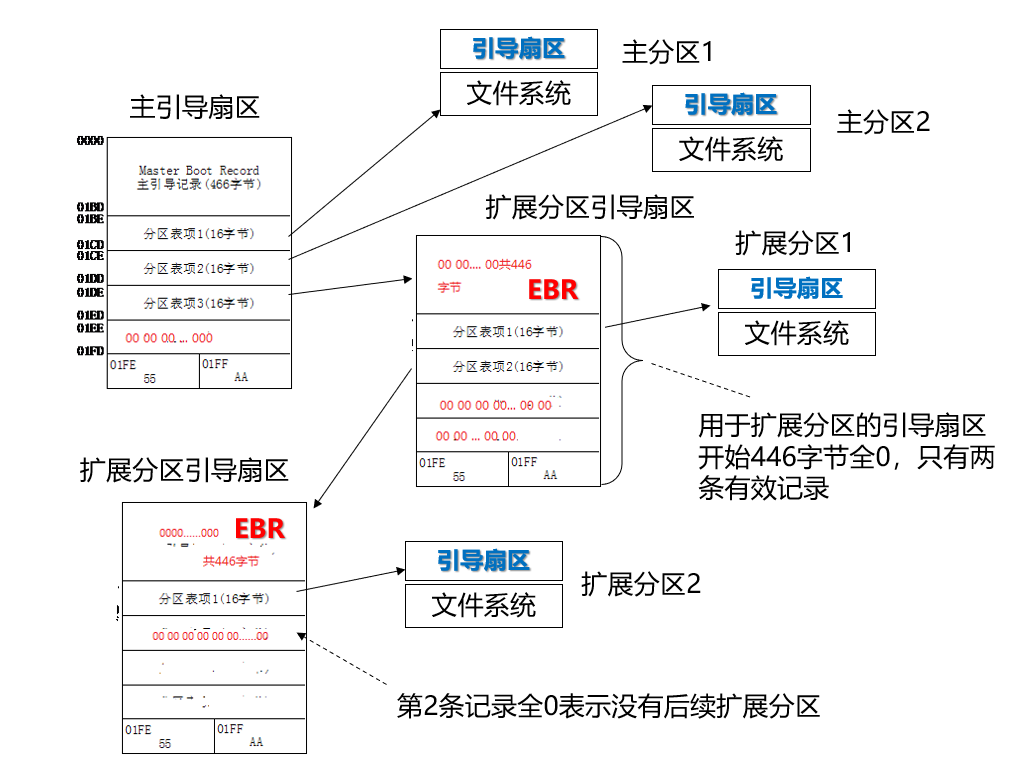
在实际中,则像下图一样:
主分区表项的偏移量,就是相对物理盘开始(MBR)的偏移,且这些主分区前面没有EBR,根据偏移得到的直接就是盘区(开始就是该分区的引导扇区和文件系统),除了主分区表项中的最后一项偏移指向的是扩展分区的开始处
扩展分区表项的偏移量,是相对于包含该分区表的扩展区开始处而言(扩展分区开始处为其EBR)
在扩展分区的分区表中,第一项的偏移指向的是盘区,第二项的偏移指向的是下一个扩展分区开始处(也就是下一个扩展分区的EBR)
硬盘的引导过程
开机加电自检:开机,CPU跳到内存FFFF:0000处,由该处的一条JMP指令跳到BIOS的自检程序(POST),自检通过后,加载引导程序(与操作系统无关的MBR,按用户在BIOS中的指定顺序,硬盘、软盘、光驱或U盘等
读主引导扇区:将主引导扇区MBR读入到内存的0000:7C00,扫描主分区表,搜索激活分区,分区表项第一个字节为0x80表示激活分区
读激活分区引导扇区 :如果有多个激活分区或没有,报错结束。否则读取激活分区引导扇区到0000:7c00
操作系统引导代码引导系统并读取操作系统初始化文件
注意的是MBR中硬盘数据结构是与操作系统无关,操作系统相关的引导代码在激活分区的引导扇区,而MBR的引导程序选择激活分区。
第五章-Dos下的病毒寄生
病毒的关键问题
- 寄生,没有寄生就没有执行和传播的可能
- 执行,如果只是文件,没有得以执行的机会,则永远都无法去破坏和感染
- 反检查,包括隐藏病毒等
寄生机制与执行机制
文件型病毒
- 头插入
- 尾插入
- 逆插入
直接面向文件系统的病毒
- 引导型病毒
执行机制
- 对于com文件,头、尾和逆插入寄生都相当于入口点修改,病毒可以执行,就不做另行说明
- 中断替换
DOS下的内存
保护模式带来的最大优点不是单纯的扩大了内存寻址范围,而是对内存寻址从机制上提供了保护,将系统的执行空间按权限进行了划分,防止应用程序非法访问其他应用程序的地址空间(任务间保护),防止应用程序非法访问操作系统地址空间(系统保护)。
DOS下四种基本可执行文件
- 批处理文件,以.BAT结尾的文件
- 设备驱动文件,是以.SYS结尾的文件,如CONFIG.SYS
- COM文件,是以.COM结尾的纯代码文件。没有文件头部分,缺省情况下总是从0x100H处开始执行,没有重定位项,所有代码和数据必须控制在64K以内
- EXE文件,是以.EXE结尾的文件。文件以英文字母“MZ”开头,有一个文件头,用来指出每个段的定义等信息,EXE文件摆脱了代码大小最多不能超过64K的限制
COM文件
COM文件不存在文件头,由机器码和数据的集合组成,COM文件就是直接读到内存,文件会被加载器加载到段内位置。
头插入
头插入病毒是三种病毒之中比较直接的方式
选择直接插入的话需要注意的是一般函数调用完成后会有ret指令,将执行权交还给DOS,因此后续的代码没有执行就返回了。需要通过JMP指令跳转,不能够直接将RET指令去除,去除的话就将程序段和数据段混合,同时需要注意跳转指令的地址。
源码中的地址信息在编译后会直接被预加载地址代替,从而形成可执行文件的机器码。但因为病毒感染占据了原先com文件的头部,所以原来的机器码后移了这个改动加载器是完全不知道的,它只会把文件加载到预先处,从而导致原先部分的机器码在加载后的实际内存位置后移了,后移长度就是病毒程序的机器码长度
解决方案
纠正这个问题一般依靠重定位,但COM文件只是简单地被加载到段内原先位置处,本身是没有重定位需要的相关机制,且我们想通过编程来更正错误的地址也是不太可能的。解决方法其实很简单,将原先挤占的程序挪回去原先的位置,
要拷贝原来的正常程序需要知道它的大小,采取手动的方法,在病毒程序的最后加上两字节的数据存储正常程序的大小,生成感染文件后再在该两字节的位置填入正常程序的大小。
需要注意的是,如果被拷贝文件过大,会存在覆盖的问题:拷贝指令本身所在的内存部分就是被覆盖的部分。当某次拷贝覆盖了拷贝指令所占的那个字节时,拷贝指令本身就被破坏了,当然它就不能再完成拷贝。那么如何解决这个问题?
必须让病毒的执行指令本身不会在原文件的拷贝过程中被自我覆盖,最好的方法就是把这些指令放到一个肯定不会被覆盖的安全区域哪里是安全的区域,这里,我们可以选择感染程序最后面的内存区域,也就是原先程序段之外的位置。
尾部寄生
在正常代码头部,将原先正常的头部代码修改为jmp覆盖的字节,然后将病毒代码放到正常代码之后,同时注意将被覆盖的正常代码放在病毒代码的后面,确保先执行病毒代码再执行jmp覆盖的字节。但同样具有加载偏差的问题,因此需要使用重定位技术。
只需要获得任意一条指令的加载偏差就可以知道整个程序的实际偏差地址,也就是将运行时的地址值和编译时的地址值相减就行了,因此关键在于获得IP指向指令的地址值。获取IP寄存器的地址有一个技巧:
Call指令会将下一条指令的IP压栈!然后再跳转执行
call here <-Call指令的下一条指令是pop ax,call执行时,首先会把pop ax指令的IP(即pop ax这条指令的实际地址)压栈,然后根据相对偏移跳到标号here处 here: pop ax <-标号here处就是pop ax指令,执行这条出栈指令会把栈中数据放入ax中,也就是pop ax指令的IP,我们巧妙地利用栈获得了IP的值 sub ax, here <-Sub语句中的标号here在编译时就生成了地址,但是是预期地址,实际地址-预期地址,ax中放的就是加载偏差了
计算出pop的实际地址和预期地址here的差。这样只要将编译期要用的的地址,比如字串的首址加上ax就是字串实际地址了。
JMP指令长度和格式
因为JMP要覆盖头部,所以必须分配对应长度的空间在病毒的数据区,用以保存覆盖的内容,在DOS中JMP 地址指令只有两个字节,如果偏移量过长的话则有多个字节,DOS下一般为小端机顺序。
流程
- 构造一个打印的正常程序normal.com
- 构造一个将粘贴到normal尾部的病毒程序endvirus.com
- 用DOS的拷贝命令:用
copy /b normal.com + virus.com infected.com完成手动感染, 将两个编译好的程序粘起来,手动完成寄生 - 将normal开始的3字节保存到virus.com的数据部分,用UE将normal开始的3字节手动修改为跳转指令,该JMP的机器码格式是E9 XX XX,其中XX XX是2字节,代表偏移这条手动插入的JMP将跳到virus.com处。偏移量如何计算?就是normal.com的size – 3,其中3是因为偏移量从JMP下一条指令开始算,JMP是3字节,所以减3
- virus.com部分指令执行后,将恢复程序开始被覆盖的3字节,还原现场,并JMP到程序开始,将执行权限交给normal.com部分
手动完成的工作
- 寄生感染
用copy /b normal.com + virus.com infected.com完成手动感染
- 填写OverridedCode字段,保存将被覆盖的头3字节
用UE打开Infected.com
将文件头3个字节内容填入文件倒数第5个字节开始处
- 填写InfectedFileSize字段,保存被感染文件本身的大小
查看normal.com文件大小为26字节,即0x001A,该值应该保存到最后两字节,根据小端机原理,我们将倒数第2个字节(InfectedFileSize)修改为0x1A
- 修改第一条JMP指令
normal.com有26字节,第一条JMP指令自身占3字节,那么跳到virus部分的偏移量是26-3=23,即0x17,那么第一条JMP指令为E9 17 00,修改程序头部3字节为E9 17 00
小结
自定位是针对病毒本身出现了加载偏差,而解决原文件加载偏差时,我们是将原文件通过拷贝回预加载地址来解决的。
逆插入感染
逆插入感染,实际就是一部分病毒代码在原程序的头部,一部分在尾部,将整个原来的程序给包裹起来。因为即在病毒头部也在病毒尾部,因此需要将程序后移,头粘贴尾粘贴都要使用到。

与之前手工设计不同的是,需要将感染寄生的代码放在病毒代码中,这段完成感染寄生的代码需要完成:
- 把正常程序向后拷贝头病毒的长度
- 把头病毒部分拷贝到前面
- 把尾病毒部分拷贝到后面
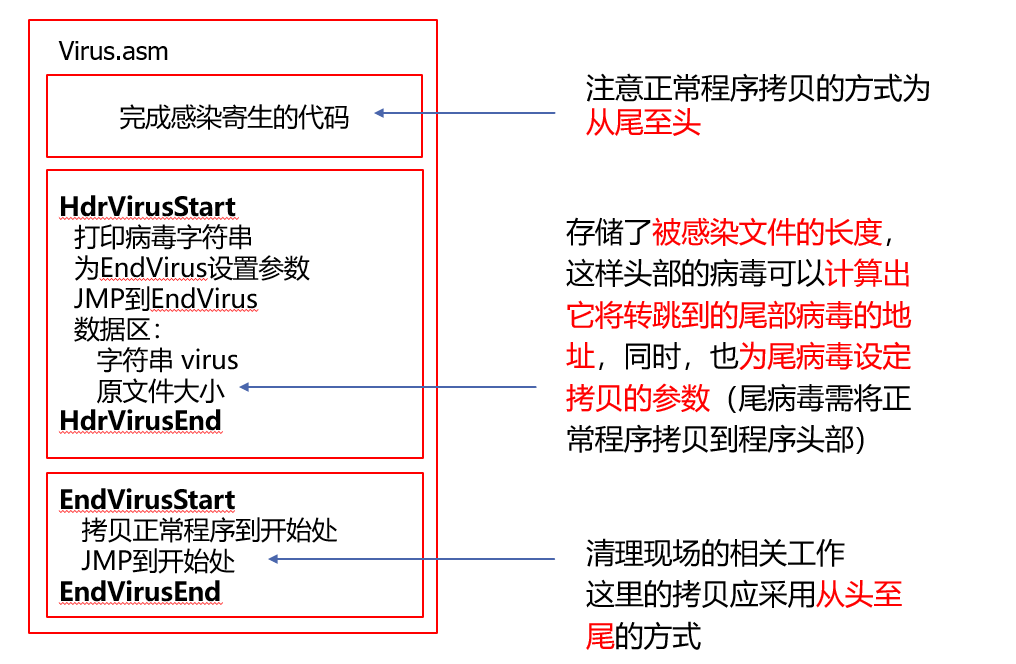
感染代码部分
(1)获取原文件大小供后面写入使用
(2)原文件扩容,增加头病毒部分长度的字节,在原文件的尾部写字节完成
(3)原文件向后拷贝头病毒长度部分长度,腾出头部的空间给头病毒,同时要从尾部到头部拷贝,不然会有数据覆盖。
(4)将头病毒部分写入头部
(5)将尾病毒部分写入尾部,直接写即可
头病毒部分
头病毒部分因为存在加载偏差,需要重定位,并且需要为尾病毒拷贝设置参数.
尾病毒部分
重定位有关的代码在头病毒部分已经设置完成,因此不需要额外设置.
第六章-函数调用
栈(Stack)是一种用来存储函数调用时的临时信息的结构,如函数调用所传递的参数、函数的返回地址、函数的局部变量等。在程序运行时由编译器在需要的时候分配,在不需要的时候自动清除。
函数调用对栈的影响
首先把指令寄存器EIP(它指向当前CPU将要运行的下一条指令的地址)中的内容压入栈,作为程序的返回地址(一般用RET表示);
之后放入栈的是基址寄存器EBP(保持之前的值,调用后恢复);
然后把EBP设为栈顶指针ESP,作为新的基地址;
最后为动态存储分配留出一定空间,即把ESP减去一个适当的数值
调用函数时,CALL指令干了两件事情,一件事情是将返回地址入栈,另外一件事情是JMP跳转至调用被函数. 在使用call指令前,需要将实参入栈。
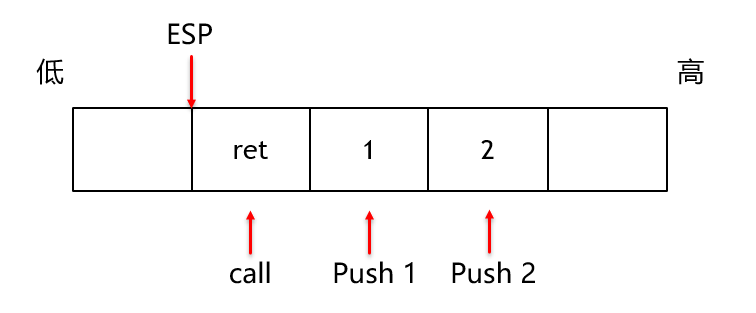
栈的顶部地址存放在ESP寄存器中,而栈的大小变化是以4字节为单位(32位机),因此我们只需要做如下计算就可以访问存储参数2的栈单元,例如 mov eax, [esp + cell*4]。但是之后的函数体如果使用了局部变量进行压栈,那么就无法正确访问参数。因此才需要在call之后先把EBP中的内容压栈,ESP放入到EBP中,此时EBP和ESP同样都是指向原EBP的位置。
小结
只要在一个函数的开始部分执行:
push ebp;
mov ebp, esp;之后相对ebp 进行正向偏移就可以访问它的主调函数传入的参数了
局部变量的访问
栈布局如之前图所示,因此局部变量分配在哪,如何访问?因为栈是由高地址向低地址增长,因此如何低地址部分就为局部变量的存储位置,与访问实参相同,都是通过ebp偏移访问。
可以简单记作:在使用了EBP寻址的函数中,EBP+偏移量就是参数的地址,EBP-偏移量就是局部变量的地址
函数返回
通过调用ret指令,将当前栈顶存放的内容作为返回的地址,而call的时候,就将返回地址存入栈了。
而被调函数的ret语句进行了如下操作:
将返回地址从栈中弹出,并放入EIP寄存器。所以每个被调函数的结尾处都是一句ret,这是函数的返回地址,那么函数返回值如何传递?首先调用ret后,EBP已经还原,对于局部变量来说无法通过EBP-偏移量来访问。
对于被调函数来说,则是将局部变量放入eax或者edx这种通用寄存器中,而对于调用者来说,则是把对应通用寄存器中的值放入到其对应的局部变量中。
对于返回值过多或者过大(如结构体)寄存器无法存储怎么办?解决办法即传地址即可。但是需要注意的是,如果EAX存了返回值,那么调用结束后进行请栈,EAX中存储的地址在逻辑上已经无效了。因此需要分配一段内存来存储这个返回值。这段空间就是在主调函数call背调函数之前完成。

然后,当被调函数传递返回值时:
(1)通过[EBP+偏移]获得这个返回值的存放位置
(2)把返回值写入到这个内存
(3)把返回值的地址写入到EAX,mov eax, [ebp+偏移]

栈清除
平衡栈,函数返回需要清除参数传递消耗的栈空间,参数传递使用了栈空间,那么函数完成了工作就不需要这些空间了,必须清除。清除栈上的空间很简单,只需要将ESP寄存器向反方向移动就可以了。清栈的工作可以由被调函数完成,也可以由主调函数清除。
栈溢出
即分配的临时变量空间不足以容下临时变量,导致覆盖了堆栈的高位元素,EBP,RET这些指令和数据被覆盖,将溢出的数据视为了指令,出现了错误。
第七章-DOS下的引导+中断
接下来学习面向文件系统的病毒:
引导型病毒
引导型病毒感染引导区,替换引导区原始的引导代码,从而获得执行。之后还原被修改的引导区,并将执行权限交给原来的引导代码,从而保持正常的工作。
接下来学习的引导型病毒是面向软盘上引导区的,软盘和硬盘所不同的是,硬盘分区(激活分区)的起始位置需要访问所对应的分区表项,找到分区表项,才能知道自己分区从哪里开始等信息,随后才能找到引导扇区的引导代码
设计
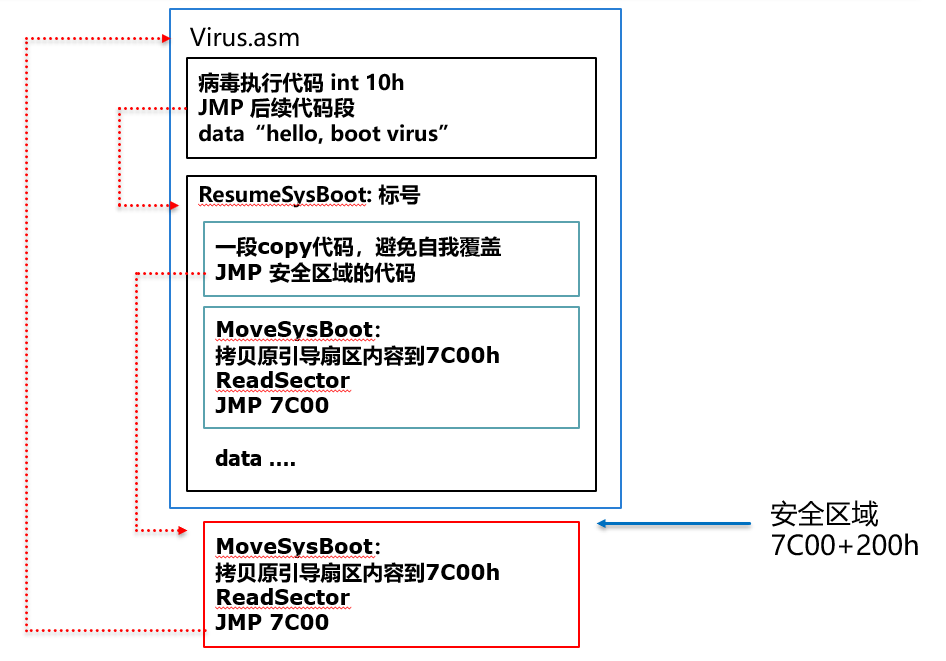
病毒感染时替换0头0道1扇区(512个字节),并将原引导扇区内容保存到用户数据区第一个扇区,也即簇2。病毒执行完打印字串的动作后,从簇2对应扇区读出原引导扇区内容,将其恢复到内存7c00h处,并跳到7c00h将执行权限交给原来的引导程序
插入被感染软盘,启动虚拟机设置为软盘引导,将先打印病毒的消息,然后进入原来的引导程序(原引导程序将打印非系统盘)
细节
执行过程:病毒先把自己加载到7C00h,然后又把原引导程序拷贝到7C00h,这个过程会出现什么问题?就是前面遇见的自我覆盖问题,所以需要将病毒中执行拷贝的指令段移出被覆盖的区域。我们可以将它后移一个扇区7e00h处
感染过程:感染会将原引导扇区的内容一直放到簇2,如何避免后续使用占用簇2,破坏了病毒的逻辑?可以修改FAT1和FAT2表,将簇2的项改成不可使用,如果改为已占用FFF,但却没有对应的目录项,是可疑的,因此,可以改为坏簇FF7,从而防止别人使用它。这些感染,为了简单,没有采用汇编访问硬盘的方式,而是采用C语言来直接修改软盘文件。
基础知识
- 复位磁盘系统
Xor ah, ah ;ah=0为磁盘复位
int 13h ;13h为磁盘中断读指定从磁头,道,扇区起始,n个扇区到内存缓冲
AH = 02h是读扇区功能号
AL = 将读入多少个扇区
CL = 起始扇区号
CH = 磁道
DH = 磁头
DL = 磁盘,0代表a盘
ES:BX = 读缓冲的地址,一般只填写BX
Mov ah, 02
Mov al, 5 ;读5个扇区
Mov cl, 1 ;从1扇区开始
Mov ch, 0 ;读0道
Mov dh,0 ;读0头
Mov dl, 0 ;读a盘
Mov bx,7c00h ;读到7c00h处
int 13hInt 13h采用的是CHS的硬盘寻址方式,而我们习惯上采用绝对扇区号为0,1,2,3,…的线性方式。
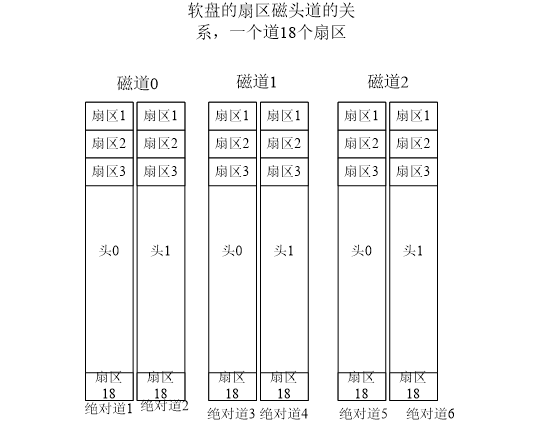
绝对扇区号如何转换为磁头/道/扇区号
软盘的扇区磁头道一个道18个扇区。
- 道内扇区号(从1开始计数):给定绝对扇区号,除以18(软盘一道有18个扇区),则余数+1是道内扇区号 (道内扇区从1开始),商为N则N+1为绝对道(比如,绝对扇区19,商1,余数1,道内扇区2,绝对道2)
- 磁道(从0开始计数):不同头的相同道是连续存放的,假定磁头数目为m(m=2),则N/m去掉小数为磁道,也即对应的磁道号。软盘m=2,即N右移一位是磁道号(N >>1)
- 磁头:对于软盘,有两个头,因为绝对道=N+1。当绝对道为奇,N为偶,对应头0当绝对道为偶,N为奇,对应头1。绝对道6(N=5)对应头1因此,采用运算N & 1获得磁头号。N为奇数 and 1 = 1,N为偶数 and 1 = 0。
绝对扇区号/18 得到余数和商N
扇区号:余数+1,磁道:N>>1,磁头:N & 1
执行部分程序设计
执行的时候发现存在引导原先系统盘失败的问题。病毒把引导区全部覆盖了,导致DOS无法识别a盘。在引导扇区,其实还有很多重要的引导记录(包括FAT有多少扇区,磁盘的介质类型等),因为病毒只是简单地覆盖了整个扇区,从而破坏了这些引导记录,导致DOS无法识别盘。
因此只要保留引导记录即可,引导扇区的头3个字节吗?是一条JMP指令和一个NOP,它会跳过引导记录,跳到引导程序处,因此,我们的病毒指令可以只覆盖引导记录后面的部分。
同样的,在加载时它实际加载的地址是引导记录,不是指定的地址,因此加载的位置与实际有偏差,需要使用到重定位。
解决1:写自定位代码
解决2:让病毒代码前面加入偏移
为了真正执行的病毒代码不发生加载偏差,在病毒指令之前加入了填充字节(字节数为引导记录占用的字节数),需要定位到引导记录后才拷贝,并且从写入时从引导记录后开始复制,复制长度减少了引导记录的长度(即仅仅复制病毒执行部分的长度)。修改后结果,在非引导下,可以正常识别被感染的软盘了。
中断替换
中断向量表
中断引发后,就会去调用一段处理程序,叫中断处理程序(例程),系统找到中断处理程序的入口地址,从而执行中断,系统通过中断向量表找到中断处理程序的入口地址,中断向量表存放在内存的最低处,即00:00处,每4个字节为1个项,这个作为索引的项就是中断向量号, 其中存放一个中断处理程序的入口地址,高2字节是段地址,低2字节是段内偏移。
一个中断触发指令int xxh,其中的xx就是中断向量号,4 * xx就是中断xx的入口地址在中断向量表中存放的位置。比如int 10h其入口地址就存放在中断向量表中的4*10h = 40h的位置。
非驻留式中断向量修改
驻留程序就是一直在内存中不退出,系统的中断处理程序要为所有程序服务,所以它的特点就是不退出一直驻留在内存中。
病毒为了获得执行,会修改中断处理程序的入口地址(即修改中断向量表)指向病毒提供的一段程序,这样,只要调用相应的中断,就会去执行这段程序。但是,这段病毒程序必须也是驻留程序,否则病毒结束后,内存回收,这段程序也不在了,导致中断向量表指向无效。因此,在非驻留式的中断替换中,我们还需要在病毒程序调用后恢复中断向量表。

结合之前,段寄存器和中断向量表是在不同的段的。段寄存器需要根据实际访问情况变化,先从低2字节处取出中断程序的段内偏移 ,约定放在AX寄存器中,再放到数据区的Offset处,再从高2字节处取出中断程序的段地址,约定放在CX寄存器中,再放到数据区Seg处。
病毒需要由自己段跳到原中断向量程序所在的段。要跨段跳转,就要采用JMP XX:YY的形式,但是JMP CX:AX的语法是不支持的,即JMP XX:YY的指令不支持两个间接性,XXYY总有一个是立即数,而程序里面Seg和Offset都不是立即数,怎么解决?我们可以先采用两个立即数来确定JMP指令的形式(比如JMP 00:00),然后我们再来定位到JMP指令的机器码,进行按字节的细粒度修改。

第八章-链式病毒
链式病毒只保留一份病毒拷贝,利用文件目录项,将受感染文件的头簇指向病毒。
复习之前获取文件的内容知识

工作原理
感染过程:
如首次感染,将病毒保存在某个空闲扇区
将被感染文件(COM文件)首簇存目录项保留段
修改首簇号指向病毒的首簇
执行过程:
执行被感染文件则启动病毒,加载的是病毒的首簇,并执行
病毒获取当前执行程序的名字,获取对应目录项。从其中保留字段获取原文件首簇号,并遍历FAT簇链加载它们。
跳到加载的原文件内存中执行
具体过程
一、感染部分
- 被感染文件的真实起始扇区号写到
目录表项的保留区(目录项的保留区从目录项头第13个字节即偏移0ch开始,共10字节) - 修改被感染文件的目录项的
起始扇区字段指向病毒文件的首簇 - 目录项中的
文件大小字段也要修改成病毒的真实大小,这样才能保证病毒能被完整加载 - 将原来病毒文件的目录项全部32字节改为0,这样从外部看就不存在这个病毒文件,也没有对应的目录项了
二、执行部分
病毒运行后,先获取被
感染程序的名字然后从根目录寻找
被感染程序的目录项找到后从该目录项的保留区获取
被感染程序的首簇号找到被感染程序所在簇(即扇区),加载该扇区到内存
因为被感染文件是COM文件,将其加载到内存100h处,并将执行权交还给被感染文件
注意的细节:当把原文件加载到100h时,会产生
自我覆盖的问题,和头感染相似,因此,病毒代码需要把执行拷贝功能的代码段移到一个安全区域(即不会被覆盖的区域)。因为本病毒是针对被感染文件大小 < 1扇区的文件,因此,只需要移动到100h(加载地址) + 200h(1个扇区大小)的位置即可(即300h)

如何获取执行文件名
原理:
从COM文件的DS:2c处获得环境块首址的段地址,环境块就在段地址:0000 处。
环境块内容:PATH=……COMSPEC=C:\COMMAND.COM\0….0 0 xxxx。环境块开始是PATH等0字符结尾的串,最后是两个00字符。然后有两个字节,可能是数目,之后就是执行程序的名字。
第九章-Win病毒-虚拟地址
动态链接库DLL
动态链接库(Dynamic Link Libraries)为模块化应用程序提供了一种方式,使得更新和重用程序更加方便。
1)动态链接库是应用程序的一部分,作为模块被进程加载到自己的空间地址
2)动态链接库在程序编译时并不会被插入到可执行文件中,在程序运行时整个库的代码才会调入内存,这就是所谓的“动态链接”
预备知识
Windows系统下程序是如何被加载执行的?
而执行首先需要加载到内存,这又涉及到保护模式下内存管理的问题。下面我们将先学习内存管理和程序加载的相关机制
Windows内存管理和程序加载
DOS的内存管理,是实模式,我们可以随意改动甚至系统的内存(比如修改中断向量表)
Windows是工作在x86的保护模式。每个进程都有自己独立的线性地址空间(0-4GB,32位CPU的寻址能力为2^32=4GB),互不干扰,这4GB空间会按某个固定的大小(如4KB)分成N个页
同时,内存又分为用户空间和内核空间,用户空间的代码(我们编写的exe)无法直接访问内核空间内存的。这些限制让我们无法像DOS那样随便涂改内存了
保护模式最大优点是对内存寻址从机制上提供了保护,将系统的执行空间按权限进行了划分,防止应用程序非法访问其他应用程序的地址空间(任务间保护),防止应用程序非法访问操作系统地址空间(系统保护)。
内存
在Windows系统下,现在是保护模式,我们看见的内存地址,是逻辑地址,并非真正的物理地址。实模式下,看见的内存地址就是真实的物理地址。
同一逻辑地址的值对应不同物理上的内存地址正是保护模式的能力。
虽然逻辑地址相同,但具有不同的映射对应,从而使得大家的物理地址各不相同,但是却隐藏了真正的物理地址,起到保护作用。
虚拟地址转换过程
32位虚拟地址分成3部分(详情请见操作系统):
CR3寄存器给出页目录地址
CR3寄存器:
PDE 页表目录:每一项4个字节,保存了页表的地址
PTE 页表,里面包含每一页的物理地址和页属性
在分页系统中,为每个进程配置了一张页表)
前面10位用于在页目录中查找页表地址
中间10位用于在页表中查找页表项
后面12位给出相对页表项地址的偏移
PE如何解决COM加载的缺点
- DLL模块加载的真实内存地址不可能是相同的,相同则产生覆盖。这和COM死板的约定加载到100h不同,既然这个加载地址不是固定的了,那么可执行程序应该有地方存储了约定的加载地址
- COM约定了加载的地方就是程序开始执行的地方(100h必然是第一条指令),但这个也太死板(想像一下我们将子函数写在main函数之前),所以我们可能需要在执行程序中存储真正代码开始的地方(即存储第一条指令到头部的偏移即可)
- 如果确实加载不到约定地址,而代码自身又不具有自定位代码(很不方便),那么我们可以需要一种重定位机制,这又可能需要借助一种新的数据结构,比如重定位表
- 这些都导致了执行程序需要一种格式来描述信息,除了指令和数据外,还应该有相应的格式或结构来存储上面这些东西
第十章-PE结构和末节寄生
在Win32位平台可执行文件命名为可移植的可执行文件(Portable Executable File),该文件的格式就是PE格式
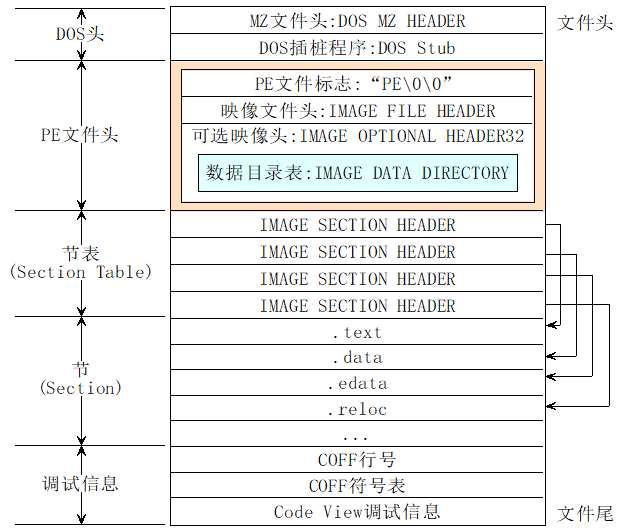
映像
PE文件的加载要完成
虚拟地址(内存)和PE文件(硬盘)之间的映射关系,所以又被称为映像文件。当真正执行某个内存页中的指令或访问某一个页的数据时,这个页面才会真正读入内存。
在学习PE文件的时候,一定要区分文件位置和虚拟地址的概念,而在内存定位时,除了虚拟地址(Virtual Address,VA)的概念,还有相对虚拟地址(RVA)的重要概念
RVA-相对虚拟地址(Relative Virtual Addresses)
第一,虚拟,说明它不是一个真实地址,因此,它应该就是前面我们提到的逻辑地址,既然是逻辑地址,应该就是指的就是内存了(注意和硬盘上文件中的位置相区分)
第二,相对,相对说明这个地址很有可能是对某一个逻辑地址的偏移,而这个逻辑地址很有可能就是我们PE文件加载到内存时,所占用的最开始的那个内存单元的逻辑地址(或称之为基地址)
RVA和FOA的联系与区别
- RVA是内存的相对位置,相对的是加载到内存的基地地址
- FOA是文件中的相对位置,相对的是文件开始位置(即0)

文件在硬盘存储时的对齐方式和在内存加载时的对齐方式是不同的,在文件中,每一个节往往按512B(200H)的粒度对齐。而在内存中,通常以4096B(1000H)的粒度对齐,由于对齐的方式不同,有些节,它在内存的RVA就和它在文件的FOA就不一致。

如何让病毒被加载、执行?
PE文件格式字段:
e_magic:两个字符MZ代表DOS文件
e_lfanew:偏移量,就是从文件开始到PE文件头(NT头)的偏移量
通过“MZ”和后面的“PE”标志,来初步判断文件是否为PE文件,从而确定是否进行感染寄生
PE头(NT头)
nPE文件头的结构是IMAGE_NT_HEADERS,又称之为NT头,它是存放了整个PE文件的相关重要信息
IMAGE_NT_HEADERS STRUCT
Signature dd ?
FileHeader IMAGE_FILE_HEADER <>
OptionalHeader IMAGE_OPTIONAL_HEADER32 <>
IMAGE_NT_HEADERS ENDS它包含3部分:
- PE文件标志(Signature):字段头两个字节是“PE”,表明该文件是PE格式的文件。
- 映像文件头(IMAGE_FILE_HEADER):NumberOfSections字段存储文件中节的个数
- 可选映像文件头(IMAGE_OPTIONAL_HEADER32):
- AddressOfEntryPoint表示代码入口RVA,第一条指令的RAV
- ImageBase: Cardinal; //载入程序的首选RAV
- SectionAlignment: Cardinal; //节在内存中对齐方式
- FileAlignment: Cardinal; //节在文件中对齐方式
- SizeOfImage: Cardinal; //内存中整个PE文件的总大小,按内存对齐
- DataDirectory: array[0..IMAGE_NUMBEROF_DIRECTORY_ENTRIES - 1] of TImage_Data_Directory; //数据目录表
病毒判断一个文件是否是PE格式往往可以通过:
先判断文件头2字节是否为“MZ”
判断NT头的Signature是否为“PE”
利用入口RVA实现病毒执行的问题
知道执行程序的入口代码地址如何确定的,如果找到了,将它指向病毒代码,找到了AddressOfEntryPoint,它表示入口RAV,也是第一条指令的RAV,程序从这里开始执行。
我们需要通过RAV来找到该指令在文件中的FOA以便修改开始的机器码,利用RVA找到所属的节,如果该节的起始RVA和该节的起始文件偏移相等,那么就直接用作文件偏移。如果有差别:
入口点的RVA(AddressOfEntryPoint)- 节的RVA =入口点的FOA - 节的起始文件位置(PointerToRawData)
PE描述文件大小的字段
1)节表紧跟在PE文件头后,节表中的每一个结构ImageSectionHeader (28H)都对应一个节,其中,有两个字段描述了对应节的文件大小(SizeOfRawData)和加载到内存的大小(VirtualSize)(两者可能不同,文件大小可以大于内存也可以小于内存。小于内存时,将在内存补0)
2)在PE头的可选映像头ImageOptionalHeader中,SizeOfImage给出了整个程序包括所有头部加载到内存后的大小其大小应该是SectionAlignment的整数倍
简单说,就是PE文件总大小和每个节的大小都有参数:
- 每一个节都有一个对应的节表项SectionHeader结构
- VirtualSize表明本节加载到内存后的大小即加载到内存的实际字节数(未对齐)
- SizeOfRawData字段表明本节在文件中的大小(对齐后)因此,必须是FileAlignment(在可选映像头中)的整数倍
回到可选映像头ImageOptionalHeader中观察:
SizeOfImage给出了整个文件在内存中对齐后的大小
SectionAlignment是内存对齐的粒度
FileAlignment是文件对齐的粒度
用程序完成末段大小不变的寄生
生成需要寄生的病毒代码
获得被感染文件的NT头
- 利用DOS头的e_lfanew字段(文件定位)
- 定位NT头,读到ntHrds(文件定位读)
找到最后一个节判断是否具有空洞
如何判断节是否有空洞?
virtualSize < SizeofRawData
这些信息在哪里?
最后一个节的节表项中
当前的文件指针在什么地方?
之前读了NT头,现在在NT头的后面也就是节表的起始文件位置
修改最后一个节VirtualSize写入病毒
修改SizeofImage和EntryPoint
第十一章-EPO入口点不在代码节的问题
入口点模糊技术(Entry Point Obscuring)
每个节的节表项有一个characteristics属性,说明了该节是干什么的,当IMAGE_SCN_CNT_CODE为20时说明是代码节. EPO技术能够让病毒代码隐藏自己入口点,避免被查杀,使得被病毒修改后的入口点看起来依然就像是正常的入口点.
解决入口点不在代码段的问题,我们可以采用下2种解决方法:
1)不感染最后一节,直接感染代码节,病毒代码附着在代码节的尾部,再修改入口点。这样虽然修改了入口点,但让入口点处于代码节
2)不修改入口点,但将入口点所在的指令替换成一条JMP指令,跳往到寄生的病毒代码
EPO1 感染在代码节的空洞
本方法有个缺陷,真正的入口一般都在代码节的前部,而我们感染的是尾部,这样修改后的入口点太靠代码节的后部,这也会使得入口点看起来异常,从而被一些杀毒软件查杀
比如,我们正常软件入口是1690h,代码节.text的起始RVA是1000h,正常入口在节内偏移只有690h,如果感染到本节尾,则修改后的入口点在节内偏移将是212B0-1000=202B0h,远远大于690。基本就是节尾了,这就会引起怀疑。
此外,感染代码节时,代码节往往不是最后节,如果代码节空洞不够,就必须增加代码节的节长,则后续节都要修改RVA,文件偏移等字段,非常麻烦
程序设计
生成需要寄生的病毒代码
获得被感染文件的NT头
找到代码节并判断是否具有空洞
如何找到代码节?遍历所有节表项并判断节表项的属性是否有20属性
修改VirtualSize写入病毒
修改SizeofImage和EntryPoint
EPO2感染最后节并替换入口指令
感染时,先将原入口5字节保存,替换成JMP跳到寄生代码。病毒执行后,将入口5字节还原,然后跳回到原入口
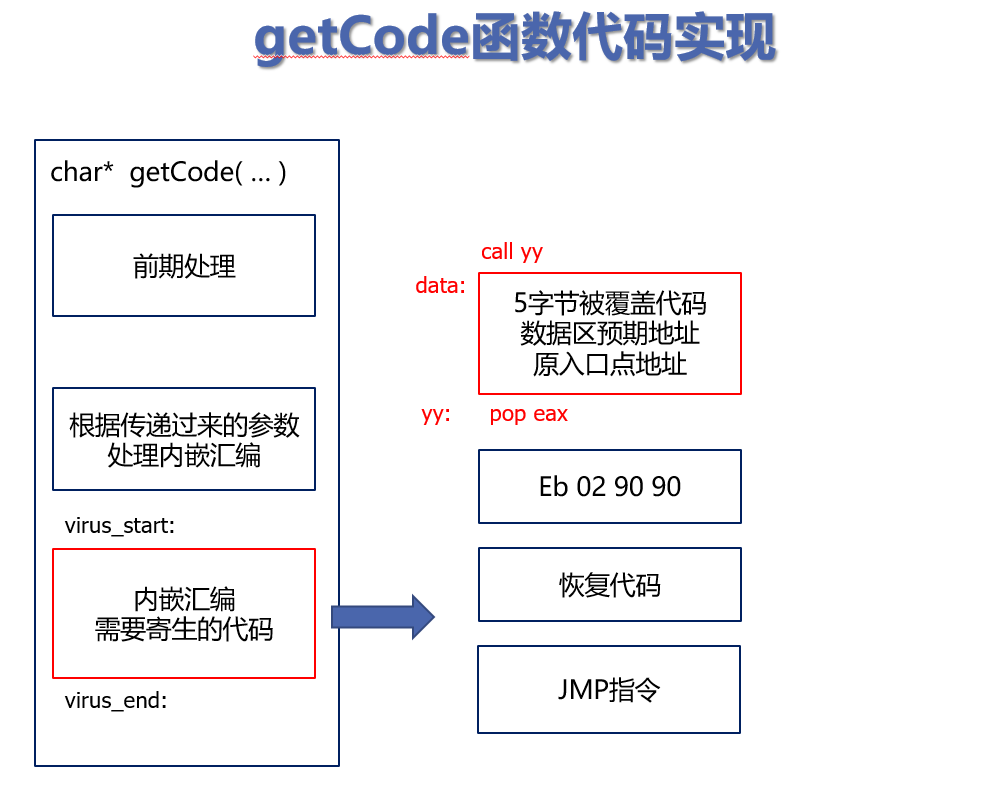
如何生成寄生的病毒代码
病毒代码需要进行恢复跳转等细致的操作,所以我们把病毒代码采用C中内嵌汇编的方式编写,生成病毒代码code后,然后利用C语言来完成病毒代码的寄生拷贝
思考:病毒要做的事有哪些
修改原入口点的数据为JMP指令
保存被覆盖的5个字节
执行逻辑
恢复这5个字节
源地址就是被覆盖的5个字节,放在数据区,所以我们把可以把数据区的起始地址也作为数据放入数据区
目的地址是原程序的入口点地址,寄生后,病毒的main函数就结束了,所以这个入口点地址也需要写入数据区时
最后一条JMP跳回原入口点
因此,寄生代码的数据区应该有5+4+4=13个字节
寄生代码生成的时候,这些重要的地址信息是根据PE文件的预期加载地址ImageBase来生成的,所以说是预期地址。然后寄生代码会放到原文件中,如果原文件加载到预期的ImageBase,寄生代码中的地址信息就是正确的。但是!ImageBase是程序预期加载的基地址,win7系统和vs编译器往往都采用了随机地址空间技术,使得程序即每次加载的实际地址并不是ImageBase,原文件有重定位表这样的机制帮助重定位,但病毒只能利用前面我们学到的自定位技术原理。
关键在于:
- 找到入口点所在的节
- 然后将入口点(内存位置)转变为文件位置
实际中会遇到内存区只可读不可改的情况,因此我们把characteristics的值改为我们想要的可写即可,80000000h代表写,为避免类似情况,我们选择在循环搜索入口点所在的节时,一旦找到该节,就将该节的索引(后面写入时需要利用这个索引值找到该节)和属性字段保存,然后,在文件中定位到该节的节头,计算新的属性值并写入到节头的属性字段。
第十二章-DDL+导出表
如何让病毒调用函数
我们需要在病毒数据区存放调用函数所需的参数。如何访问这些参数呢?用我们已经熟悉的自定位代码即可,call后再pop到eax,eax就指向了参数的地址。
操作系统通过动态链接库(DLL)来对外提供API
1)动态链接库是应用程序的一部分,动态链接库在本质上是作为模块被进程加载到自己的空间地址的。
2)动态链接库在程序运行时整个库的代码才会调入内存,这就是所谓的“动态链接”
如何获取API的入口地址
只有获取了API函数入口地址(模块DLL – > 函数),我们才能跳过去调用它,没有操作系统和编译器的帮忙,就只有自力更生:
(1)找到提供这个API函数的DLL的加载基址
(2)从DLL的导出表中拿到API函数地址 ,理解DLL的导出表机制,可简单想象成一张表,然后在这个表中根据函数名找到函数入口地址。我们的操作系统通过kernel32中的GetProcAddress来实现的,但是我们病毒,还是只能自力更生
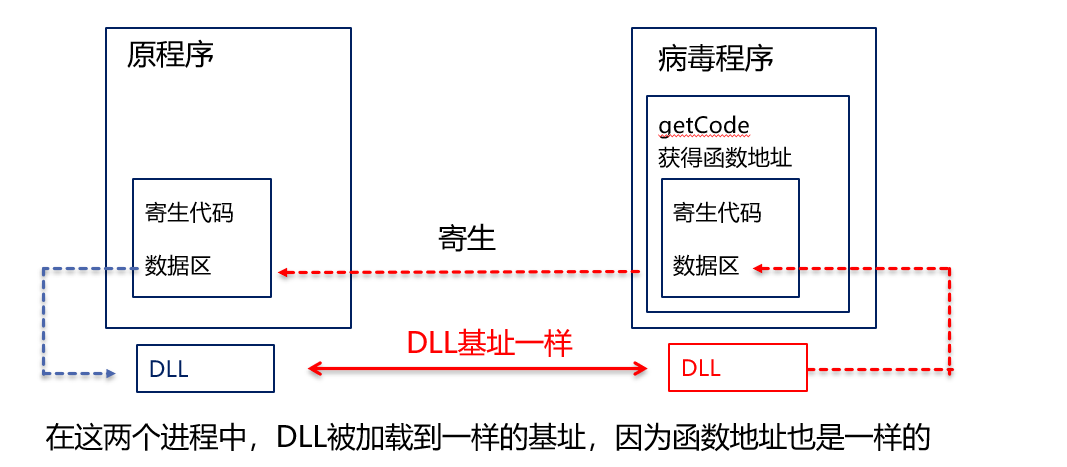
想要快速拿到一个API的入口地址,有一个简陋但快速的办法,它基于如下事实:一个系统中,所有进程加载的同一个DLL的加载基址是相同的。在Windows的设计中,因为某种原因(可能是共享代码段,避免重定位等),每个进程中,系统DLL都被加载在一个地址。
如何利用DLL基址相同让病毒获取API首址?
只需要在C写的病毒代码中获取MessageBox的首址,然后把这个首址写入到我们病毒的数据区,这样病毒代码寄生到了原文件上时,就可以在自己的数据区获得MessageBox的首址。
如何判断是否是控制台程序
在PE文件的可选映像头中,有一个字段可能能够用于识别PE文件是否为控制台程序,就是subsystem,对于大多数Win32程序,只有Windows GUI和Windows CUI两类值。G - Graphic的头字母,C - Console的头字母,因此,我们只需要判断subsystem字段的值,当其为2时才感染即可。
病毒真正获取API函数地址的方法
一、获取DLL基址
只有找到DLL基地址,我们才能找到它的导出表,才能找到所要调用函数的地址。以获取kernel32.dll的基址为例,其他dll模块的方法类似,这里介绍一个简单的获取kernel32.dll基址的方法,主要利用PEB结构(Process Environment Block,进程环境块)查找,每个进程都对应一个PEB。
首先,FS寄存器在偏移0x30处保存一个指针,指向PEB结构,FS:[0x30] -> PEB。
然后,在PEB结构的偏移0x0C处保存着另外一个指针,该指针指向一个叫PEB_LDR_DATA的结构
这个PEB_LDR_DATA 偏移0C处是加载模块链表的头指针,由8个字节组成,前4个字节指向一个LDR_MODULE结构体(LDR_MDOULE代表一个模块,每一个模块(exe,dll)都对应一个这样的结构体),在该LDR_MODULE中,头4字节又指向下一个加载的LDR_MODULE结构体,由此组成链表。
在win7下,第一个加载的模块是是执行程序本身,第2个是NTDll,第3个就是kernel32,在结构体偏移0x18处就是所对应模块的基址。
那如何在遍历的过程中识别模块呢?
在LDR_MODULE结构体偏移0x2C的地方,有一个成员BaseDllName,它有8个字节,其中后4字节为地址,指向一个unicode串(每个字符占2个字节),这个unicode串就是不包含路径的纯模块名。
遍历的结束条件是什么?Next指针为0或者ffffffff么?都不是,过调试我们可以发现,在win7下,加载模块链形成了一个循环链表,因此只要发现next块的头4字节是头块地址就停止遍历。
二、获取DLL中的函数地址
找到基址后,我们必须手动完成由函数名获取其所在DLL中地址的过程,我们需要从DLL的实际基址入手,解析DLL的导出表,获取相关函数的入口地址。
导出表—DLL对外暴露函数地址的机制
DLL对外暴露自己的函数有两种方式:
- 函数名
- 序号
可以通过函数名查找某函数入口,也可通过序号查找,但是,需要注意的是,函数名和序号并非一 一对应!
序号查找
序号查找的好处:快!高效!
我们可以用一个简单的hash完成,而不需要遍历,如果我们用一个数组(funcEntryTb)存储函数的入口地址。第0号函数的入口地址就存入数组的第一个元素funcEntryTb[0],第1号函数的就存入数组的第2个元素funcEntryTb[1]。这样获取入口地址非常简单 ,即funcEntryTb[n],n是函数的序号,也就是拿到数组首址funcEntryTb加偏移n*4(每个地址4个字节)即可。类似DOS下的中断向量表。
如果序号不是从0开始,而是从n开始,我们依然是将n对应函数的入口地址存入第一个元素,依次类推。获取第M(M肯定大于n,因为n最小)号函数的地址如下: funcEntryTb[m - n]。依然非常快速,计算次数固定,即拿到首址funcEntryTb,做一次减法m-n,再做一次乘法(m - n)*4就获取到元素的地址,取出其值保存值即可。这其实也是c语言switch语句出来case中序号和case分支入口地址的方法,所以一般switch比if else嵌套快
但是序号查找不够直观,同时也不够稳定
用函数名查找
用函数名查找:直观!具体!
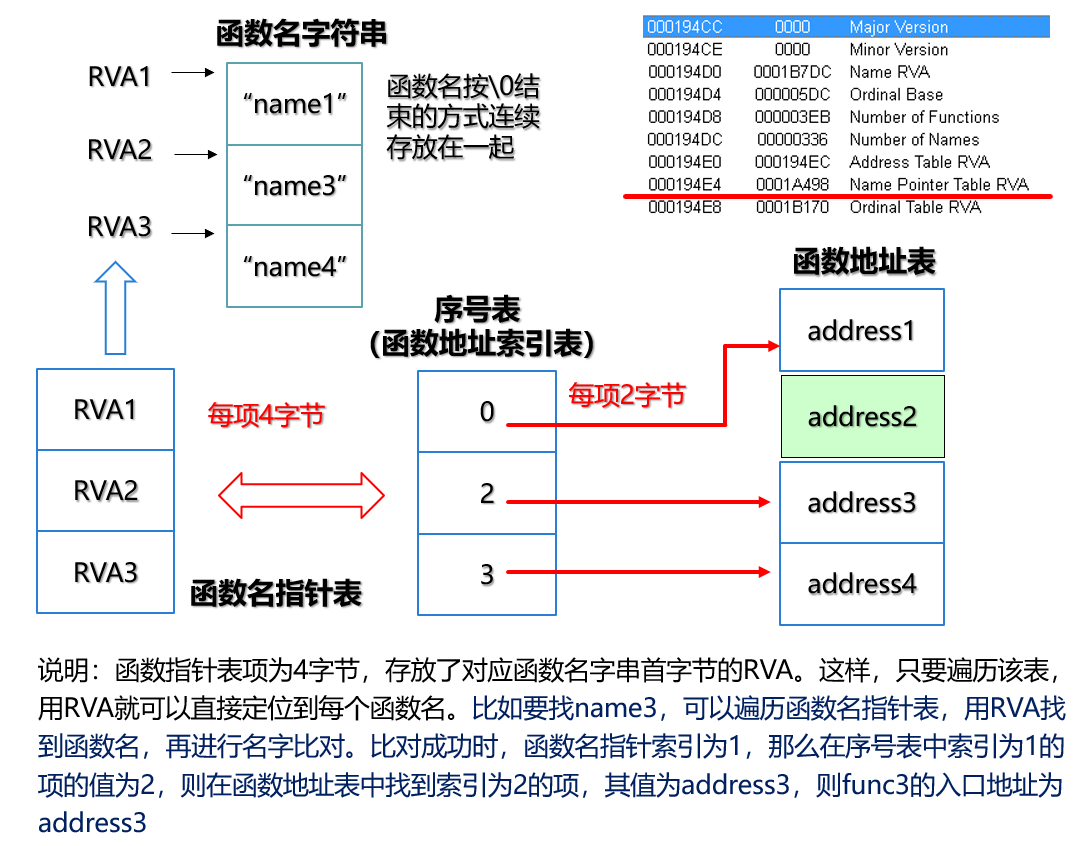
最简单的办法就是一个一个函数名字串比较,找到相同的串。下面给出一个简单实现:函数名表的索引和函数地址表的索引是一一对应的。如果查找func2函数地址,我们先遍历函数名表,每遇到\0就是一个串,自然,在第2串处找到了字串func2,fun2是函数名表第2项,索引为1,然后我们用索引1在函数地址表中获得了address2,函数地址表4字节一个元素通过两个表相同的索引建立关联。
两种机制结合
如果用序号导出对应一个函数地址表,用名字导出也对应一个函数地址表,两个函数地址表显然会造成存储浪费,能否合成在一个函数地址表?
要实现合并需要满足:
- 所有函数都有即有函数名又有序号
- 函数名表的索引和序号都是按1递增的
- 函数名表的排序还必须按照序号值排序,也就是说,如果一个函数的序号是x,它的函数名就必须排在函数名表的第x-1项
限制太多,而且最重要的是,并不是每一个函数都向外暴露函数名!有的函数是没有暴露函数名的!实际上,DLL中有些函数是只有序号暴露,而没有函数名暴露的。而函数地址表是和序号对应的!这样,就导致函数名表索引是无法和函数地址表索引形成一一对应的关系。
若要解决类似的问题,就只能通过增加一个表描述对应关系。增加一个函数地址索引表,用它来记录函数名表索引到函数地址表索引的对应关系。
而按序号查找时,直接根据序号计算其在函数地址表的索引:i=函数序号-最小的序号(n),然后在函数地址表中找到索引为i的项,取出地址即可。
导出表有表头(IMAGE_EXPORT_DIRECTORY)描述了导出表相关重要信息:
- Address Table RVA就是函数地址表的RVA
- Ordinal Table RVA就是函数地址索引表的RVA,PE格式叫它序号表
- Ordinal Base就是最小的序号,Number of names就是函数名表的条数
PE格式将函数名表做了些变化,用了一个函数名指针表,Name Pointer Table RVA,它每项4个字节,存放了一个RVA,指向一个函数名的字符串
如何获取导出表的表头
在模块的可选头中,最后有一个数据目录表EXPORT Table:数据目录表中的每一项都是一个重要的元素,包括导出表、导入表、重定位表等…每一个项都给出了相应元素的入口RVA和大小,其中,第一项就是重要的导出表。根据这个就能找到导出表的表头。
导出函数查找算法
从DLL加载的实际基址获取可选头,从其中数据目录表的第一项找到导出表入口RVA
从导出表的表头获取Number of names,即查找的最大循环次数
循环遍历函数名指针表,比对每项RVA指向的字串是否为要找的函数名
函数名指针表1项4字节 à 对应的字符串地址如果找到,记下此时函数名指针表项的索引,设为 i
根据索引 i,在序号表中找到对应项,获取其内容为n
序号表1项2字节以n为索引在函数地址表中找到函数入口的RVA,加上DLL的实际基址即为函数的实际入口地址
地址表1项4字节
注:以上算法中,所有访问实际地址的地方,就用DLL的实际加载基址+RVA即可
第十三章-EPO技术指令Patch和导入表机制
利用Patch指令的方式实现EPO
核心问题:
- 找到一条指令,并知道其起始边界
- 最好这条指令必然执行,否则patch了,病毒代码也不会必然执行。
解决思路:
- 对一些常见特殊指令识别,比如PUSH EBP;MOV EBP, ESP等,这是很多函数的开始设定基址寄存器的组合。简单,方便。缺点:由于指令长度过短,可能和数据相同,因此不见得一定是指令;同时,不见得该代码一定会被执行
- 对导入函数的调用指令进行Patch,这些指令的可靠度很高,可以选择某些必然被调用的函数指令去Patch
- 病毒自带反汇编器(如一些开源反汇编器),静态分析宿主程序,随机找一条指令Patch,隐蔽度极高,复杂,但Patch的指令不一定会必然执行
- 自带调试功能(相当一个调试器),将宿主程序隐藏启动,单步调试运行,自然得到每条指令的边界
为什么Call要用相对偏移
在前面,我们已经知道了加载可能出现与约定地址不吻合的问题(回想下PE头中的ImageBase字段),如果Call指令采用了绝对地址, 那么这条Call指令就会失效。
因此采用相对偏移Call就不会出问题,虽然加载基址变化,但整个模块是整体搬迁,call和被call之间的偏移却不变!所以无影响。
相对偏移的优点只能运用到同一个模块中(DLL,EXE),如果跨越了模块,调用DLL中的函数时,并不知道该模块会加载到哪里,因此,是不可能事先算出转跳偏移的,那怎么办?
这是在编译器和系统协助下,利用导入表机制完成了这个工作。简单说,就像为每个被调用的DLL函数都设定一个邮箱,系统加载了DLL后,利用导出表机制获得函数的地址(这个我们前面已经学习过了),然后将函数地址放到各自的邮箱中,这样,需要调某函数时,就从邮箱里拿到这个地址。
理解导入表机制
在可选头的数据目录的第2项就是是导入表的描述,其中有导入表的RVA
RVA指向导入表(IMPORT DICTORY TABLE)起始,在这个地方,每一项是一个IMAGE_IMPORT_DESCRIPTOR结构,代表一个导入的DLL的相关信息。在这个结构中,又有:
INT表(Import Name Table)和IAT表(Import Address Table)的RVA
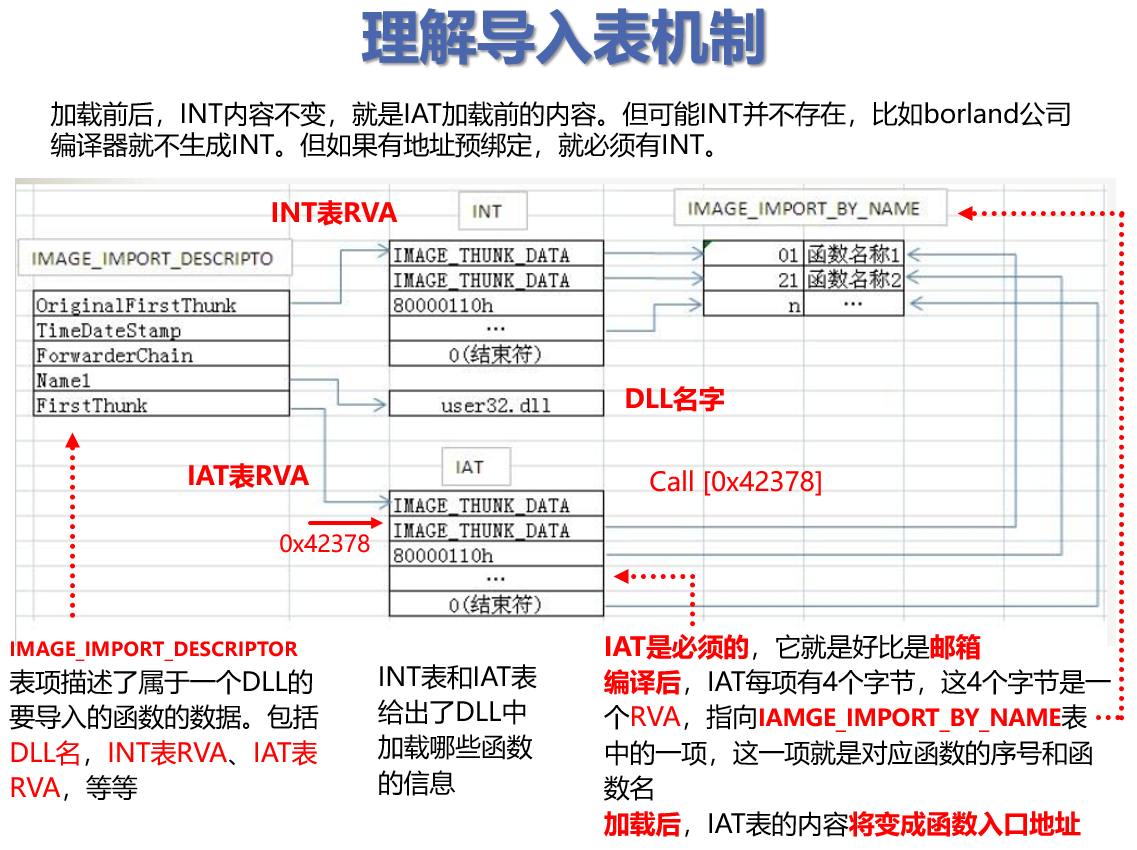

在一般情况下,INT(OriginalFirstThunk)和IAT(FirstThunk)的内容确实是相同的,因此,是冗余的。正是这个原因,为了节约空间,一些编译器(如Borland)不会生成INT,其RVA值为0。但是,这是在没有使用预先绑定导入地址的情况下,如果有预先绑定,则必须要有INT表,此时RVA不等于0。
由于程序在加载时,需要在IAT表中填入函数的加载地址入口,因此,往往会比较耗时,为了减少加载时间,于是有了预先绑定技术。
预先绑定技术是在编译时就向IAT表中填入导入地址(即函数的入口地址,而不是指向IMAGE_IMPORT_BY_NAME表项的RVA),它是直接根据系统DLL的预期基址(ImageBase)计算出来的。
通过预先绑定,在实际加载时,只要系统DLL的基址没有发生改变,那么IAT表的内容就不需要再次填充,因此,加载时速度更块。
所以,采用预先绑定,在实际加载时,需要验证DLL是否被加载到预期地址。如果,引用的DLL没加载到预期地址,那就必须再次填充IAT表为实际的函数地址。
这时,已经不能使用IAT表来指向IMAGE_IMPORT_BY_NAME表项了(编译时RVA已经被覆盖为函数预期入口地址),但INT表可以,通过INT表再次执行导入机制,从而使得IAT表内容更新。
这也就是为什么预先绑定时必须要有INT表的原因!
第十四章-指令Patch实现与重定位表
如何找到需要Patch的指令
整体思路:
为了找到需要Patch的指令,病毒可以采取以下的动作:
- 首先指定一个会被大概率调用的函数名(也包括函数所在DLL的名字),如Kernel32中的GetCommandLineX,X=A/W
- 然后通过被寄生文件(exe)的导入表找到该函数的导入表项(即IAT中的对应项地址)的地址XXXX
- 最后去exe文件的代码中搜索所有可能的Call [XXXX] 或 JMP [XXXX]后,即 FF 15 XXXX 或 FF 25 XXXX
详细来说:
- 在文件中找到导入表的位置:先找到导入表的RVA,将RVA转换为导入表的文件位置
- 找到指定API函数在IAT表中的表项地址。先要找到API所在DLL对应的项,然后才能找到这个DLL所对应的INT和IAT表,比较dll的名字,判断是否是API函数所在DLL的导出表目录项,然后根据预先绑定,如果有INT就用INT表来找函数名,没有就用IAT表找函数名,获得INT表(或IAT表)的RVA,并将其转换为文件位置,遍历INT表(或IAT表)的每一项,查找指定的API函数名。
- 找到符合的指令进行Patch,先找到代码所在的节,判断节的属性是否有0x20,找到后开始循环遍历每个字节进行替换,并写入patch指令。
病毒执行部分的设计
- 我们准备patch调用GetCommandLineA或GetCommandLineW的函数,因为它们基本在入口处会被调用,这样可以保证病毒一开始就执行
- 为了防止函数再次调用时病毒再次执行,我们增加了一个标记
- 另外,感染时到底patch的是W还是A版的GetCommandLine,也有一个标记来告诉寄生的病毒代码,从而寄生病毒执行时才知道去找哪个函数的实际入口地址
- 寄生病毒执行时,找到函数地址后需要存储一下,因此,并分配了4字节存储GetCommandLineX(W/A)的入口地址。为了不修改老代码,数据区开始的原来13个字节没有删减,用于存放这3个信息。
- 在数据段增加了“GetCommandLineA”和” GetCommandLineW”串,因为要用getproc动态查找到其首址跳过去
- 增加了获取kernel32基址和获取GetCommandLineW/A的代码
- 最后用JMP指令跳到GetCommandLineW/A去
关于最后跳转的问题,因为JMP跳转包含的地址是绝对地址(这是函数所对应的IAT表项的地址),如果在exe可重定位的情况下,这个xxxx地址是需要重定位的。然而,病毒尾部的这条Jmp [xxxx]是病毒添加的,因此,在重定位表中没有重定位项的,所以会出错。
解决的方法:添加重定位项或让exe不会重定位
利用IAT表项查找函数入口
除了修改节头的相关信息数据外,还要填充节直到长度达到要求
感染时填充数据区的预期加载地址,数据区的预期加载地址是:imagebase + 被感染节的起始RVA+virtualSize+5(自定位的call指令长度),数据区在call指令后
被调函数的IAT项的地址,Patch函数调用时,将获得IAT项地址返回,并将其作为参数传递给getCode函数,getCode函数将IAT项地址填入此处.
因为exe可能被重定位,所以IAT的地址可能变化,需利用病毒数据区的信息来定位IAT的实际地址。算法如下:
- call..pop自定位代码获取了数据区的地址A
- 数据区的预期加载地址=B= [A+1]
- IAT表项的预期地址是[A+5]
- IAT表项重定位后的实际地址是 IAT_addr – [A+5] = A – B
- 通过[IAT_addr]获得函数入口地址
如此,则不需用再去调getproc查询函数入口地址
PE文件的重定位机制
程序因加载到非编译期约定地址时,就必需修改那些包含了绝对地址的指令(因为这些绝对地址已经不是原来的地址了),这称为程序重定位,由加载器(loader)完成
本来,exe是不需要重定位的,它是用户模块第一个进入进程空间的,它的约定加载基址,只要不过分(和系统DLL抢),都可以被满足
但因为为了对抗攻击和安全考虑,从VS2003开始,微软编译器缺省会将exe编译成可重定位模式
理解PE文件重定位的关键在于要解决两个问题:
- 如何进行重定位呢?
- 加载器如何知晓哪些地方需要被重定位呢?
如何进行重定位
算法:
- 实际和预期加载地址的差x = A – B。
- 找到需要修改的位置y
- 读出y开始4字节的值 + x = 新地址值z
- 将z写入y开始的4字节
如何知道哪些地方需要重定位
- 在可选头的数据目录中,有一项(第6项)就是重定位表,而重定位表中就记录了所有需要进行重定位修改的位置
- 因为被修改的都是地址值(32位机上4字节),所以在重定位表中,我们不需要记录每个修改位置要改多少字节,只需要记录被修改的位置即可,那么Loader每次就根据这个位置定位4字节进行修改(加上加载偏差)
- 需要重定位的区域以4096(2^12)字节(即16进制0x1000h)进行划分,在每个区域(Page)里面,每个需要重定位的位置都有相应的重定位项纪录了该位置离这个区域起始位置的偏移
- 针对每个区域,在重定位表中都有8字节的头部,其中前4个字节的值是这个重定位内存页的起始RVA,后4个字节是重定位块的长度(包括头和所有表项在内的字节数)
- 划分为区域后,重定位表中的每一项就只需要12位(1.5个字节)来表示地址,另外有0.5字节为属性(通常我们只能看见属性3,表示所指向的32位地址都需要修正),即如300F,则00F为偏移。
在我们Patch指令的过程中,我们将该指令修改为了不包含绝对地址的指令形式(即:Call 偏移,Jmp 偏移),但并没有删除针对该指令的重定向项,那么重定位后,就会对这个重定位项指向的位置(即指向了我们Patch后的指令)进行修改,那么我们Patch后的指令就会被篡改!
解决方法,让exe重定位项失效,或删除这些被Patch指令的重定位项
第十五章-反病毒技术简介
反病毒技术的发展历程
第一代反病毒技术
- 采用单纯的病毒特征代码分析,清除染毒文件中的病毒
第二代反病毒技术
- 采用静态广谱特征扫描技术检测病毒,可以检测变形病毒,但是误报率高
第三代反病毒技术
- 将静态扫描技术和动态仿真跟踪技术结合起来,将查找病毒和清除病毒合二为一
第四代反病毒技术
- 基于病毒家族体系的命名规则、基于多位校验和扫描机理、启发式智能代码分析模块、动态数据还原模块、内存解毒模块、自身免疫模块等先进的解毒技术,较好的解决了以前防毒技术顾此失彼、此消彼长的状态,能够较好地完成查毒、解毒的任务
计算机病毒防治技术的划分
- 病毒预防,防止病毒进入内存或阻止病毒对磁盘的操作
- 病毒检测,计算机病毒的判定
- 病毒消除,计算机病毒感染的逆过程,恢复被感染程序原有的结构信息
- 病毒免疫,可能并不存在通用的病毒免疫方法
病毒防治技术从被动到主动
- 主动内核(Active K)技术,是在操作系统和网络的内核中嵌入反病毒功能,使反病毒成为系统本身的底层模块,实现各种反毒模块与操作系统和网络无缝连接,而不是一个系统外部的应用软件
- 主动内核技术能够实时监控整个系统的运行,并在病毒突破计算机系统软、硬件的瞬间发生作用
计算机病毒防范的概念
- 计算机病毒的防范,就是要在病毒执行之前进行阻断,需要监视、跟踪系统内类似的操作,提供对系统的保护,最大限度地避免各种计算机病毒的传染破坏,往往需要基于全系统的内核级行为监控
计算机病毒的预防措施
计算机病毒的预防措施可概括为两点
- 勤备份
- 严防守
计算机检测技术分类
检测计算机病毒的方法通常有两种:
手工检测
优点:可以剖析病毒、可以检测一些自动检测工具不能识别的新病毒
缺点:费时费力,复杂
自动检测
优点:可方便地检测大量的病毒
缺点:自动检测工具的发展总是滞后于病毒的发展
常见计算机病毒的诊断方法及原理
一、比较诊断法
用原始的正常备份与被检测的内容进行比较
优点:比较法不需要专用的反病毒软件,且可以检测未知病毒
缺点:
- 该方法依赖与未染病毒时的原始系统的备份
- 且无法知道病毒的种类名称
- 易于误报
二、校验和诊断法
根据正常文件的信息计算其校验和(checksum),计算新的校验和与原来保存的校验和是否一致
运用校验和法查病毒一般采用三种方式:
- 对被查的对象文件计算其正常状态的校验和,将校验和值写入被查文件中或检测工具中,而后进行比较
- 在应用程序中,放入校验和法自我检查功能,实现应用程序的自检测
- 将校验和检查程序常驻内存,每当应用程序开始运行时,自动比较检查应用程序内部或其他文件中预先保存的校验和
优点:校验和法既能发现已知病毒,也能发现未知病毒
缺点:不能识别病毒种类与名称,对某些对文件信息影响不大的病毒效果较差,如链式病毒;同比较法一样,病毒感染并不是文件改变的唯一原因,所以此法会产生误报
三、扫描诊断法
原理:扫描法是用每一种病毒体含有的特定病毒码(Virus Pattern)对被检测的对象进行扫描。如果在被检测对象内部发现了某一种特定病毒码,就表明发现了该病毒码所代表的病毒
- 特征代码扫描法
- 特征字扫描法
特定病毒码:当杀毒软件公司收集到新病毒中,就会从病毒程序中截取一小段独一无二且足以标记该病毒的二进制程序码(就好比犯人的指纹)
扫描法的软件通常由两部分组成:
- 病毒代码库,库中特征码的数量决定了扫描程序的识别能力
- 扫描程序(Scanner)
扫描法是当前最普遍的病毒检测方法,扫描法的核心——病毒特征码的选择
特征码选择的原则:
1.具有代表性:小的病毒一百多字节,长的10KB
2.不应包含数据区,数据区是可变的
3.特征码的长度:过长带来扫码时间和空间的开销过大,过短则不易具有代表性(两个相互矛盾的目标)
4.具有区分性:能区别该病毒和其他病毒,更重要的是要能区分病毒和正常程序,避免误报!
优点:
使用方便;特征码选择好则误报率低、选择不好则误报率高
不用专门查毒软件;可识别病毒名称和类别;可做扫毒处理
缺点:
特征码的生成难度很大;扫描需要开销;需要不断更新病毒特征码库
不易识别多态变形病毒、不能检测未知病毒等
四、行为监测诊断法
原理:利用病毒的特有行为特性监测病毒的方法,称为行为监测法
优点:即能发现已知病毒,也能发现未知病毒
缺点:误报,不能识别病毒名称和种类,需要病毒运行以后才能进行分析
五、感染实验诊断法
原理:利用病毒最基本的特征——感染特征,所有病毒都会进行感染,如果不感染,就不称其为病毒
当系统中出现了异常行为,最新版的检测工具也查不出病毒时,就可以做感染实验,其方法是:
将正常的文件放入异常的系统中去运行,看这些正常文件是否会被感染,如果被感染,则文件内容会发生变化(通过校验和等检测),则断言系统中存在病毒
优点:可以发现未知的病毒
缺点:实验开销大,实用性较差
六、软件模拟诊断法
多态病毒每次感染都变化其病毒代码,对付这种病毒,特征码扫描法失效。我们把使用通常特征码扫描法无法检测(或几乎很难检测)的病毒称之为多态病毒。但是,每一个多态病毒在执行时都需要还原,如先执行一段解密代码进行解密,再执行解密后的病毒代码。
通过在一个模拟的虚拟环境下运行计算机病毒,等待计算机病毒自身进行解密完成后,再对解密后的病毒代码实施特征码的识别,识别病毒种类后再进行有相关的清除和查杀工作。
七、分析诊断法
分析法一般只被专业反病毒技术人员使用,使用分析法的目的在于:
- 确认被观察的引导扇区和程序中是否含有病毒
- 确认病毒的类型和种类,判定其是否是一种新病毒
- 搞清楚病毒体的大致结构,提取特征识别用的字符串或特征字,并增添到病毒代码库供病毒扫描和识别程序使
- 详细分析病毒代码,为制定相应的反病毒措施制定方案
分析法是任何一个性能优良的反病毒系统研发所必须的,它是对病毒进行详尽认真的分析,专业人员需要了解PE文件格式、病毒的核心技术原理、汇编语言、Windows程序设计、软件调试方法等相关知识,还需要进行病毒样本收集、系统漏洞分析等工作。
分析法通常包括静态分析和动态调试两个步骤,Windows上一般的调试工具主要有OD、WinDBG、X64DBG等,对复杂的病毒程序,必须采用动、静结合的分析方法。
启发式代码扫描技术
启发式代码扫描技术是对传统的特征码扫描技术的改进,来源于人工智能技术
原理:启发式代码扫描技术基于给定的判断规则和定义的扫描技术,若发现被扫描程序中存在可疑的程序功能指令,则作出存在病毒的预警或判断。
- 可疑程序功能的权值定义
- 可疑程序的报警标准
- 可疑功能的标志
虚拟机查毒技术
全虚拟化技术:虚拟的操作系统,与底层的硬件完全隔离,完全由中间的Hypervisor层(VMM)完成指令转换和资源映射,典型的代表有Vmware,WorkStation,Microsoft Virtual Server等
半虚拟化技术:需要在虚拟机的操作系统中加入特定的虚拟化指令(Hypercalls),通过这些加入的指令来调用硬件资源,免除了一部分Hypervisor层转换指令的开销。典型的代表有Xen等。
查毒的虚拟机是一个软件模拟的CPU,它可以象真正CPU一样取指令、译码、执行,可以模拟一段代码在真正CPU上运行得到的结果
原理:虚拟机查毒实际上是自动跟踪病毒入口的解密代码,当其将加密的病毒体按其解密算法进行解密后,就可以得到解密后的病毒明文,虚拟执行技术使用范围远不止脱壳解密,它还可以应用在跨平台高级语言解释器、恶意代码分析、调试器等
目前有两种方法可以跟踪控制病毒的每一步执行,并能够在病毒循环解密结束后从内存中读出病毒体明文
- 单步和断点跟踪法,和目前一些程序调试器相类似:易于被病毒发觉
- 虚拟执行法: 控制权永远掌握在虚拟机手中,但完全模拟CPU的运行并非易事,虚拟执行法的意味必须在虚拟机内部处理所有指令的执行,这就需要具有大量的特定指令处理函数来模拟每种指令的执行效果,因此,虚拟机必须要保证模拟结果的正确性,但同时不可能被病毒察觉,且做到了完全虚拟执行
虚拟机模拟指令执行的设计方案:
- 自含代码虚拟机(SCCE):类似真正的CPU
- 缓冲代码虚拟机(BCE):进行了特殊指令和非特殊指令的区分
- 有限代码虚拟机(LCE):只简单地跟踪一段代码的寄存器内容
反虚拟执行技术
1.插入特殊指令技术
原理:虚拟机是模拟CPU的执行,并不是真正的CPU,所以不可以能对整个Intel的指令集进行支持,遇到不认识的指令就会停止工作
应对:不需要针对每个特殊指令写专门的模拟函数,只需要构建特殊指令的指令长度表,当EIP指向特殊指令时,就跳过特殊指令长度,或者发现这些特殊指令时,交由CPU去真正执行
2.结构化异常处理技术
原理:虚拟机仅仅模拟了CPU的工作过程,而对于异常处理等系统机制没有进行处理,虚拟机会在遇到非法指令、进入异常处理函数前停止工作
应对:为虚拟机赋予发现和记录异常的功能,并在引发异常时将控制转向异常处理函数
3. 入口点模糊技术(EPO)
原理:即便是虚拟执行,也不可能查找文件的所有代码,虚拟执行通常会在规定步数内,检查待查文件是否具有解密循环,如果没有,就会判定该文件没有携带加密变形病毒,产生漏报
应对:合理的增加检查的规定步数,如果规定步数较小,极易产生漏报,但规定步数也不能盲目增加,否则会无谓增加检测时间,如何确定规定步数的大小实在是件难事
4. 多线程技术
原理:虚拟对于模拟启动多线程的工作很难与真实效果一致,多线程切换需要交由下层操作系统负责管理,虚拟机只能在被执行线程独占CPU时间
应对:改进虚拟机,支持这些特定的操作系统机制
病毒实时监控技术
病毒实时监控本质上是一个文件监视器:
原理:在文件打开、关闭、清除、写入等操作时检查文件是否是病毒携带者,如果是则根据用户的决定选择不同的处理方案,如清除病毒、禁止访问该文件、删除该文件或简单地忽略,从而有效地避免病毒在本地计算机上的感染传播
可执行文件装入器在装入一个文件执行时首先会要求打开该文件,而这个请求又一定会被实时监控在第一时间截获到,它确保了每次执行的都是干净的不带毒的文件从而不给病毒以任何执行和发作的机会
计算机病毒的清除
引导型病毒感染时常攻击计算机的如下部位:
硬盘主引导扇区
硬盘或软盘的BOOT扇区
为保存原主引导扇区、BOOT扇区,病毒可能随意地将它们写入其他扇区,而彻底毁坏这些扇区中的信息
引导型病毒发作时,执行破坏行为造成种种损失
由于引导型病毒一般是常驻内存的,因此,清除病毒之前必须先清除内存中的病毒(或采用修复中断向量表等方法将其灭活),否则难以清除干净
计算机病毒免疫技术
重入检测和病毒免疫
大部分驻留内存的病毒会在加载病毒代码之前,检查系统的内存状态,判断内存中是否有病毒,若存在(自身已被加载),则不再加载病毒代码
感染文件之前,查看文件的状态(一般是查看感染标志),检查该文件是否已被感染,如果被感染了则不再重复感染
病毒的这种重入检测机制导致了一种反病毒技术的出现,也就是形形色色的免疫程序:利用免疫程序设置内存的状态、设置CPU的状态或者设置文件的一些特征,从而防止某种特定的病毒进入系统
目前常用的免疫方法有两种:
针对某一种病毒进行的计算机病毒免疫
基于自我完整性检查的计算机病毒免疫
不负责猜题
计算机病毒的定义?
编制或者在计算机程序中插入的破坏计算机功能或者毁坏数据,影响计算机使用,并能自我复制的一组计算机指令或者程序代码。
病毒的基本特征?
- 传染性
- 隐蔽性
- 可触发性
- 其他一些基本特性
- 破坏性
- 针对性
- 不可预见性
- 寄生性
- 衍生性
- 持久性
计算机病毒的本质属性?
人为的特制程序是任何计算机病毒的固有本质属性
程序性的客观性决定了计算机病毒的可防治性和可清除性
人为性的主观性导致计算机病毒各异多变
木马和蠕虫的概念:
蠕虫:独立的可执行程序, 不需要寄生在宿主程序中,通过网络分发自己的副本,工作方式为:漏洞扫描、远程攻击、迁移传染、现场处理
木马:在远程计算机之间建立连接,使得远程计算机能通过网络控制本地计算机的非法程序。木马系统软件一般由木马配置程序、控制程序和木马程序(服务端)三部分组成。
小端机和大端机?
整数逻辑上的最低字节放在内存的最低地址,次低字节放内存的次低地址,依次存放。比如,0x12345678(12为高位)放在内存中就是78 56 34 12(最左边为低字节)。大端机则相反
JMP指令计算偏移量?
从JMP指令的开始计算,直接加5。或者说是从JMP的下一条开始的指令算起被减数。
文件系统(重点)
一个FAT9个扇区,引导扇区1个,根目录区有224条记录,一个记录32字节,一个表项1.5字节
- 数据区中存放用户数据,是文件和子目录数据真正存放的区域
- 根目录区中存放的是文件目录表,为记录根目录文件项的表,文件项包括文件,目录。通过它可以查找到根目录下的文件和目录信息,比名称,大小,日期等
- FAT12为文件分配表(FAT(File Allocation Table)):记录已分配的扇区和可用扇区,并通过链表依序记录一个文件占用的扇区,另外一个FAT12为备用的FAT表
- 引导扇区(DBR (DOS Boot Record)):记录磁盘和文件系统相关的各种参数,比如扇区大小,一簇的扇区数等
如何定位一个文件?
FAT12文件系统中,FAT表以3个半字节(3*0.5 Byte = 1.5 Byte = 12 bit)来记录一个簇的相关情况,这也是“FAT12“文件系统中命名12的原因。
FAT表的本质是磁盘簇分配情况的数据表示,FAT表中每3个半字节为一个元素,这个元素就代表一个簇,簇号从0开始,这个元素中存放的整数值表示其链接的下一簇的簇号
- 查找和遍历
类似于链表的查找,以FFF为结尾,FAT12默认设置引导区占一个扇区,FAT1于其后,同时FAT表开始的3个字节没用于用户文件分配,3字节有2组12bits所以,占用了0,1两个簇号,用户的数据从簇2开始分配。
随后FAT表从头开始按3字节分成一组,但是有一点需要特别注意:
在这3个字节中,用第2字节的低半字节和第1字节形成整数表示一个簇号,用第2字节的高半字节和第3字节形成的整数来表示另一个簇号
由上面学习的内容知道,在FAT表中想要开始遍历就必须知道首簇号,而首簇号位于根目录区域中。
计算根目录区的起始位置为:[ 1(Boot区扇区数)+2(FAT数目)*9(FAT扇区数)] * 512 = 0x2600
每一条记录,从该记录开始偏移0xB处有个字节指示出文件的类型,对于多级目录来说,则是存放在数据区内,原理和根目录查找目录类似,只不过是多层嵌套,查找到的是另一个目录表。
查找a:\tem\tem.txt为例:
如何恢复只有一个簇的文件?
文件内容不会因删除而改动。而对应文件的项只是将第一个字节改成E5,其首簇段的值也不会该动
在目录表中找到E5开始的相关文件名,从该项的首簇字段(0x1A)获得首簇,然后,在FAT表中对应的簇项改成FFF即可
FAT12和FAT32的区别
- FAT32的一个重要不同在于取消了根目录区,根目录在用户区,且FAT32引导记录中有一个指向根目录区的首簇字段
- fat32支持长文件名而fat12不支持(FAT12文件名固定11字节,其中3字节用于后缀)
- fat12一个表项占1.5个字节而fat32一个表项占4个字节
- fat32有保留区而fat12没有
- FAT32的记录项中的首簇号,由两个字段构成,分别代表高位两字节和低位两字节
硬盘数据结构
MBR和EBR
扩展分区核心思想是:形成一个分区链,MBR定义的主分区表本来有4条分区记录,用一条描述自己分区的信息,用剩余的指向下一个分区。
为了完全兼容MBR的格式,EBR完全复用了引导扇区的格式,即起始446字节给引导记录EBR,但在EBR中,这些内容全为0。
主分区的相对扇区相对于MBR,通过MBR和相对扇区就可以定位每一个主分区
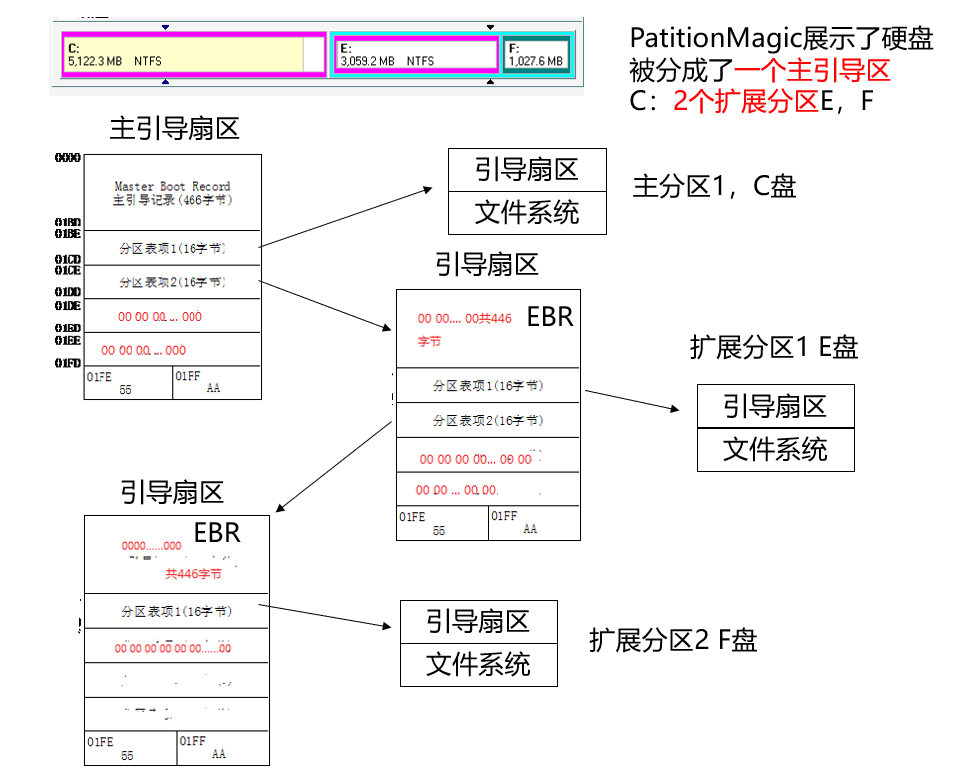
首先找到C盘,找到主引导扇区的分区表,找到分区的相对偏移扇区数,扩展分区1是MBR的主扩展分区,它的EBR放在主扩展分区的开始处
找到扩展分区1的EBR。
随后查找扩展分区1上的基本分区E盘,
同理查找扩展分区2的EBR和分区表
最后利用相对偏移字段和首部偏移查找F盘的起始位置
注意EBR是相对于包含该分区表的扩展区开始处而言(扩展分区开始处为其EBR),在扩展分区的分区表中,第一项的偏移指向的是盘区,第二项的偏移指向的是下一个扩展分区开始处(也就是下一个扩展分区的EBR)
硬盘的引导过程
分区表项的第一个字节0x80表示激活
- 开机加电自检:开机,CPU跳到内存FFFF:0000处,由该处的一条JMP指令跳到BIOS的自检程序(POST),自检通过后,加载引导程序(与操作系统无关的MBR,按用户在BIOS中的指定顺序,硬盘、软盘、光驱或U盘等
- 读主引导扇区:将主引导扇区MBR读入到内存的0000:7C00,扫描主分区表,搜索激活分区,分区表项第一个字节为0x80表示激活分区
- 读激活分区引导扇区 :如果有多个激活分区或没有,报错结束。否则读取激活分区引导扇区到0000:7c00
- 操作系统引导代码引导系统并读取操作系统初始化文件
MBR代码拷贝的问题
MBR的这段代码会被加载到7C00处,这段代码的主要任务是什么呢?是找到激活分区(如C盘)并将真正C盘的引导扇区加载到7C00处(也就是拷贝),这必然覆盖已经在内存7C00处的MBR自己,当自己正在拷贝的另外的指令覆盖自己时,必然破坏了自己的指令执行逻辑。
所以,要错开MBR引导程序和激活分区引导程序占用的内存空间范围,让MBR的引导程序在600h执行,而它拷贝的激活分区引导程序将在7C00h执行
头插入病毒遇到的问题
需要去掉病毒代码最后的RET指令,否则原本的COM文件得不到执行机会
病毒代码执行结束后需用一条JMP指令跳过病毒数据区
加载后的实际内存位置后移, 后移长度就是virus.com的机器码长度
将源程序复制到原先的位置时候需要避免自我覆盖
尾插入中的思路
1) 构造一个打印的正常代码normal.com
2)构造一个寄生在normal.com尾部的病毒代码virus.com
3)用DOS的拷贝命令将两个编译好的程序粘起来
4)将normal.com开始的3字节作为数据保存到virus.com的代码某部分,然后将normal.com开始的3字节修改(先用UE手动修改)为JMP XXXX(跳到virus.com指令处)。
5)virus.com打印“I am virus”后,将normal.com开始的3字节进行还原,并JMP到normal.com开始,将执行权限交给normal.com
为什么计算机病毒往往需要重定位技术?病毒重定位技术的关键技术原理是什么?以下重定位代码中,语句(1)-(4)在变量Message重定位过程中发挥的作用分别是什么?
(1) call base
base:
(2) pop bp
(3) sub bp, base
mov ax, bp
(4) add ax, Message病毒的寄生会导致指令所在位置发生变化,从而导致预期加载地址和实际地址不一致的情况;知道一条指令运行时的地址值和编译时的地址值,相减即可;
Call指令的下一条指令是pop ax,call执行时,首先会把pop ax指令的IP(即pop ax这条指令的实际地址)压栈,然后根据相对偏移跳到标号here处;
标号base处就是pop bp指令,执行这条出栈指令会把栈中数据放入bp中,也就是pop bp指令的IP,利用栈获得了IP的值
Sub语句中的标号base在编译时就生成了地址,但是是预期地址,现在,实际地址-预期地址,ax中放的就是加载偏差了
将编译期要用的的地址,比如字串的首址加上ax就是字串实际地址了
逆插入病毒
与前面不同,我们需要添加一段完成感染寄生的代码,但这段代码自身不寄生在原文件上,它只需要完成以下功能:
1.把正常程序向后拷贝HdrVirus长度
2.把HdrVirus部分拷贝到前面
3.把EndVirus部分拷贝到后面
头病毒部分因为存在加载偏差,需要重定位,并且需要为尾病毒拷贝设置参数.
重定位有关的代码在头病毒部分已经设置完成,因此不需要额外设置.
感染部分思路
1 )获取原文件大小,后续写入需要
-———————————————
2 )将原文件扩容,增加hdrvirusSize(头病毒部分长度)个字节,通过在原文件的尾部写字节完成
-———————————————
3 )原文件向后拷贝hdrvirusSize长度,腾出空间给头病毒部分。注意:原文件应从尾至头完成拷贝,如果采取从头至尾的拷贝,则当原文件大小>移动长度时,就会产生覆盖
-———————————————
4)将HdrVirus部分写入头部
-———————————————
5)将EndVirus部分写入尾部
不用事先扩容,写直接完成扩容
引导型病毒
执行过程:病毒先把自己加载到7C00h,然后又把原引导程序拷贝到7C00h,这个过程会出现什么问题?就是前面遇见的自我覆盖问题,所以需要将病毒中执行拷贝的指令段移出被覆盖的区域。我们可以将它后移一个扇区7e00h处
感染过程:感染会将原引导扇区的内容一直放到簇2,如何避免后续使用占用簇2,破坏了病毒的逻辑?可以修改FAT1和FAT2表,将簇2的项改成不可使用,如果改为已占用FFF,但却没有对应的目录项,是可疑的,因此,可以改为坏簇FF7,从而防止别人使用它。这些感染,为了简单,没有采用汇编访问硬盘的方式,而是采用C语言来直接修改软盘文件。
中断替换
病毒篡改中断向量表内容指向Hook,Hook函数执行完自己的逻辑后在正常跳回到中断处理程序处,并将原地址协会中断向量表中,当病毒和中断向量表在不同的段时,约定AX放段内偏移,CX放段地址。若需要内存驻留则直接调用DOS提供的驻留退出中断int 27h
链式病毒思路
病毒在感染时,完全不改变宿主程序本体,而是改动或利用与宿主程序相关的信息,将病毒程序与宿主程序连成一体。
一、感染部分
- 被感染文件的真实起始扇区号写到
目录表项的保留区(目录项的保留区从目录项头第13个字节即偏移0ch开始,共10字节)- 修改被感染文件的目录项的
起始扇区字段指向病毒文件的首簇- 目录项中的
文件大小字段也要修改成病毒的真实大小,这样才能保证病毒能被完整加载- 将原来病毒文件的目录项全部32字节改为0,这样从外部看就不存在这个病毒文件,也没有对应的目录项了
二、执行部分
- 病毒运行后,先获取被
感染程序的名字- 然后从根目录寻找
被感染程序的目录项- 找到后从该目录项的保留区获取
被感染程序的首簇号- 找到被感染程序所在簇(即扇区),加载该扇区到内存
PE结构,如何从一个PE文件中找到程序入口的文件地址的方法
寻找可选头中的 AddressOfEntryPoint,利用RVA找到该值所属的节,如果该节的起始RVA和该节的起始文件偏移相等则直接作为偏移,否则利用偏移量计算出新的值
(入口点的RVA(AddressOfEntryPoint)- 节的RVA = 入口点的FOA - 节的起始文件位置(PointerToRawData) )
随后寻找可选头中另外一个字段ImageBase,即程序约定加载地址,该地址加上入口点偏移
程序入口地址VA:ImageBase+AddressOfEntryPoint
RVA和FOA的联系与区别
- RVA是内存的相对位置,相对的是加载到内存的基地地址
- FOA是文件中的相对位置,相对的是文件开始位置(即0)
用程序完成末段大小不变的寄生
生成需要寄生的病毒代码
获得被感染文件的NT头
- 利用DOS头的e_lfanew字段(文件定位)
- 定位NT头,读到ntHrds(文件定位读)
找到最后一个节判断是否具有空洞
如何判断节是否有空洞?
virtualSize < SizeofRawData
这些信息在哪里?
最后一个节的节表项中
当前的文件指针在什么地方?
之前读了NT头,现在在NT头的后面也就是节表的起始文件位置
修改最后一个节VirtualSize写入病毒
修改SizeofImage和EntryPoint
入口点模糊技术(Entry Point Obscuring)
每个节的节表项有一个characteristics属性,说明了该节是干什么的,当IMAGE_SCN_CNT_CODE为20时说明是代码节. EPO技术能够让病毒代码隐藏自己入口点,避免被查杀,使得被病毒修改后的入口点看起来依然就像是正常的入口点.
解决入口点不在代码段的问题,我们可以采用下2种解决方法:
1)不感染最后一节,直接感染代码节,病毒代码附着在代码节的尾部,再修改入口点。这样虽然修改了入口点,但让入口点处于代码节
2)不修改入口点,但将入口点所在的指令替换成一条JMP指令,跳往到寄生的病毒代码
感染在代码节的空洞
生成需要寄生的病毒代码
获得被感染文件的NT头
找到代码节并判断是否具有空洞
如何找到代码节?遍历所有节表项并判断节表项的属性是否有20属性
修改VirtualSize写入病毒
修改SizeofImage和EntryPoint
感染最后节并替换入口指令
- 修改原入口点的数据为JMP指令
- 保存被覆盖的5个字节
- 执行逻辑
- 恢复这5个字节
- 源地址就是被覆盖的5个字节,放在数据区,所以我们把可以把数据区的起始地址也作为数据放入数据区
- 目的地址是原程序的入口点地址,寄生后,病毒的main函数就结束了,所以这个入口点地址也需要写入数据区时
- 最后一条JMP跳回原入口点
ImageBase是程序预期加载的基地址,win7系统和vs编译器往往都采用了随机地址空间技术,使得程序即每次加载的实际地址并不是ImageBase,原文件有重定位表这样的机制帮助重定位,但病毒只能利用前面我们学到的自定位技术原理。
病毒真正获取API函数地址的方法
一、获取DLL基址
只有找到DLL基地址,我们才能找到它的导出表,才能找到所要调用函数的地址,利用PEB结构(Process Environment Block,进程环境块)查找,每个进程都对应一个PEB。然后,PEB结构保存着另外一个指针,该指针指向一个叫PEB_LDR_DATA的结构
这个PEB_LDR_DATA 偏移0C处是加载模块链表的头指针,由8个字节组成,前4个字节指向一个LDR_MODULE结构体(LDR_MDOULE代表一个模块,每一个模块(exe,dll)都对应一个这样的结构体),在该LDR_MODULE中,头4字节又指向下一个加载的LDR_MODULE结构体,由此组成链表。
在win7下,第一个加载的模块是是执行程序本身,第2个是NTDll,第3个就是kernel32,在结构体偏移0x18处就是所对应模块的基址。
那如何在遍历的过程中识别模块呢?
在LDR_MODULE结构体偏移0x2C的地方,有一个成员BaseDllName,它有8个字节,其中后4字节为地址,指向一个unicode串(每个字符占2个字节),这个unicode串就是不包含路径的纯模块名。
遍历的结束条件是什么?Next指针为0或者ffffffff么?都不是,过调试我们可以发现,在win7下,加载模块链形成了一个循环链表,因此只要发现next块的头4字节是头块地址就停止遍历。
二、获取DLL中的函数地址
找到基址后,我们必须手动完成由函数名获取其所在DLL中地址的过程,我们需要从DLL的实际基址入手,解析DLL的导出表,获取相关函数的入口地址。
导出表—DLL对外暴露函数地址的机制
序号查找
序号查找的好处:快!高效!
我们可以用一个简单的hash完成,而不需要遍历,如果我们用一个数组(funcEntryTb)存储函数的入口地址。第0号函数的入口地址就存入数组的第一个元素funcEntryTb[0],第1号函数的就存入数组的第2个元素funcEntryTb[1]。这样获取入口地址非常简单 ,即funcEntryTb[n],n是函数的序号,也就是拿到数组首址funcEntryTb加偏移n*4(每个地址4个字节)即可。类似DOS下的中断向量表。
如果序号不是从0开始,而是从n开始,我们依然是将n对应函数的入口地址存入第一个元素,依次类推。获取第M(M肯定大于n,因为n最小)号函数的地址如下: funcEntryTb[m - n]。依然非常快速,计算次数固定,即拿到首址funcEntryTb,做一次减法m-n,再做一次乘法(m - n)*4就获取到元素的地址,取出其值保存值即可。这其实也是c语言switch语句出来case中序号和case分支入口地址的方法,所以一般switch比if else嵌套快
但是序号查找不够直观,同时也不够稳定
用函数名查找
用函数名查找:直观!具体!
最简单的办法就是一个一个函数名字串比较,找到相同的串。下面给出一个简单实现:函数名表的索引和函数地址表的索引是一一对应的。如果查找func2函数地址,我们先遍历函数名表,每遇到\0就是一个串,自然,在第2串处找到了字串func2,fun2是函数名表第2项,索引为1,然后我们用索引1在函数地址表中获得了address2,函数地址表4字节一个元素通过两个表相同的索引建立关联。
导出函数查找算法
从DLL加载的实际基址获取可选头,从其中数据目录表的第一项找到导出表入口RVA
从导出表的表头获取Number of names,即查找的最大循环次数
循环遍历函数名指针表,比对每项RVA指向的字串是否为要找的函数名
函数名指针表1项4字节 à 对应的字符串地址如果找到,记下此时函数名指针表项的索引,设为 i
根据索引 i,在序号表中找到对应项,获取其内容为n
序号表1项2字节以n为索引在函数地址表中找到函数入口的RVA,加上DLL的实际基址即为函数的实际入口地址
地址表1项4字节注:以上算法中,所有访问实际地址的地方,就用
DLL的实际加载基址+RVA即可
导入表机制
RVA指向导入表(IMPORT DICTORY TABLE)起始,在这个地方,每一项是一个IMAGE_IMPORT_DESCRIPTOR结构,代表一个导入的DLL的相关信息。在这个结构中,又有:
INT表(Import Name Table)和IAT表(Import Address Table)的RVA
如何找到需要Patch的指令
- 在文件中找到导入表的位置:先找到导入表的RVA,将RVA转换为导入表的文件位置
- 找到指定API函数在IAT表中的表项地址。先要找到API所在DLL对应的项,然后才能找到这个DLL所对应的INT和IAT表,比较dll的名字,判断是否是API函数所在DLL的导出表目录项,然后根据预先绑定,如果有INT就用INT表来找函数名,没有就用IAT表找函数名,获得INT表(或IAT表)的RVA,并将其转换为文件位置,遍历INT表(或IAT表)的每一项,查找指定的API函数名。
- 找到符合的指令进行Patch,先找到代码所在的节,判断节的属性是否有0x20,找到后开始循环遍历每个字节进行替换,并写入patch指令。

![[漫语]葬送的芙莉莲](medias/imgs/52979/1.png)