内核是如何发送网络包的
1)网络包发送过程总览
int main() {
fd = socket(AF_INET, SOCK_STREAM, 0);
bind(fd, ...);
listen(fd, ...);
cfd = accept(fd, ...);
// 接收用户请求
read(cfd, ...);
// 用户请求处理
dosomething();
// 给用户返回结果
send(cfd, buf, sizeof(buf), 0);
}上述代码中,调用send之后内核是怎样把数据包发送出去的?
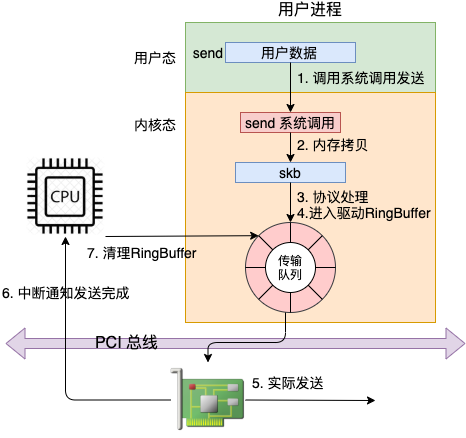
如上图所示,可以看到用户数据被拷贝到内核态,然后经过协议栈处理后进入RingBuffer。随后网卡驱动真正将数据发送了出去。当发送完成的时候,是通过硬中断来通知CPU,然后清理RingBuffer。
总体的流程图如下:
虽然数据这时已经发送完毕,但是其实还有一件重要的事情没有做,那就是释放缓存队列等内存。
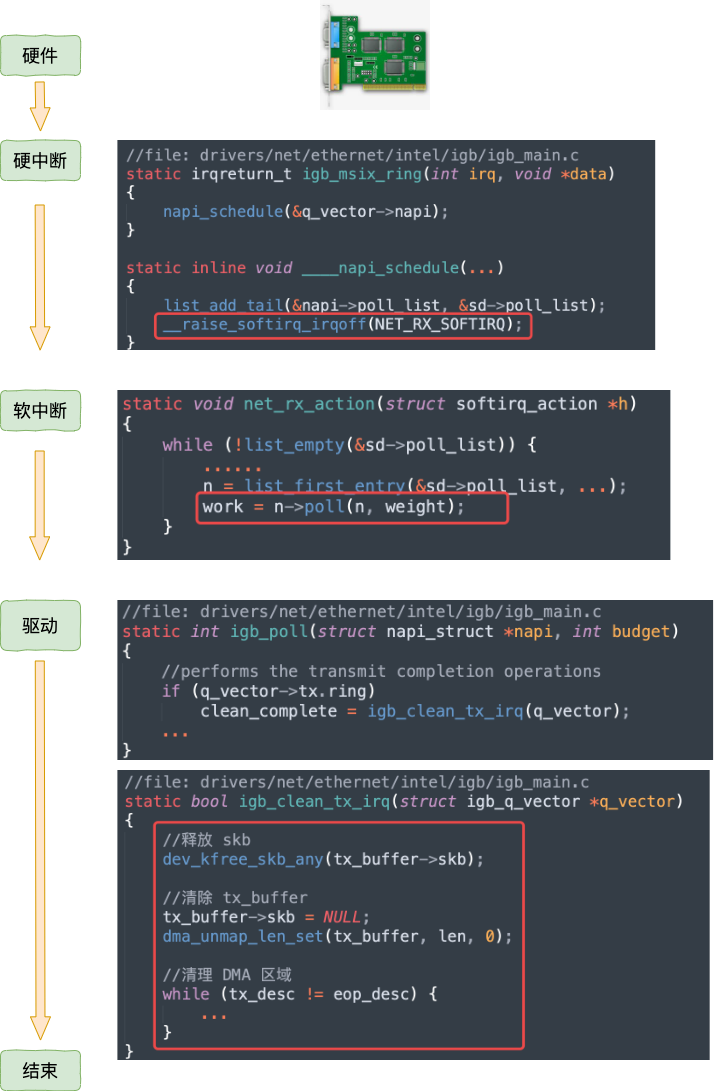
那内核是如何知道什么时候才能释放内存的呢,当然是等网络发送完毕之后。网卡在发送完毕的时候,会给 CPU 发送一个硬中断来通知 CPU。更完整的流程看图:
2)网卡启动准备
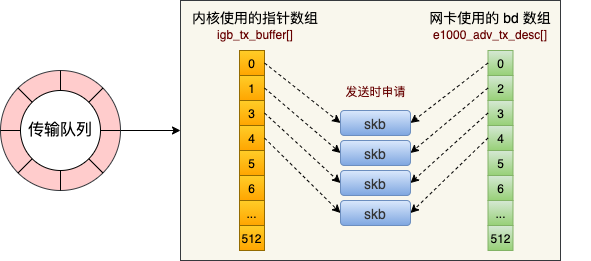
现在的服务器上的网卡一般都是支持多队列的。每一个队列都是由一个RingBuffer表示的,开启了多队列以后的网卡就会对应有多个RingBuffer,如下图所示:
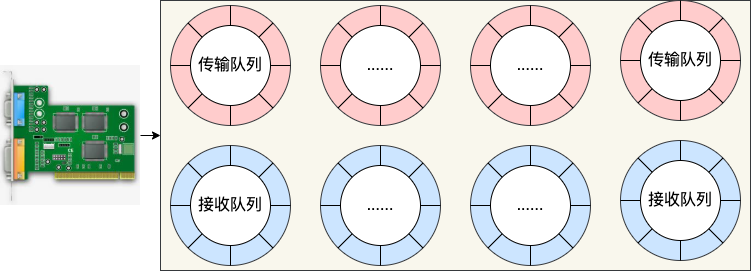
网卡在启动时最重要的任务之一就是分配和初始化RingBuffer,接下来看看网卡启动时分配传输队列RingBuffer的实际过程。在网卡启动的时候,会调用__igb_open函数,RingBuffer就是在这里分配的
// drivers/net/ethernet/intel/igb/igb_main.c
static int __igb_open(struct net_device *netdev, bool resuming)
{
struct igb_adapter *adapter = netdev_priv(netdev);
...
// 分配传输描述符数组
err = igb_setup_all_tx_resources(adapter);
...
// 分配接收描述符数组
err = igb_setup_all_rx_resources(adapter);
...
// 开启全部队列
netif_tx_start_all_queues(netdev);
...
}上面的__igb_open函数调用igb_setup_all_tx_resources分配所有的传输RingBuffer,调用igb_setup_all_rx_resources分配所有的接收RingBuffer
// drivers/net/ethernet/intel/igb/igb_main.c
static int igb_setup_all_tx_resources(struct igb_adapter *adapter)
{
...
// 有几个队列就构造几个RingBuffer
for (i = 0; i < adapter->num_tx_queues; i++) {
err = igb_setup_tx_resources(adapter->tx_ring[i]);
...
}
...
}真正的RingBuffer构造过程是在igb_setup_tx_resources中完成的
// drivers/net/ethernet/intel/igb/igb_main.c
int igb_setup_tx_resources(struct igb_ring *tx_ring)
{
// 1.申请igb_tx_buffer数组内存
size = sizeof(struct igb_tx_buffer) * tx_ring->count;
tx_ring->tx_buffer_info = vzalloc(size);
...
// 2.申请e1000_adv_tx_desc DMA数组内存
tx_ring->size = tx_ring->count * sizeof(union e1000_adv_tx_desc);
tx_ring->size = ALIGN(tx_ring->size, 4096);
tx_ring->desc = dma_alloc_coherent(dev, tx_ring->size,
&tx_ring->dma, GFP_KERNEL);
...
// 3.初始化队列成员
tx_ring->next_to_use = 0;
tx_ring->next_to_clean = 0;
...
}从上述源码可以看到,一个传输RingBuffer的内部也不仅仅是一个环形队列数组:
igb_tx_buffer数组:这个数组是内核使用的,通过vzalloc申请e1000_adv_tx_desc数组:这个数组是网卡硬件使用的,通过dma_alloc_coherent分配
这个时候它们之间还没有啥联系。将来在发送的时候,这两个环形数组中相同位置的指针将都将指向同一个 skb。这样,内核和硬件就能共同访问同样的数据了,内核往 skb 里写数据,网卡硬件负责发送。
最后调用netif_tx_start_all_queues开启队列。另外,硬中断的处理函数igb_msix_ring其实也是在__igb_open中注册的
3)数据从用户进程到网卡的详细过程
1)send系统调用实现
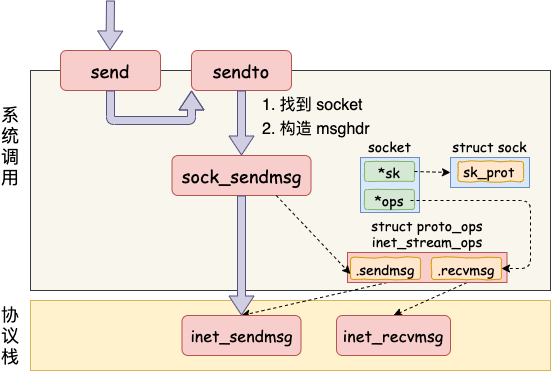
send系统调用的源码位于net/socket.c中。在这个系统调用里,内部其实真正使用的是sendto系统调用。主要干了两件事情:
- 在内核中把真正的socket找出来,在这个对象里记录着各种协议栈的函数地址
- 构造一个struct msghdr对象,把用户传入的数据,比如buffer地址、数据长度什么的,都装进去
有了上面的了解,我们再看起源码就要容易许多了。源码如下:
//file: net/socket.c
SYSCALL_DEFINE4(send, int, fd, void __user *, buff, size_t, len,
unsigned int, flags)
{
return sys_sendto(fd, buff, len, flags, NULL, 0);
}
SYSCALL_DEFINE6(......)
{
//1.根据 fd 查找到 socket
sock = sockfd_lookup_light(fd, &err, &fput_needed);
//2.构造 msghdr
struct msghdr msg;
struct iovec iov;
iov.iov_base = buff;
iov.iov_len = len;
msg.msg_iovlen = 1;
msg.msg_iov = &iov;
msg.msg_flags = flags;
......
//3.发送数据
sock_sendmsg(sock, &msg, len);
}从源码可以看到,我们在用户态使用的 send 函数和 sendto 函数其实都是 sendto 系统调用实现的。send 只是为了方便,封装出来的一个更易于调用的方式而已。在 sendto 系统调用里,首先根据用户传进来的 socket 句柄号来查找真正的 socket 内核对象。接着把用户请求的 buff、len、flag 等参数都统统打包到一个 struct msghdr 对象中。
接着调用了 sock_sendmsg => sock_sendmsg ==> __sock_sendmsg_nosec。在sock_sendmsg_nosec 中,调用将会由系统调用进入到协议栈,我们来看它的源码。
//file: net/socket.c
static inline int __sock_sendmsg_nosec(...)
{
......
return sock->ops->sendmsg(iocb, sock, msg, size);
}2)传输层处理
传输层拷贝
在进入协议栈inet_sendmsg以后,内核接着会找到socket上的具体协议发送函数。对于TCP协议来说,那就是tcp_sendmsg(同样也是通过socket内核对象找到的)
在这个函数中,内核会申请一个内核态的skb内存,将用户待发送的数据拷贝进去。注意,这个时候不一定会真正开始发送,如果没有达到发送条件,很可能这次调用直接就返回了,大概过程如下图所示:
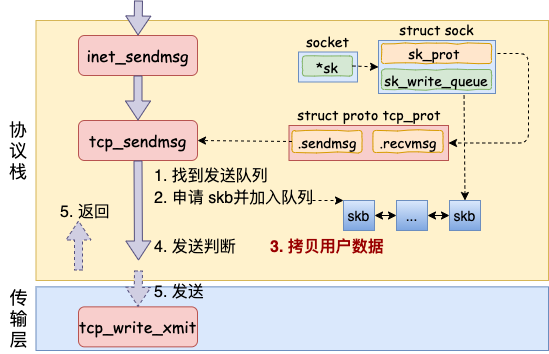
在进入协议栈inet_sendmsg以后,内核接着会找到sock中具体的协议处理函数,对于TCP协议而言,sk_prot操作函数集实例为tcp_prot,其中.sendmsg的实现为tcp_sendmsg(对于UDP而言中的为udp_sendmsg)。
int inet_sendmsg(......)
{
......
return sk->sk_prot->sendmsg(iocb, sk, msg, size);
}
int tcp_sendmsg(......)
{
......
// 获取用户传递过来的数据和标志
iov = msg->msg_iov; // 用户数据地址
iovlen = msg->msg_iovlen; // 数据块数为1
flags = msg->msg_flags; // 各种标志
copied = 0; // 已拷贝到发送队列的字节数
// 遍历用户层的数据块
while(--iovlen >= 0) {
// 待发送数据块的长度
size_t seglen = iov->len;
// 待发送数据块的地址
unsigned char __user *from = iov->iov_base;
// 指向下一个数据块
iovlen++;
......
while(seglen > 0) {
int copy = 0;
int max = size_goal; // 单个skb最大的数据长度
skb = tcp_write_queue_tail(sk); // 获取发送队列最后一个skb
// 用于返回发送队列第一个数据包,如果不是NULL说明还有未发送的数据
if(tcp_send_head(sk)) {
...
copy = max - skb->len; // 该skb还可以存放的字节数
}
// 需要申请新的skb
if(copy <= 0) {
// 发送队列的总大小大于等于发送缓存的上限,或尚发送缓存中未发送的数据量超过了用户的设置值,进入等待
if(!sk_stream_memory_free(sk)) {
goto wait_for_sndbuf;
}
// 申请一个skb
skb = sk_stream_alloc_skb(sk, select_size(sk, sg), sk->sk_allocation);
...
// 把skb添加到sock的发送队列尾部
skb_entail(sk, skb);
}
if(copy > seglen)
copy = seglen;
// skb的线性数据区中有足够的空间
if(skb_availroom(skb)) > 0) {
copy = min_t(int, copy, skb_availroom(skb));
// 将用户空间的数据拷贝到内核空间,同时计算校验和
err = skb_add_data_nocache(sk, skb, from, copy);
if(err)
goto do_fault;
}
// 线性数据区用完,使用分页区
else{
...
}这个函数的实现逻辑比较复杂,代码总只显示了skb拷贝的相关部分,总体逻辑如下:
- 如果使用了TCP Fast Open,则会在发送SYN包的同时带上数据
- 如果连接尚未建好,不处于ESTABLISHED或者CLOSE_WAIT状态则进程进入睡眠,等待三次握手的完成
- 获取当前的MSS(最大报文长度)和size_goal(一个理想的TCP数据包大小,受MTU、MSS、TCP窗口大小影响)
- 如果网卡支持GSO(利用网卡分片),size_goal会是MSS的整数倍
- 遍历用户层的数据块数组
- 获取发送队列的最后一个skb,如果是尚未发送的,且长度未到达size_goal,那么向这个skb继续追加数据
- 否则申请一个新的skb来装载数据
- 如果发送队列的总大小大于等于发送缓存的上限,或者发送缓存中尚未发送的数据量超过了用户的设置值:设置发送时发送缓存不够的标志,进入等待
- 申请一个skb,其线性区的大小为通过select_size()得到的线性数据区中TCP负荷的大小和最大的协议头长度,申请失败则等待可用内存
- 前两步成功则更新skb的TCP控制块字段,把skb加入发送队列队尾,增加发送队列的大小,减少预分配缓存的大小
- 将数据拷贝至skb中
- 如果skb的线性数据区还有剩余,就复制到线性数据区同时计算校验和
- 如果已经用完则使用分页区
- 检查分页区是否有可用空间,没有则申请新的page,申请失败则说明内存不足,之后会设置TCP内存压力标志,减小发送缓冲区的上限,睡眠等待内存
- 判断能否往最后一个分页追加数据,不能追加时,检查分页数是否已经达到了上限或网卡是否不支持分散聚合,如果是的话就将skb设置为PSH标志,然后回到4.2中重新申请一个skb来继续填装数据
- 从系统层面判断此次分页发送缓存的申请是否合法
- 拷贝用户空间的数据到skb的分页中,同时计算校验和。更新skb的长度字段,更新sock的发送队列大小和预分配缓存
- 如果把数据追加到最后一个分页了,更新最后一个分页的数据大小。否则初始化新的分页
- 拷贝成功后更新:发送队列的最后一个序号、skb的结束序号、已经拷贝到发送队列的数据量
- 发送数据
- 如果所有数据都拷贝好了就退出循环进行发送
- 如果skb还可以继续装填数据或者发送的是带外数据那么就继续拷贝数据先不发送
- 如果为发送的数据已经超过最大窗口的一半则设置PUSH标志后尽可能地将发送队列中的skb发送出去
- 如果当前skb就是发送队列中唯一一个skb,则将这一个skb发送出去
- 如果上述过程中出现缓存不足,且已经有数据拷贝到发送队列了也直接发送
这里的发送数据只是指调用tcp_push或者tcp_push_one(情况4)或者__tcp_push_pending_frames(情况3)尝试发送,并不一定真的发送到网络(tcp_sendmsg主要任务只是将应用程序的数据封装成网络数据包放到发送队列)。
数据何时实际被发送到网络,取决于许多因素,包括但不限于:
- TCP的拥塞控制算法:TCP使用了复杂的拥塞控制算法来防止网络过载。如果TCP判断网络可能出现拥塞,它可能会延迟发送数据。
- 发送窗口的大小:TCP使用发送窗口和接收窗口来控制数据的发送和接收。如果发送窗口已满(即已发送但未被确认的数据量达到了发送窗口的大小),那么TCP必须等待接收到确认信息后才能发送更多的数据。
- 网络设备(如网卡)的状态:如果网络设备繁忙或出现错误,数据可能会被暂时挂起而无法立即发送。
struct sk_buff(常简称为skb)在Linux网络栈中表示一个网络包。它有两个主要的数据区用来存储数据,分别是线性数据区(linear data area)和分页区(paged data area)。
- 线性数据区(linear data area): 这个区域连续存储数据,并且能够容纳一个完整的网络包的所有协议头,比如MAC头、IP头和TCP/UDP头等。除了协议头部,线性数据区还可以包含一部分或全部的数据负载。每个skb都有一个线性数据区。
- 分页区(paged data area): 一些情况下,为了优化内存使用和提高性能,skb的数据负载部分可以存储在一个或多个内存页中,而非线性数据区。分页区的数据通常只包含数据负载部分,不包含协议头部。如果一个skb的数据全部放入了线性数据区,那么这个skb就没有分页区。
这种设计的好处是,对于大的数据包,可以将其数据负载部分存储在分页区,避免对大块连续内存的分配,从而提高内存使用效率,减少内存碎片。另外,这种设计也可以更好地支持零拷贝技术。例如,当网络栈接收到一个大数据包时,可以直接将数据包的数据负载部分留在原始的接收缓冲区(即分页区),而无需将其拷贝到线性数据区,从而节省了内存拷贝的开销。
传输层发送
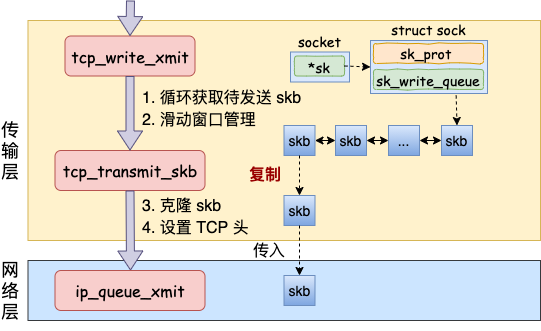
上面的发送数据步骤,不论是调用__tcp_push_pending_frames还是tcp_push_one,最终都会执行到tcp_write_xmit(在网络协议中学到滑动窗口、拥塞控制就是在这个函数中完成的),函数的主要逻辑如下:
- 如果要发送多个数据段则先发送一个路径mtu探测
- 检测拥塞窗口的大小,如果窗口已满(通过窗口大小-正在网络上传输的包数目判断)则不发送
- 检测当前报文是否完全在发送窗口内,如果不是则不发送
- 判断是否需要延时发送(取决于拥塞窗口和发送窗口)
- 根据需要对数据包进行分段(取决于拥塞窗口和发送窗口)
- tcp_transmit_skb发送数据包
- 如果push_one则结束循环,否则继续遍历队列发送
- 结束循环后如果本次有数据发送,则对TCP拥塞窗口进行检查确认
这里我们只关注发送的主过程,其他部分不过多展开,即来到tcp_transmit_skb函数
static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it, gfp_t gfp_mask)
{
// 1.克隆新的skb出来
if(likely(clone_it)) {
skb = skb_clone(skb, gfp_mask);
......
}
// 2.封装TCP头
th = tcp_hdr(skb);
th->source = inet->inet_sport;
th->dest = inet->inet_dport;
th->window = ...;
th->urg = ...;
......
// 3.调用网络层发送接口
err = icsk->icsk_af_ops->xmit(skb, &inet->cort.fl);
}第一件事就是先克隆一个新的skb,因为skb后续在调用网络层,最后到达网卡发送完成的时候,这个skb会被释放掉。而TCP协议是支持丢失重传的,在收到对方的ACK之前,这个skb不能被删除掉。所以内核的做法就是每次调用网卡发送的时候,实际上传递出去的是skb的一个拷贝。等收到ACK再真正删除。
第二件事是修改skb的TCP头,根据实际情况把TCP头设置好。实际上skb内部包含了网络协议中所有的头,在设置TCP头的时候,只是把指针指向skb合适的位置。后面设置IP头的时候,再把指针挪动一下即可,避免了频繁的内存申请和拷贝,提高效率。
tcp_transmit_skb是发送数据位于传输层的最后一步,调用了网络层提供的发送接口icsk->icsk_Af_ops->queue_xmit()之后就可以进入网络层进行下一层的操作了。
3)网络层发送处理
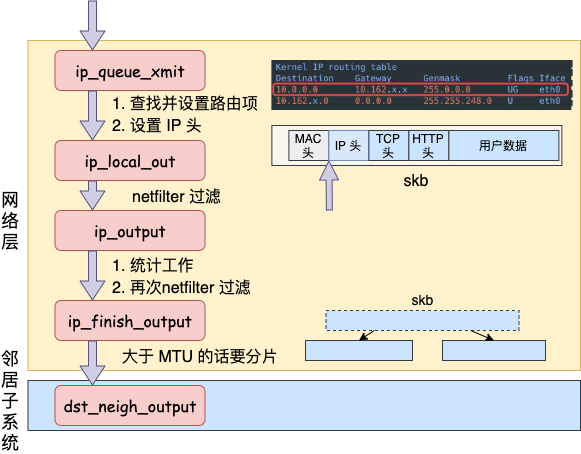
在tcp_ipv4中,queue_xmit指向的是ip_queue_xmit,具体实现如下:
int ip_queue_xmit(struct sk_buff *skb, struct flowi *fl)
{
// 检查socket中是否有缓存的路由表
rt = (struct rtable*)__sk_dst_check(sk, 0);
......
if(rt == null) {
// 没有缓存则展开查找路由项并缓存到socket中
rt = ip_route_output_ports(...);
sk_setup_caps(sk, &rt->dst);
}
// 为skb设置路由表
skb_dst_set_noref(skb, &rt->dst);
// 设置IP头
iph = ip_hdr(skb);
ip->protocol = sk->sk_protocol;
iph->ttl = ip_select_ttl(inet, &rt->dst);
ip->frag_off = ...;
ip_copy_addr(iph, f14);
......
// 发送
ip_local_out(skb);
}这个函数主要做的就是找到该把这个包发往哪,并构造好IP包头。它会去查询socket中是否有缓存的路由表,如果有则直接构造包头,如果没有就去查询并缓存到sokect,然后为skb设置路由表,最后封装ip头,发往ip_local_out函数。
ip_local_out中主要会经过__ip_local_out => nf_hook 的过程进行netfilter的过滤。如果使用iptables配置了一些规则,那么这里将检测到是否命中规则,然后进行相应的操作,如网络地址转换、数据包内容修改、数据包过滤等。如果设置了非常复杂的netfilter规则,则在这个函数会导致进程CPU的开销大增。经过netfilter处理之后,(忽略其他部分)调用dst_output(skb)函数。
dst_output会去调用skb_dst(skb)->output(skb),即找到skb的路由表(dst条目),然后调用路由表的output方法。这里是个函数指针,指向的是ip_output方法。
在ip_output方法中首先会进行一些简单的统计工作,随后再次执行netfilter过滤。过滤通过之后回调ip_finish_output。
在ip_finish_output中,会校验数据包的长度,如果大于MTU,就会执行分片。MTU的大小是通过MTU发现机制确定,在以太网中为1500字节。分片会带来两个问题:
- 需要进行额外的处理,会有性能开销
- 只要一个分片丢失,整个包都要重传
如果不需要分片则调用ip_finish_output2函数,根据下一跳的IP地址查找邻居项,找不到就创建一个,然后发给下一层——邻居子系统。
总体过程如下:
- ip_queue_xmit
- 查找并设置路由项
- 设置IP头
- ip_local_out:netfilter过滤
- ip_output
- 统计工作
- 再次netfilter过滤
- ip_finish_output
- 大于MTU的话进行分片
- 调用ip_finish_output2
4)邻居子系统
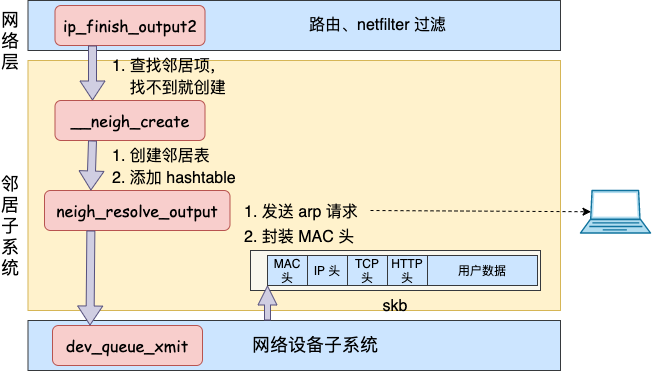
邻居子系统是位于网络层和数据链路层中间的一个系统,其作用是为网络层提供一个下层的封装,让网络层不用关心下层的地址信息,让下层来决定发送到哪个MAC地址。
邻居子系统不位于协议栈net/ipv4/目录内,而是位于net/core/neighbour.c,因为无论对于ipv4还是ipv6都需要使用该模块
在邻居子系统中主要查找或者创建邻居项,在创建邻居项时有可能会发出实际的arp请求。然后封装MAC头,将发生过程再传递给更下层的网络设备子系统。
ip_finish_output2的实现逻辑大致流程如下:
- rt_nexthop:获取路由下一跳的IP信息
- __ipv4_neigh_lookup_noref:根据下一条IP信息在arp缓存中查找邻居项
- __neigh_create:创建一个邻居项,并加入邻居哈希表
- dst_neight_output => neighbour->output(实际指向neigh_resolve_output):
- 封装MAC头(可能会先触发arp请求)
- 调用dev_queue_xmit发送到下层
5)网络设备子系统
邻居子系统通过dev_queue_xmit进入网络设备子系统,dev_queue_xmit的工作逻辑如下
- 选择发送队列
- 获取排队规则
- 存在队列则调用__dev_xmit_skb继续处理
在前面讲过,网卡是有多个发送队列的,所以首先需要选择一个队列进行发送。队列的选择首先是通过获取用户的XPS配置(为队列绑核),如果没有配置则调用skb_tx_hash去计算出选择的队列。接着会根据与此队列关联的qdisc得到该队列的排队规则。
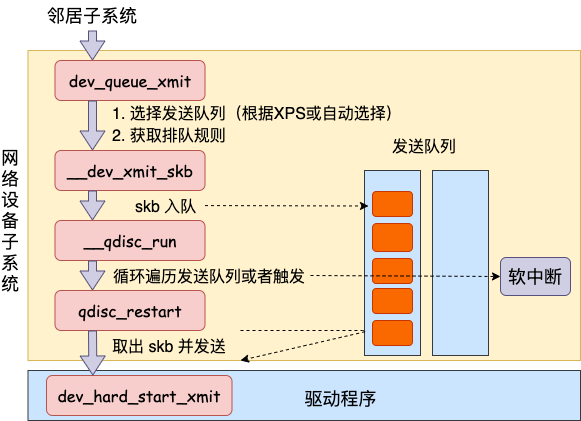
最后会根据是否存在队列(如果是发给回环设备或者隧道设备则没有队列)来决定后续数据包流向。对于存在队列的设备会进入__dev_xmit_skb函数。
在Linux网络子系统中,qdisc(Queueing Discipline,队列规则)是一个用于管理网络包排队和发送的核心组件。它决定了网络包在发送队列中的排列顺序,以及何时从队列中取出包进行发送。qdisc还可以应用于网络流量控制,包括流量整形(traffic shaping)、流量调度(traffic scheduling)、流量多工(traffic multiplexing)等。
Linux提供了许多预定义的qdisc类型,包括:
- pfifo_fast:这是默认的qdisc类型,提供了基本的先入先出(FIFO)队列行为。
- mq:多队列时的默认类型,本身并不进行任何数据包的排队或调度,而是为网络设备的每个发送队列创建和管理一个子 qdisc。
- tbf (Token Bucket Filter):提供了基本的流量整形功能,可以限制网络流量的速率。
- htb (Hierarchical Token Bucket):一个更复杂的流量整形qdisc,可以支持多级队列和不同的流量类别。
- sfq (Stochastic Fairness Queueing):提供了公平队列调度,可以防止某一流量占用过多的带宽。
每个网络设备(如eth0、eth1等)都有一个关联的qdisc,用于管理这个设备的发送队列。用户可以通过tc(traffic control)工具来配置和管理qdisc。
对于支持多队列的网卡,Linux内核为发送和接收队列分别分配一个qdisc。每个qdisc独立管理其对应的队列,包括决定队列中的数据包发送顺序,应用流量控制策略等。这样,可以实现每个队列的独立调度和流量控制,提高整体网络性能。
我们可以说,对于支持多队列的网卡,内核中的每个发送队列都对应一个硬件的发送队列(也就是 Ring Buffer)。选择哪个内核发送队列发送数据包,也就决定了数据包将被放入哪个 Ring Buffer。数据包从 qdisc 的发送队列出队后,会被放入 Ring Buffer,然后由硬件发送到网络线路上。所以,Ring Buffer 在发送路径上位于发送队列之后。
将struct sock的发送队列和网卡的Ring Buffer之间设置一个由qdisc(队列规则)管理的发送队列,可以提供更灵活的网络流量控制和调度策略,以适应不同的网络环境和需求。
下面是一些具体的原因:
- 流量整形和控制:qdisc可以实现各种复杂的排队规则,用于控制数据包的发送顺序和时间。这可以用于实现流量整形(比如限制数据的发送速率以避免网络拥塞)和流量调度(比如按照优先级或服务质量(QoS)要求来调度不同的数据包)。
- 对抗网络拥塞:qdisc可以通过管理发送队列,使得在网络拥塞时可以控制数据的发送,而不是简单地将所有数据立即发送出去,这可以避免网络拥塞的加剧。
- 公平性:在多个网络连接共享同一个网络设备的情况下,qdisc可以确保每个连接得到公平的网络带宽,而不会因为某个连接的数据过多而饿死其他的连接。
- 性能优化:qdisc可以根据网络设备的特性(例如,对于支持多队列(Multi-Queue)的网卡)和当前的网络条件来优化数据包的发送,以提高网络的吞吐量和性能。
__dev_xmit_skb分为三种情况:
- qdisc停用:释放数据并返回代码设置为NET_XMIT_DROP
- qdisc允许绕过排队系统&&没有其他包要发送&&qdisc没有运行:绕过排队系统,调用sch_direct_xmit发送数据
- 其他情况:正常排队
- 调用q->enqueue入队
- 调用__qdisc_run开始发送
void __qdisc_run(struct Qdisc *q)
{
int quota = weight_p;
// 循环从队列取出一个skb并发送
while(qdisc_restart(q)) {
// 如果quota耗尽或其他进程需要CPU则延后处理
if(--quota <= 0 || need_resched) {
// 将触发一次NET_TX_SOFTIRQ类型的softirq
__netif_shcedule(q);
break;
}
}
}从上述代码中可以看到,while循环不断地从队列中取出skb并进行发送,这个时候其实占用的都是用户进程系统态时间sy,只有当quota用尽或者其他进程需要CPU的时候才触发软中断进行发送。
这就是为什么服务器上查看/proc/softirqs,一般NET_RX要比NET_TX大得多的原因。对于接收来说,都要经过NET_RX软中断,而对于发送来说,只有系统配额用尽才让软中断上。
这里我们聚焦于qdisc_restart函数上,这个函数用于从qdisc队列中取包并发给网络驱动
static inline int qdisc_restart(struct Qdisc *q)
{
struct sk_buff *skb = dequeue_skb(q);
if (!skb)
return 0;
......
return sch_direct_xmit(skb, q, dev, txq, root_lock);
}首先调用 dequeue_skb() 从 qdisc 中取出要发送的 skb。如果队列为空,返回 0, 这将导致上层的 qdisc_restart() 返回 false,继而退出 while 循环。
如果拿到了skb则调用sch_direct_xmit继续发送,该函数会调用dev_hard_start_xmit,进入驱动程序发包,如果无法发送则重新入队。
即整个__qdisc_run的整体逻辑为:while 循环调用 qdisc_restart(),后者取出一个 skb,然后尝试通过 sch_direct_xmit() 来发送;sch_direct_xmit 调用 dev_hard_start_xmit 来向驱动程序进行实际发送。任何无法发送的 skb 都重新入队,将在 NET_TX softirq 中进行发送。
6)软中断调度
上一部分中如果发送网络包的时候CPU耗尽了,会调用进入netif_schedule,该函数会进入netif_reschedule,将发送队列设置到softnet_data上,并最终发出一个NET_TX_SOFTIRQ类型的软中断。软中断是由内核进程运行的,该进程会进入net_tx_action函数,在该函数中能获得发送队列,并最终也调用到驱动程序的入口函数dev_hard_start_xmit。
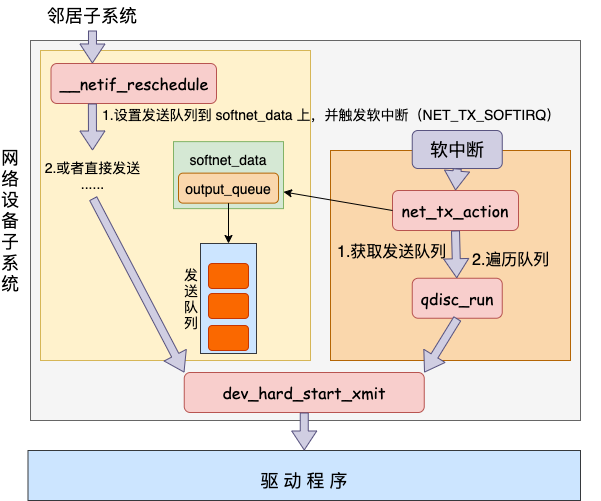
从触发软中断开始以后发送数据消耗的CPU就都显示在si中,而不会消耗用户进程的系统时间
static void net_tx_action(struct softirq_action *h)
{
struct softnet_data *sd = &__get_cpu_var(softnet_data);
// 如果softnet_data设置了发送队列
if(sd->output_queue) {
// 将head指向第一个qdisc
head = sd->output_queue;
// 遍历所有发送队列
while(head) {
struct Qdisc *q = head;
head = head->next_sched;
// 处理数据
qdisc_run(q);
}
}
}
static inline void qdisc_run(struct Qdisc *q)
{
if(qdisc_run_begin(q))
__qdisc_run(q);
}可以看到软中断的处理中,最后和前面一样都是调用了qdisc_run。也就是说不管是在qdisc_restart中直接处理,还是软中断来处理,最终实际都会来到dev_hard_start_xmit(qdisc_run => qdisc_restart => dev_hard_start_xmit)。
7)igb网卡驱动发送
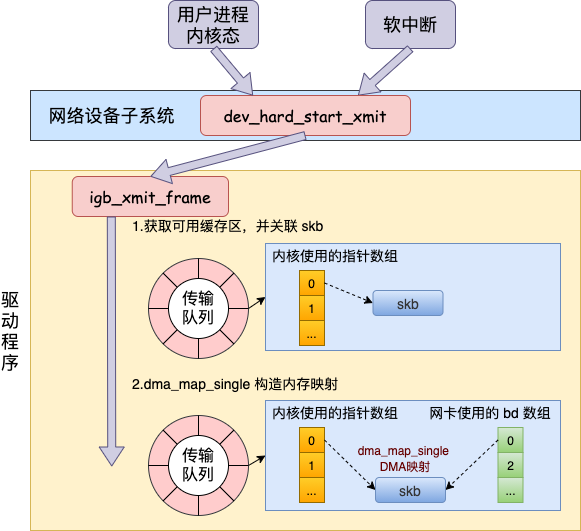
通过前面的介绍可知,无论对于用户进程的内核态,还是对于软中断上下文,都会调用网络设备子系统的dev_hard_start_xmit函数,在这个函数中,会调用驱动里的发送函数igb_xmit_frame。在驱动函数里,会将skb挂到RingBuffer上,驱动调用完毕,数据包真正从网卡发送出去。
int dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev, struct netdev_queue *txq)
{
// 获取设备的回调函数ops
const struct net_device_ops * ops = dev->netdev_ops;
// 获取设备支持的功能列表
features = netif_skb_features(skb);
// 调用驱动的ops里的发送回调函数ndo_start_xmit将数据包传给网卡设备
skb_len = skb->len;
rc = ops->ndo_start_xmit(skb, dev);
}这里ndo_start_xmit是网卡驱动要实现的函数,igb网卡驱动中的实现是igb_xmit_frame(在网卡驱动程序初始化的时候赋值的)。igb_xmit_frame主要会去调用igb_xmit_frame_ring函数
netdev_tx_t igb_xmit_frame_ring(struct sk_buff *skb, struct igb_ring *tx_ring)
{
// 获取TX queue中下一个可用缓冲区的信息
first = &tx_ring->tx_buffer_info[tx_ring->next_to_use];
first->skb = skb;
first->bytecount = skb->len;
first->gso_segs = 1;
// 准备给设备发送的数据
igb_tx_map(tx_ring, first, hdr_len);
}
static void igb_tx_map(struct igb_ring *tx_ring, struct igb_tx_buffer *first, const u8 hdr_len)
{
// 获取下一个可用的描述符指针
tx_desc = IGB_TX_DESC(tx_ring, i);
// 为skb->data构造内存映射,以允许设备通过DMA从RAM中读取数据
dma = dma_map_single(tx_ring->dev, skb->data, size, DMA_TO_DEVICE);
// 遍历该数据包的所有分片,为skb的每个分片生成有效映射
for(frag = &skb_shinfo(skb)->frags[0]; ; flag++){
tx_desc->read.buffer_addr = cpu_to_le64(dma);
tx_desc->read.cmd_type_len = ...;
tx_desc->read.olinfo_status = 0;
}
// 设置最后一个descriptor
cmd_type |= size | IGB_TXD_DCMD;
tx_desc->read.cmd_type_len = cpu_to_le32(cmd_type);
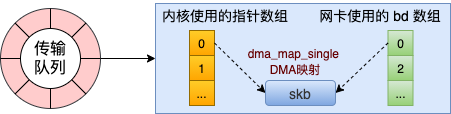
}在这里从网卡的发送队列的RingBuffer上取下来一个元素,并将skb挂到元素上。然后使用igb_tx_map函数将skb数据映射到网卡可访问的内存DMA区域。
这里可以理解为&tx_ring->tx_buffer_info[tx_ring->next_to_use]拿到了RingBuffer发送队列中指针数组(前文提到的igb_tx_buffer,网卡启动的时候创建的供内核使用的数组)的下一个可用的元素,然后为其填充skb、byte_count等数据。
填充完成之后,获取描述符数组(前文提到的e1000_adv_tx_desc,网卡启动的时候创建的供网卡使用的数组)的下一个可用元素。
调用dma_map_single函数创建内存和设备之间的DMA映射,tx_ring->dev是设备的硬件描述符,即网卡,skb->data是要映射的地址,size是映射的数据的大小,即数据包的大小,DMA_TO_DEVICE是指映射的方向,这里是数据将从内存传输到设备,返回的调用结果是一个DMA地址,存储在dma变量中,设备可以直接通过这个地址访问到skb的数据。
最后就是为前面拿到的描述符填充信息,将dma赋值给buffer_addr,网卡使用的时候就是从这里拿到数据包的地址。
当所有需要的描述符都建好,且skb的所有数据都映射到DMA地址后,驱动就会进入到它的最后一步,触发真实的发送。
到目前为止我们可以这么理解:
应用程序将数据发送到 socket,这些数据会被放入与 sock 中的发送队列。然后,网络协议栈(例如 TCP 或 UDP)将这些数据从 socket 的发送队列中取出,往下层封装,然后将这些数据包放入由 qdisc 管理的设备发送队列中。最后,这些数据包将从设备发送队列出队,放置到RingBuffer的指针数组中,通过dma将数据包的地址映射到可供网卡访问的内存DMA区域,由硬件读取后发送到网络上。
4)RingBuffer内存回收
当数据发送完以后,其实工作并没有结束,因为内存还没有清理。当发送完成的时候,网卡设备会触发一个硬中断(硬中断会去触发软中断)来释放内存。
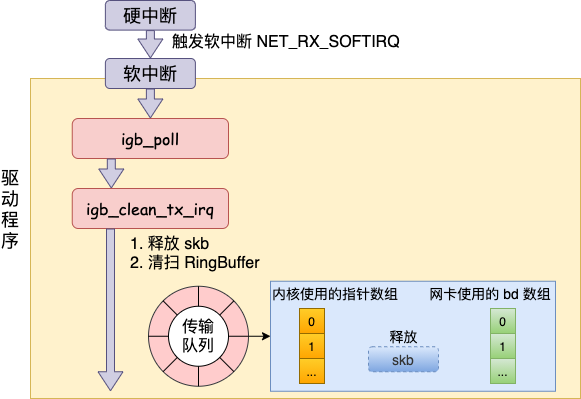
这里需要注意的就是,虽然是数据发送完成通知,但是硬中断触发的软中断是NET_RX_SOFTIRQ,这也就是为什么软中断统计中RX要高于TX的另一个原因。
硬中断中会向softnet_data添加poll_list,软中断中轮询后调用其poll回调函数,具体实现是igb_poll,其会在q_vector->tx.ring存在时去调用igb_clean_tx_irq。
static bool igb_clean_tx_irq(struct igb_q_vector *q_vector)
{
// 释放skb
dev_kfree_skb_any(tx_buffer->skb);
// 清除tx_buffer数据
tx_buffer->skb = NULL;
// 将tx_buffer指定的DMA缓冲区的长度设置为0
dma_unmap_len_set(tx_buffer, len 0);
// 清除最后的DMA位置,解除映射
while(tx_desc != eop_desc) {
}
}其实逻辑无非就是清理了skb(其中data保存的数据包没有释放),解决了DMA映射等,到了这一步传输才算基本完成。
当然因为传输层需要保证可靠性,所以数据包还没有删除,此时还有前面的拷贝过的skb指向它,它得等到收到对方的ACK之后才会真正删除。

问题解答
- 查看内核发送数据消耗的CPU时应该看sy还是si
- 在网络包发送过程中,用户进程(在内核态)完成了绝大部分的工作,甚至连调用驱动的工作都干了。只有当内核态进程被切走前才会发起软中断。发送过程中百分之九十以上的开销都是在用户进程内核态消耗掉的,只有一少部分情况才会触发软中断,有软中断ksoftirqd内核线程来发送。
- 所以在监控网络IO对服务器造成的CPU开销的时候,不能近看si,而是应该把si、sy(内核占用CPU时间比例)都考虑进来。
- 在服务器上查看/proc/softirqs,为什么NET_RX要比NET_TX大得多
- 对于读来说,都是要经过NET_RX软中断的,都走ksoftirqd内核线程。而对于发送来说,绝大部份工作都是在用户进程内核态处理了,只有系统态配额用尽才会发出NET_TX,让软中断处理。
- 当数据发送完以后,通过硬中断的方式来通知驱动发送完毕。但是硬中断无论是有数据接收还是发送完毕,触发的软中断都是NET_RX_SOFTIRQ而不是NET_TX_SOFTIRQ。
- 发送网络数据的时候都涉及那些内存拷贝操作
- 这里只指内存拷贝
- 内核申请完skb之后,将用户传递进来的buffer里的数据拷贝到skb。如果数据量大,这个拷贝操作还是开销不小的。
- 从传输层进入网络层时。每个skb都会被克隆出一个新的副本,目的是保存原始的skb,当网络对方没有发挥ACK的时候还可以重新发送,易实现TCP中要求的可靠传输。不过这次只是浅拷贝,只拷贝skb描述符本身,所指向的数据还是复用的。
- 第三次拷贝不是必须的,只有当IP层发现skb大于MTU时才需要进行,此时会再申请额外的skb,并将原来的skb拷贝成多个小的skb。
- 零拷贝到底是怎么回事
- 如果想把本机的一个文件通过网络发送出去,需要先调用read将文件读到内存,之后再调用send将文件发送出去
- 假设数据之前没有读去过,那么read系统调用需要两次拷贝才能到用户进程的内存。第一次是从硬盘DMA到Page Cache。第二次是从Page Cache拷贝到内存。send系统调用也同理,先CPU拷贝到socket发送队列,之后网卡进行DMA拷贝。
- 如果要发送的数据量较大,那么就需要花费不少的时间在数据拷贝上。而sendfile就是内核提供的一个可用来减少发送文件时拷贝开销的一个技术方案。在sendfile系统调用里,数据不需要拷贝到用户空间,在内核态就能完成发送处理,减少了拷贝的次数。

