概述
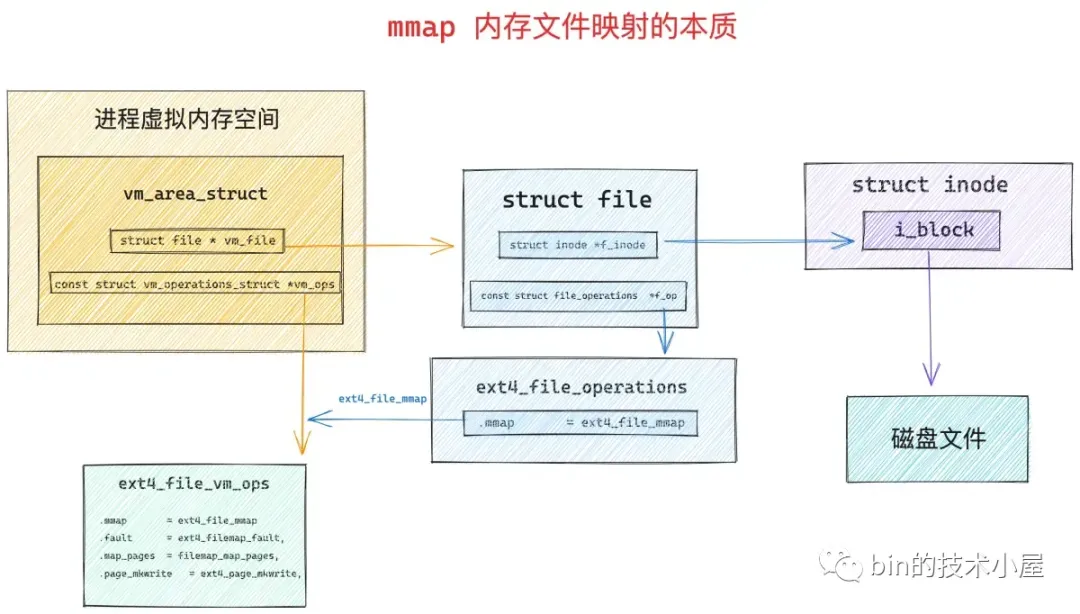
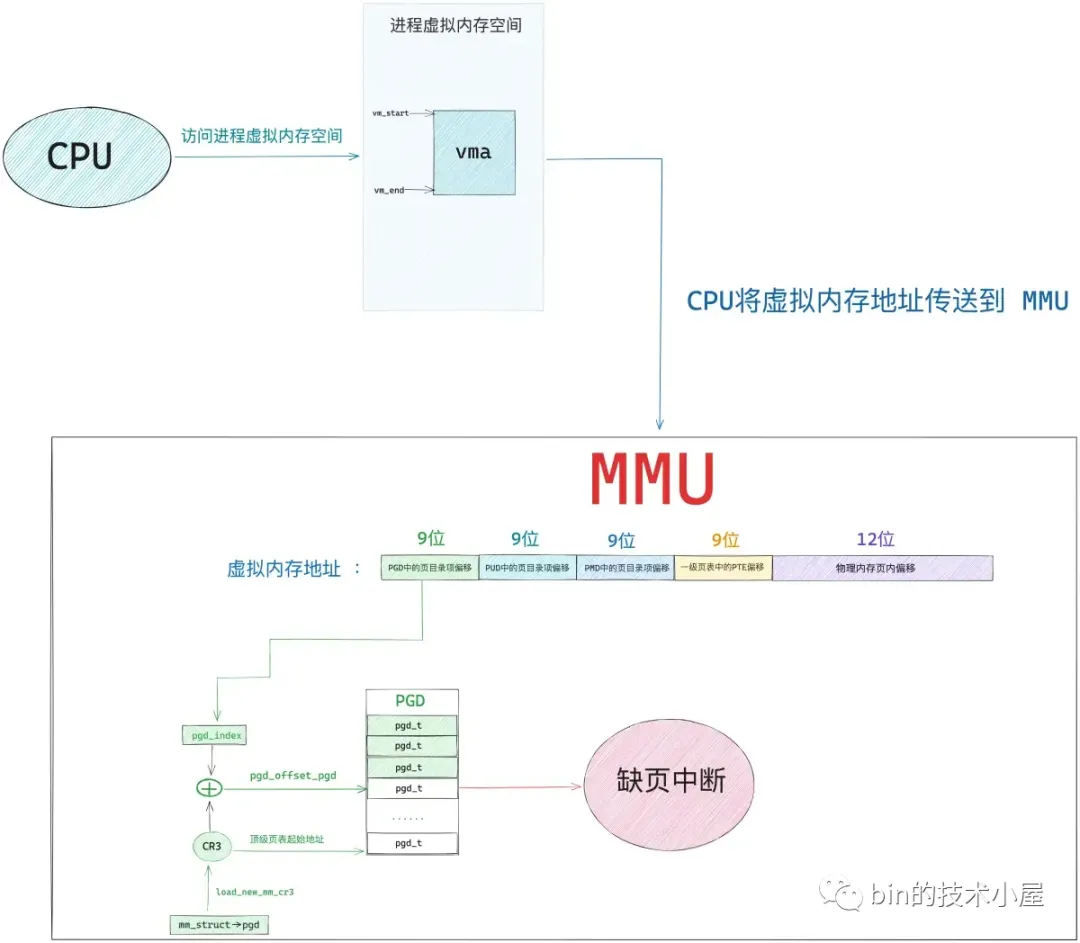
无论是匿名映射还是文件映射,内核在处理 mmap 映射过程中貌似都是在进程的虚拟地址空间中和虚拟内存打交道,仅仅只是为 mmap 映射分配出一段虚拟内存而已,整个映射过程我们并没有看到物理内存的身影。那么大家所关心的物理内存到底是什么时候映射进来的呢 ?
1. 缺页中断产生的原因
如下图所示,当 mmap 系统调用成功返回之后,内核只是为进程分配了一段 [vm_start , vm_end] 范围内的虚拟内存区域 vma ,由于还未与物理内存发生关联,所以此时进程页表中与 mmap 映射的虚拟内存相关的各级页目录和页表项还都是空的。
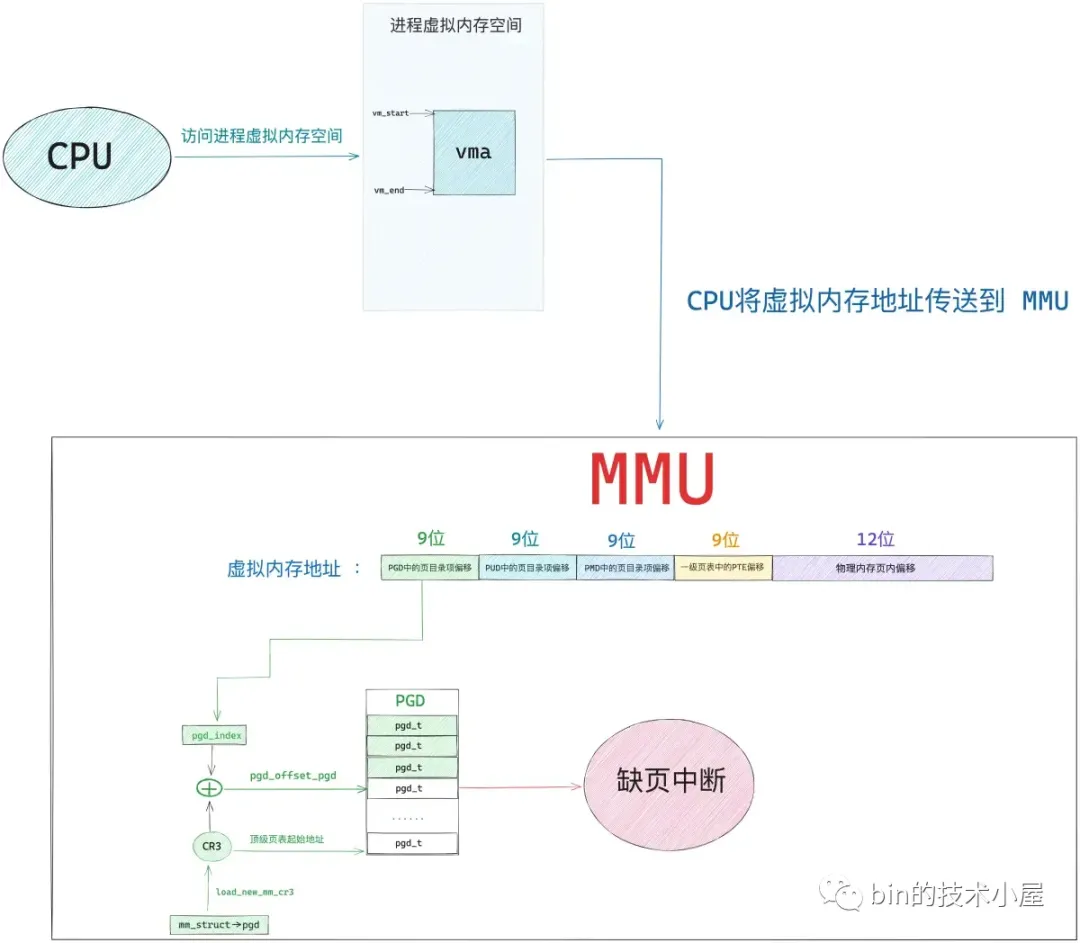
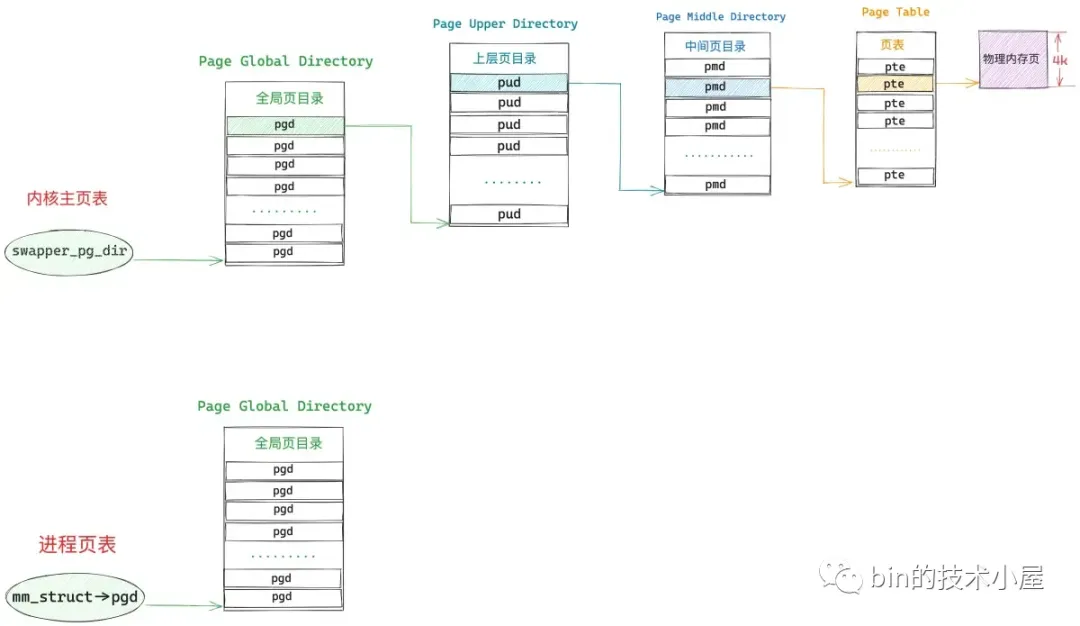
当 CPU 访问这段由 mmap 映射出来的虚拟内存区域 vma 中的任意虚拟地址时,MMU 在遍历进程页表的时候就会发现,该虚拟内存地址在进程顶级页目录 PGD(Page Global Directory)中对应的页目录项 pgd_t 是空的,该 pgd_t 并没有指向其下一级页目录 PUD(Page Upper Directory)。也就是说,此时进程页表中只有一张顶级页目录表 PGD,而上层页目录 PUD(Page Upper Directory),中间页目录 PMD(Page Middle Directory),一级页表(Page Table)内核都还没有创建。
由于现在被访问到的虚拟内存地址对应的 pgd_t 是空的,进程的四级页表体系还未建立,所以 MMU 会产生一个缺页中断,进程从用户态转入内核态来处理这个缺页异常。此时 CPU 会将发生缺页异常时,进程正在使用的相关寄存器中的值压入内核栈中。比如,引起进程缺页异常的虚拟内存地址会被存放在 CR2 寄存器中。同时 CPU 还会将缺页异常的错误码 error_code 压入内核栈中。其中error_code用于对出发的缺页异常的种类的权限进行坚定。
2. 内核处理缺页中断的入口 —— do_page_fault
缺页中断产生的根本原因是由于 CPU 访问的这段虚拟内存背后没有物理内存与之映射,表现的具体形式主要有三种:
- 虚拟内存对应在进程页表体系中的相关各级页目录或者页表是空的,也就是说这段虚拟内存完全没有被映射过。
- 虚拟内存之前被映射过,其在进程页表的各级页目录以及页表中均有对应的页目录项和页表项,但是其对应的物理内存被内核 swap out 到磁盘上了。
- 虚拟内存虽然背后映射着物理内存,但是由于对物理内存的访问权限不够而导致的保护类型的缺页中断。比如,尝试去写一个只读的物理内存页。
一切的起点都是从 CPU 访问虚拟内存开始的,回顾一下进程虚拟内存空间的布局:
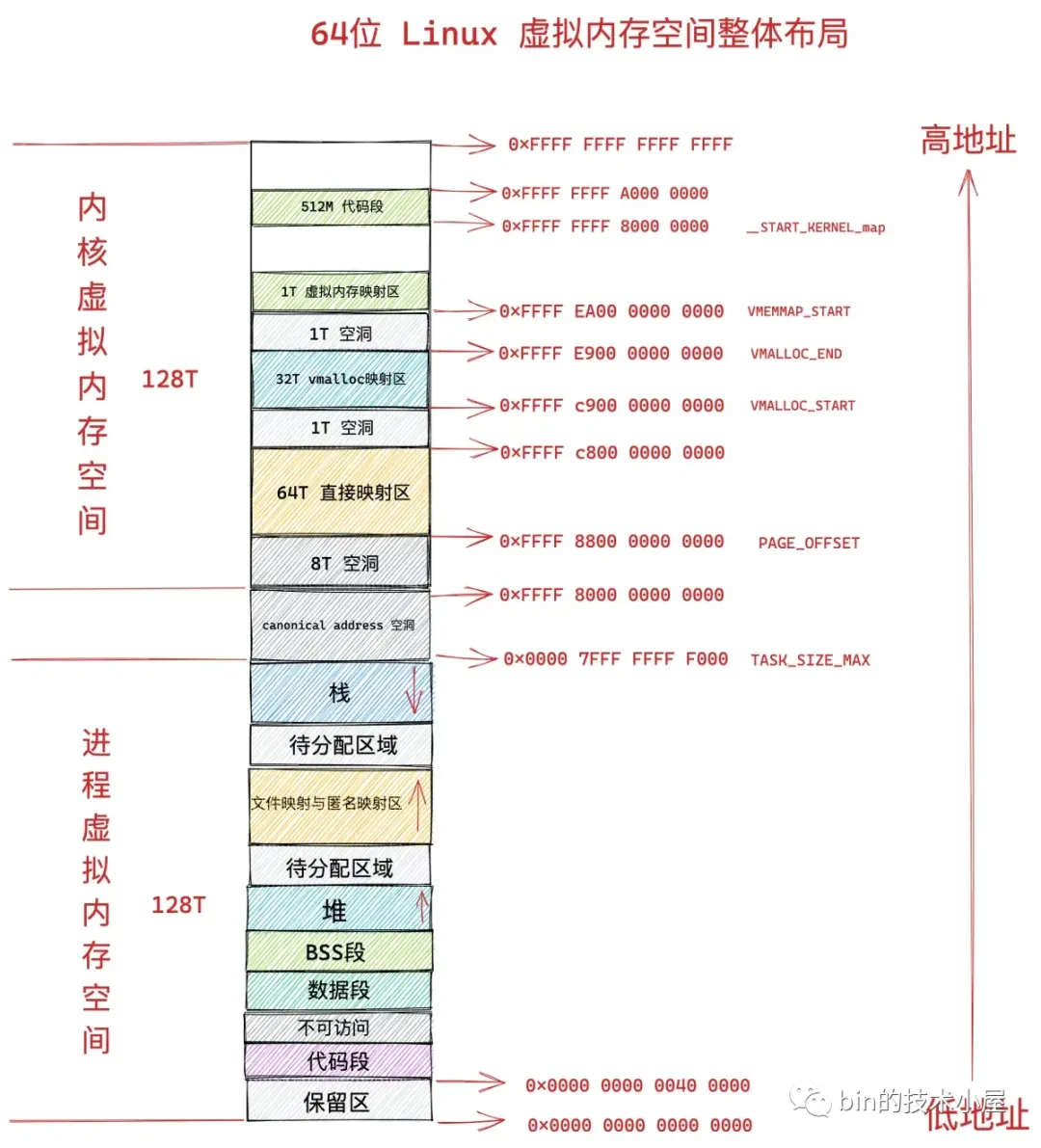
在 64 位体系结构下,进程虚拟内存空间总体上分为两个部分,一部分是 128T 的用户空间,地址范围为:0x0000 0000 0000 0000 - 0x0000 7FFF FFFF FFFF 。但实际上,Linux 内核是用 TASK_SIZE_MAX 来定义用户空间的末尾的,也就是说 Linux 内核是使用 TASK_SIZE_MAX 来分割用户虚拟地址空间与内核虚拟地址空间的。
#define TASK_SIZE_MAX task_size_max()
#define task_size_max() ((_AC(1,UL) << __VIRTUAL_MASK_SHIFT) - PAGE_SIZE)
#define __VIRTUAL_MASK_SHIFT 47
#define PAGE_SHIFT 12
#define PAGE_SIZE (_AC(1,UL) << PAGE_SHIFT)进程用户空间实际可用的虚拟地址范围是:0x0000 0000 0000 0000 - 0x0000 7FFF FFFF F000。以内核空间实际可用的虚拟地址范围是:0xFFFF 8800 0000 0000 - 0xFFFF FFFF FFFF FFFF。
既然进程虚拟内存地址范围有用户空间与内核空间之分,那么当 CPU 访问虚拟内存地址时产生的缺页中断也要区分下是用户空间产生的缺页还是内核空间产生的缺页。
static int fault_in_kernel_space(unsigned long address)
{
/*
* On 64-bit systems, the vsyscall page is at an address above
* TASK_SIZE_MAX, but is not considered part of the kernel
* address space.
*/
if (IS_ENABLED(CONFIG_X86_64) && is_vsyscall_vaddr(address))
return false;
// 在进程虚拟内存空间中,TASK_SIZE_MAX 以上的虚拟地址均属于内核空间
return address >= TASK_SIZE_MAX;
}- 当引起缺页中断的虚拟内存地址 address 是在 TASK_SIZE_MAX 之上时,表示该缺页地址是属于内核空间的,内核的缺页处理程序 __do_page_fault 就要进入 do_kern_addr_fault 分支去处理内核空间的缺页中断。
- 当引起缺页中断的虚拟内存地址 address 是在 TASK_SIZE_MAX 之下时,表示该缺页地址是属于用户空间的,内核则进入 do_user_addr_fault 分支处理用户空间的缺页中断。
static noinline void
__do_page_fault(struct pt_regs *regs, unsigned long hw_error_code,
unsigned long address)
{
// mmap_sem 是进程虚拟内存空间 mm_struct 的读写锁
// 内核这里将 mmap_sem 预取到 cacheline 中,并标记为独占状态( MESI 协议中的 X 状态)
prefetchw(¤t->mm->mmap_sem);
// 这里判断引起缺页异常的虚拟内存地址 address 是属于内核空间的还是用户空间的
if (unlikely(fault_in_kernel_space(address)))
// 如果缺页异常发生在内核空间,则由 vmalloc_fault 进行处理
// 这里使用 unlikely 的原因是,内核对内存的使用通常是高优先级的而且使用比较频繁,所以内核空间一般很少发生缺页异常。
do_kern_addr_fault(regs, hw_error_code, address);
else
// 缺页异常发生在用户态
do_user_addr_fault(regs, hw_error_code, address);
}
NOKPROBE_SYMBOL(__do_page_fault);进程工作在内核空间,由于内核负责的是整个系统最为核心的任务,基本上系统中所有的资源都会向内核倾斜,物理内存资源也是一样。内核对内存的申请优先级是最高的,使用频率也是最频繁的。所以在为内核分配完虚拟内存之后,都会立即分配物理内存,而且是申请多少给多少,最大程度上优先保证内核的工作稳定进行。因此通常在内核中,缺页中断一般很少发生。
而在用户空间,进程在使用 mmap 申请内存的时候,内核仅仅只是为进程在文件映射与匿名映射区分配一段虚拟内存,重要的物理内存资源不会马上分配,而是延迟到进程真正使用的时候,才会通过缺页中断 __do_page_fault 进入到 do_user_addr_fault 分支进行物理内存资源的分配。
3. 内核态缺页异常处理 —— do_kern_addr_fault
内核空间中的缺页异常主要发生在进程内核虚拟地址空间中 32T 的 vmalloc 映射区,这段区域的虚拟内存地址范围为:0xFFFF C900 0000 0000 - 0xFFFF E900 0000 0000。内核中的 vmalloc 内存分配接口就工作在这个区域,它用于将那些不连续的物理内存映射到连续的虚拟内存上。
do_kern_addr_fault 函数的工作主要就是处理内核虚拟内存空间中 vmalloc 映射区里的缺页异常,
static void
do_kern_addr_fault(struct pt_regs *regs, unsigned long hw_error_code,
unsigned long address)
{
// 该缺页的内核地址 address 在内核页表中对应的 pte 不能使用保留位(X86_PF_RSVD = 0)
// 不能是用户态的缺页中断(X86_PF_USER = 0)
// 且不能是保护类型的缺页中断 (X86_PF_PROT = 0)
if (!(hw_error_code & (X86_PF_RSVD | X86_PF_USER | X86_PF_PROT))) {
// 处理 vmalloc 映射区里的缺页异常
if (vmalloc_fault(address) >= 0)
return;
}
} 之前提到在内核空间申请虚拟内存的时候,都会马上分配物理内存资源,而且申请多少给多少。既然物理内存会马上被分配,那为什么内核空间中的 vmalloc 映射区还会发生缺页中断呢 ?
事实上,内核空间里 vmalloc 映射区中发生的缺页中断与用户空间里文件映射与匿名映射区以及堆中发生的缺页中断是不一样的。进程在用户空间中无论是通过 brk 系统调用在堆中申请内存还是通过 mmap 系统调用在文件与匿名映射区中申请内存,内核都只是在相应的虚拟内存空间中划分出一段虚拟内存来给进程使用。
当进程真正访问到这段虚拟内存地址的时候,才会产生缺页中断,近而才会分配物理内存,最后将引起本次缺页的虚拟地址在进程页表中对应的全局页目录项 pgd,上层页目录项 pud,中间页目录 pmd,页表项 pte 都创建好,然后在 pte 中将虚拟内存地址与物理内存地址映射起来。
而内核通过 vmalloc 内存分配接口在 vmalloc 映射区申请内存的时候,首先也会在 32T 大小的 vmalloc 映射区中划分出一段未被使用的虚拟内存区域出来,我们暂且叫这段虚拟内存区域为 vmalloc 区,与mmap其实比较相似,只不过 mmap 工作在用户空间的文件与匿名映射区,vmalloc 工作在内核空间的 vmalloc 映射区。
内核空间中的 vmalloc 映射区就是由这样一段一段的 vmalloc 区组成的,每调用一次 vmalloc 内存分配接口,就会在 vmalloc 映射区中映射出一段 vmalloc 虚拟内存区域,而且每个 vmalloc 区之间隔着一个 4K 大小的 guard page(虚拟内存),用于防止内存越界,将这些非连续的物理内存区域隔离起来。
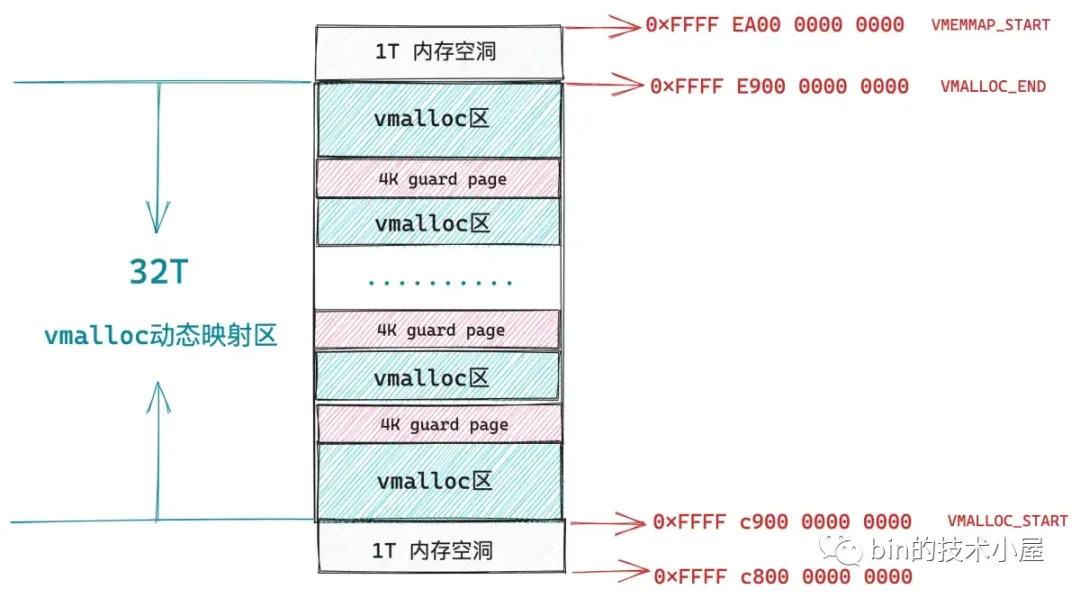
和 mmap 不同的是,vmalloc 在分配完虚拟内存之后,会马上为这段虚拟内存分配物理内存,内核会首先计算出由 vmalloc 内存分配接口映射出的这一段虚拟内存区域 vmalloc 区中包含的虚拟内存页数,然后调用伙伴系统依次为这些虚拟内存页分配物理内存页。
3.1 vmalloc
源码就不看了,直到同 mmap 用 vm_area_struct 结构来描述其在用户空间的文件与匿名映射区分配出来的虚拟内存区域一样,内核空间的 vmalloc 动态映射区也有一种数据结构来专门描述该区域中的虚拟内存区,这个结构就是 vm_struct。由于内核在分配完 vmalloc 虚拟内存区之后,会马上为其分配物理内存,所以在 vm_struct 结构中有一个 struct page 结构的数组指针 pages,用于指向该虚拟内存区域背后映射的物理内存页。nr_pages 则是数组的大小,也表示该虚拟内存区域包含的物理内存页个数。
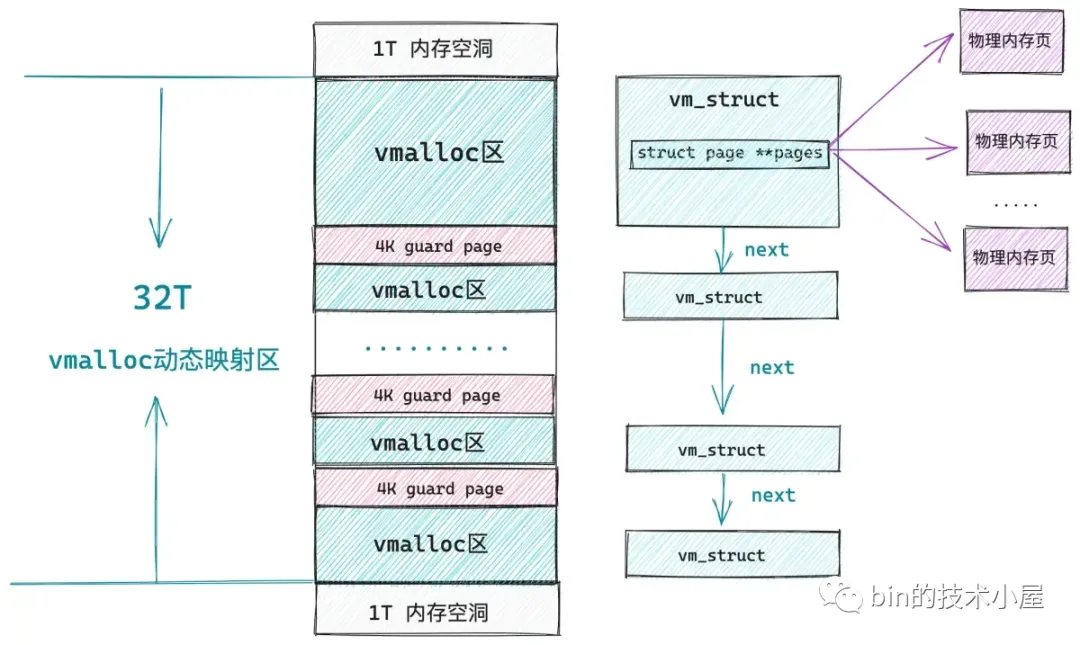
在内核中所有的这些 vm_struct 均是被一个单链表串联组织的,在早期的内核版本中就是通过遍历这个单向链表来在 vmalloc 动态映射区中寻找空闲的虚拟内存区域的,后来为了提高查找效率引入了红黑树以及双向链表来重新组织这些 vmalloc 区域,于是专门引入了一个 vmap_area 结构来描述 vmalloc 区域的组织形式。
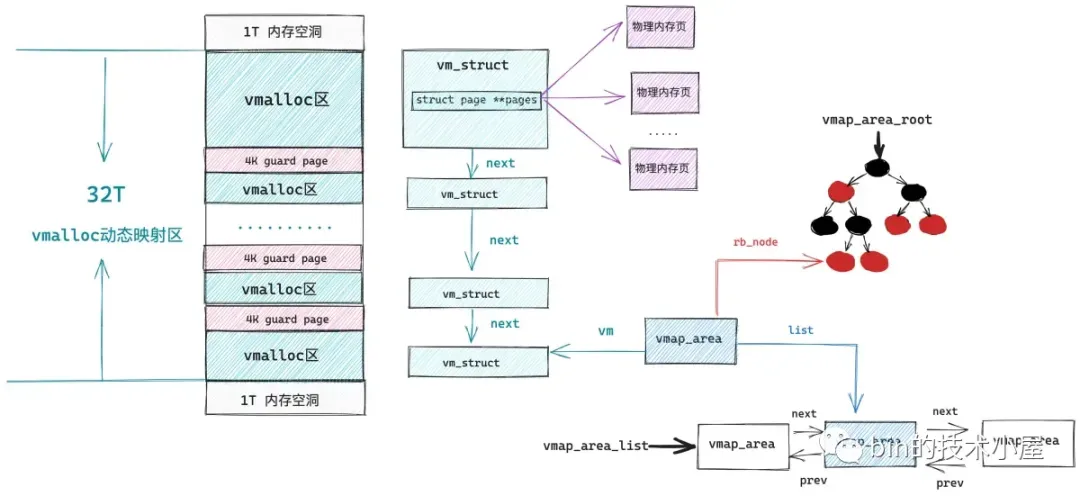
看起来和用户空间中虚拟内存区域的组织形式越来越像了,不同的是由于用户空间是进程间隔离的,所以组织用户空间虚拟内存区域的红黑树以及双向链表是进程独占的。而内核空间是所有进程共享的,所以组织内核空间虚拟内存区域的红黑树以及双向链表是全局的。
在了解了 vmalloc 动态映射区中的相关数据结构与组织形式之后,接下来我们看一看为 vmalloc 区分配物理内存的过程:
static void *__vmalloc_area_node(struct vm_struct *area, gfp_t gfp_mask,
pgprot_t prot, int node)
{
// 指向即将为 vmalloc 区分配的物理内存页
struct page **pages;
unsigned int nr_pages, array_size, i;
// 计算 vmalloc 区所需要的虚拟内存页个数
nr_pages = get_vm_area_size(area) >> PAGE_SHIFT;
// vm_struct 结构中的 pages 数组大小,用于存放指向每个物理内存页的指针
array_size = (nr_pages * sizeof(struct page *));
// 首先要为 pages 数组分配内存
if (array_size > PAGE_SIZE) {
// array_size 超过 PAGE_SIZE 大小则递归调用 vmalloc 分配数组所需内存
pages = __vmalloc_node(array_size, 1, nested_gfp|highmem_mask,
PAGE_KERNEL, node, area->caller);
} else {
// 直接调用 kmalloc 分配数组所需内存
pages = kmalloc_node(array_size, nested_gfp, node);
}
// 初始化 vm_struct
area->pages = pages;
area->nr_pages = nr_pages;
// 依次为 vmalloc 区中包含的所有虚拟内存页分配物理内存
for (i = 0; i < area->nr_pages; i++) {
struct page *page;
if (node == NUMA_NO_NODE)
// 如果没有特殊指定 numa node,则从当前 numa node 中分配物理内存页
page = alloc_page(alloc_mask|highmem_mask);
else
// 否则就从指定的 numa node 中分配物理内存页
page = alloc_pages_node(node, alloc_mask|highmem_mask, 0);
// 将分配的物理内存页依次存放到 vm_struct 结构中的 pages 数组中
area->pages[i] = page;
}
atomic_long_add(area->nr_pages, &nr_vmalloc_pages);
// 修改内核主页表,将刚刚分配出来的所有物理内存页与 vmalloc 虚拟内存区域进行映射
if (map_vm_area(area, prot, pages))
goto fail;
// 返回 vmalloc 虚拟内存区域起始地址
return area->addr;
}在内核中,凡是有物理内存出现的地方,就一定伴随着页表的映射,vmalloc 也不例外,当分配完物理内存之后,就需要修改内核页表,然后将物理内存映射到 vmalloc 虚拟内存区域中,当然了,这个过程也伴随着 vmalloc 区域中的这些虚拟内存地址在内核页表中对应的 pgd,pud,pmd,pte 相关页目录项以及页表项的创建。
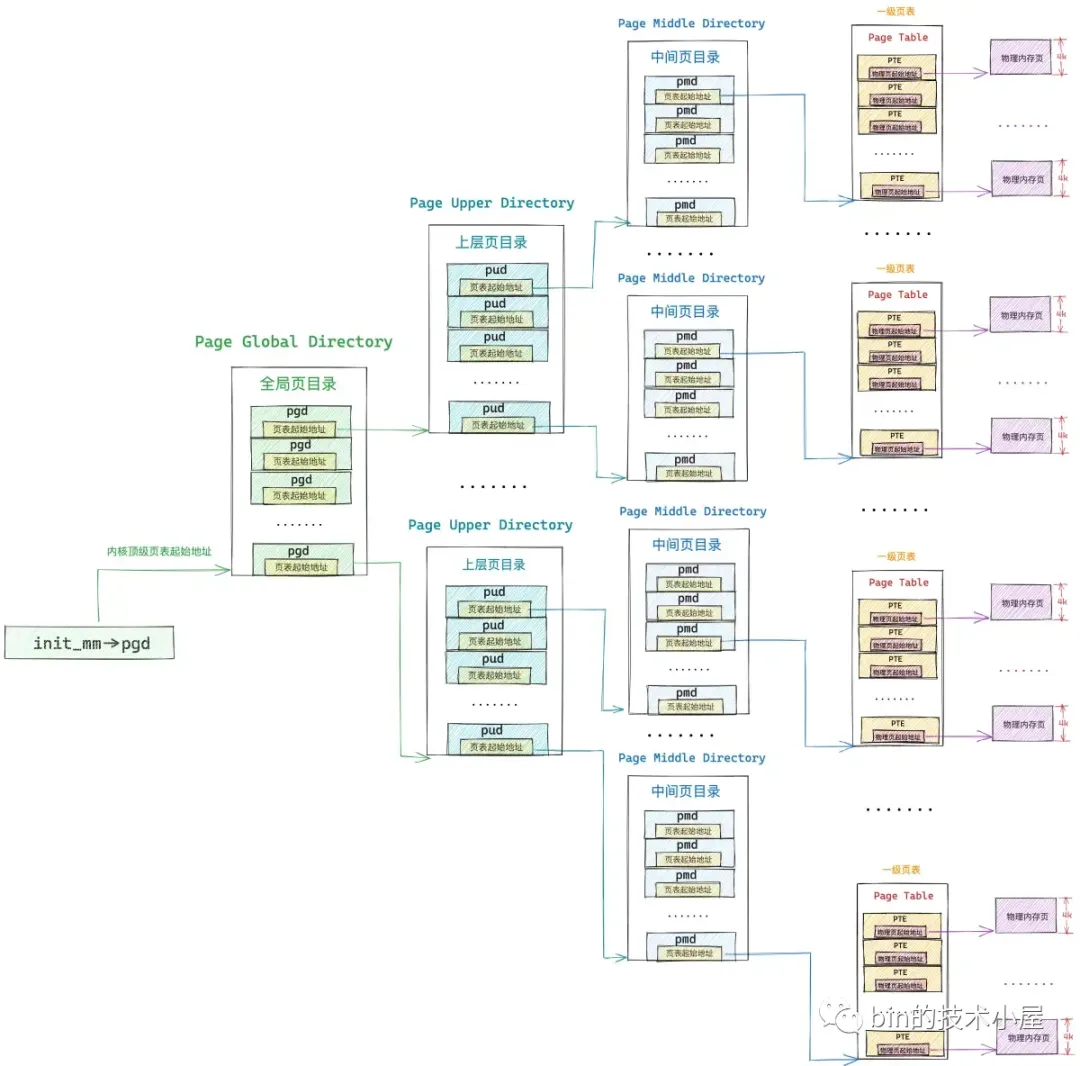
普通进程在内核态亦或是内核线程都是无法直接访问内核主页表的,它们只能访问内核主页表的 copy 副本,于是进程页表体系就分为了两个部分,一个是进程用户态页表(用户态缺页处理的就是这部分),另一个就是内核页表的 copy 部分(内核态缺页处理的是这部分)。
在 fork 系统调用创建进程的时候,进程的用户态页表拷贝自他的父进程,而进程的内核态页表则从内核主页表中拷贝,后续进程陷入内核态之后,访问的就是内核主页表中拷贝的这部分。
这也引出了一个新的问题,就是内核主页表与其在进程中的拷贝副本如何同步呢 ? 这也是内核态缺页异常的处理。
3.2 vmalloc_fault
当内核通过 vmalloc 内存分配接口修改完内核主页表之后,主页表中的相关页目录项以及页表项的内容就发生了改变,而这背后的一切,进程现在还被蒙在鼓里,一无所知,此时,进程页表中的内核部分相关的页目录项以及页表项还都是空的。
当进程陷入内核态访问这部分页表的的时候,会发现相关页目录或者页表项是空的,就会进入缺页中断的内核处理部分,也就是 vmalloc_fault,如果发现缺页的虚拟地址在内核主页表顶级全局页目录表中对应的页目录项 pgd 存在,而缺页地址在进程页表内核部分对应的 pgd 不存在,那么内核就会把内核主页表中 pgd 页目录项里的内容复制给进程页表内核部分中对应的 pgd。
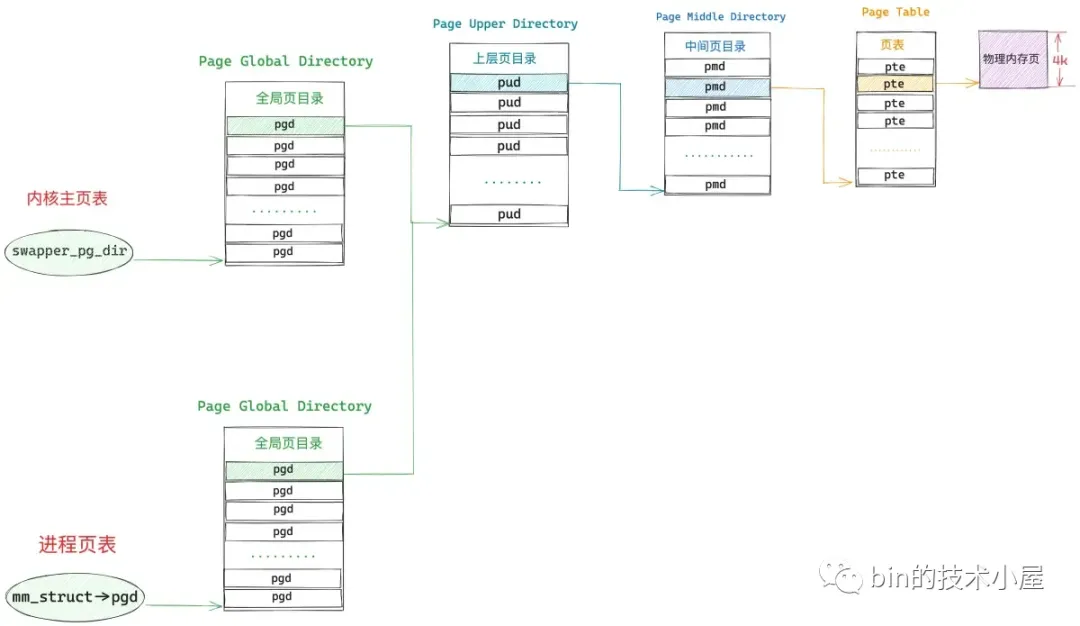
事实上,同步内核主页表的工作只需要将缺页地址对应在内核主页表中的顶级全局页目录项 pgd 同步到进程页表内核部分对应的 pgd 地址处就可以了,后面只要与该 pgd 相关的页目录表以及页表发生任何变化,由于是引用的关系,这些改变都会立刻自动反应到进程页表的内核部分中,后面就不需要同步了。
/*
* 64-bit:
*
* Handle a fault on the vmalloc area
*/
static noinline int vmalloc_fault(unsigned long address)
{
// 分别是缺页虚拟地址 address 对应在内核主页表的全局页目录项 pgd_k ,以及进程页表中对应的全局页目录项 pgd
pgd_t *pgd, *pgd_k;
// p4d_t 用于五级页表体系,当前 cpu 架构体系下一般采用的是四级页表
// 在四级页表下 p4d 是空的,pgd 的值会赋值给 p4d
p4d_t *p4d, *p4d_k;
// 缺页虚拟地址 address 对应在进程页表中的上层目录项 pud
pud_t *pud;
// 缺页虚拟地址 address 对应在进程页表中的中间目录项 pmd
pmd_t *pmd;
// 缺页虚拟地址 address 对应在进程页表中的页表项 pte
pte_t *pte;
// 确保缺页发生在内核 vmalloc 动态映射区
if (!(address >= VMALLOC_START && address < VMALLOC_END))
return -1;
// 获取缺页虚拟地址 address 对应在进程页表的全局页目录项 pgd
pgd = (pgd_t *)__va(read_cr3_pa()) + pgd_index(address);
// 获取缺页虚拟地址 address 对应在内核主页表的全局页目录项 pgd_k
pgd_k = pgd_offset_k(address);
// 如果内核主页表中的 pgd_k 本来就是空的,说明 address 是一个非法访问的地址,返回 -1
if (pgd_none(*pgd_k))
return -1;
// 如果开启了五级页表,那么顶级页表就是 pgd,这里只需要同步顶级页表项就可以了
if (pgtable_l5_enabled()) {
// 内核主页表中的 pgd_k 不为空,进程页表中的 pgd 为空,那么就同步页表
if (pgd_none(* )) {
// 将主内核页表中的 pgd_k 内容复制给进程页表对应的 pgd
set_pgd(pgd, *pgd_k);
// 刷新 mmu
arch_flush_lazy_mmu_mode();
} else {
BUG_ON(pgd_page_vaddr(*pgd) != pgd_page_vaddr(*pgd_k));
}
}
// 四级页表体系下,p4d 是顶级页表项,同样也是只需要同步顶级页表项即可,同步逻辑和五级页表一模一样
// 因为是四级页表,所以这里会将 pgd 赋值给 p4d,p4d_k ,后面就直接把 p4d 看做是顶级页表了。
p4d = p4d_offset(pgd, address);
p4d_k = p4d_offset(pgd_k, address);
// 内核主页表为空,则停止同步,返回 -1 ,表示正在访问一个非法地址
if (p4d_none(*p4d_k))
return -1;
// 内核主页表不为空,进程页表为空,则同步内核顶级页表项 p4d_k 到进程页表对应的 p4d 中,然后刷新 mmu
if (p4d_none(*p4d) && !pgtable_l5_enabled()) {
set_p4d(p4d, *p4d_k);
arch_flush_lazy_mmu_mode();
} else {
BUG_ON(p4d_pfn(*p4d) != p4d_pfn(*p4d_k));
}
// 到这里,页表的同步工作就完成了,下面代码用于检查内核地址 address 在进程页表内核部分中是否有物理内存进行映射
// 如果没有,则返回 -1 ,说明进程在访问一个非法的内核地址,进程随后会被 kill 掉
// 返回 0 表示表示地址 address 背后是有物理内存映射的, vmalloc 动态映射区的缺页处理到此结束。
// 根据顶级页目录项 p4d 获取 address 在进程页表中对应的上层页目录项 pud
pud = pud_offset(p4d, address);
if (pud_none(*pud))
return -1;
// 该 pud 指向的是 1G 大页内存
if (pud_large(*pud))
return 0;
// 根据 pud 获取 address 在进程页表中对应的中间页目录项 pmd
pmd = pmd_offset(pud, address);
if (pmd_none(*pmd))
return -1;
// 该 pmd 指向的是 2M 大页内存
if (pmd_large(*pmd))
return 0;
// 根据 pmd 获取 address 对应的页表项 pte
pte = pte_offset_kernel(pmd, address);
// 页表项 pte 并没有映射物理内存
if (!pte_present(*pte))
return -1;
return 0;
}
NOKPROBE_SYMBOL(vmalloc_fault);既然已经有了内核主页表,而且内核地址空间包括内核页表又是所有进程共享的,那进程为什么不能直接访问内核主页表而是要访问主页表的拷贝部分呢 ? 这样还能省去拷贝内核主页表(fork 时候)以及同步内核主页表(缺页时候)这些个开销。
之所以这样设计一方面有硬件限制的原因,毕竟每个 CPU 核心只会有一个 CR3 寄存器来存放进程页表的顶级页目录起始物理内存地址,没办法同时存放进程页表和内核主页表。另一方面的原因则是操作页表都是需要对其进行加锁的,无论是操作进程页表还是内核主页表。而且在操作页表的过程中可能会涉及到物理内存的分配,这也会引起进程的阻塞。
而进程本身可能处于中断上下文以及竞态区中,不能加锁,也不能被阻塞,如果直接对内核主页表加锁的话,那么系统中的其他进程就只能阻塞等待了。所以只能而且必须是操作主内核页表的拷贝,不能直接操作内核主页表。
4. 用户态缺页异常处理 —— do_user_addr_fault
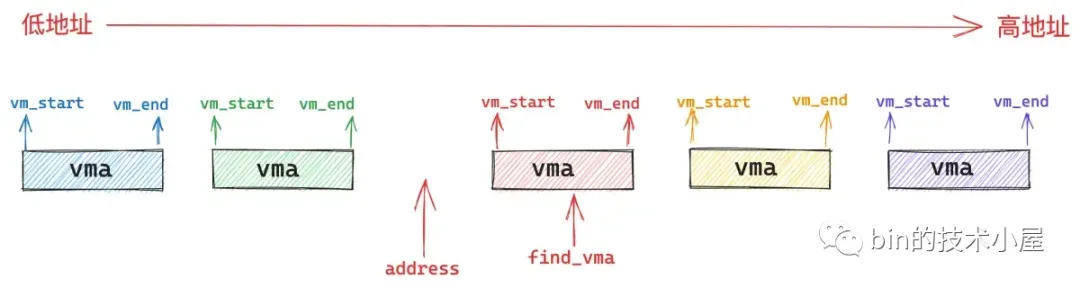
在处理用户态缺页异常之前,内核需要在进程用户空间众多的虚拟内存区域 vma 之中找到引起缺页的内存地址 address 究竟是属于哪一个 vma 。如果没有一个 vma 能够包含 address , 那么就说明该 address 是一个还未被分配的虚拟内存地址,进程对该地址的访问是非法的,自然也就不用处理缺页了。
所以内核就需要根据缺页地址 address 通过 find_vma 函数在进程地址空间中找出符合 address < vma->vm_end 条件的第一个 vma 出来,也就是挨着 address 最近的一个 vma。而缺页地址 address 可以出现在进程地址空间中的任意位置,根据 address 的分布会有下面三种情况:
第一种情况就是 address 的后面没有一个 vma 出现,也就是说进程地址空间中没有一个 vma 符合条件:address < vma->vm_end。进程访问的是一个还未分配的虚拟内存地址,属于非法地址访问,不需要处理缺页。
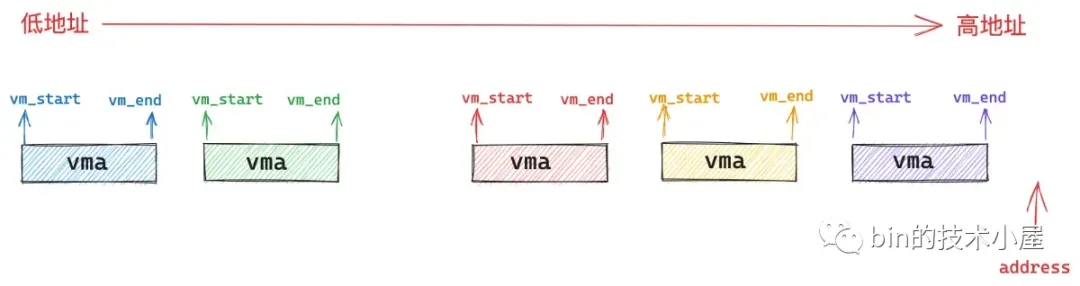
第二种情况就是 address 恰巧包含在一个 vma 中,这个自然是正常情况,内核开始处理该 vma 区域的缺页异常。
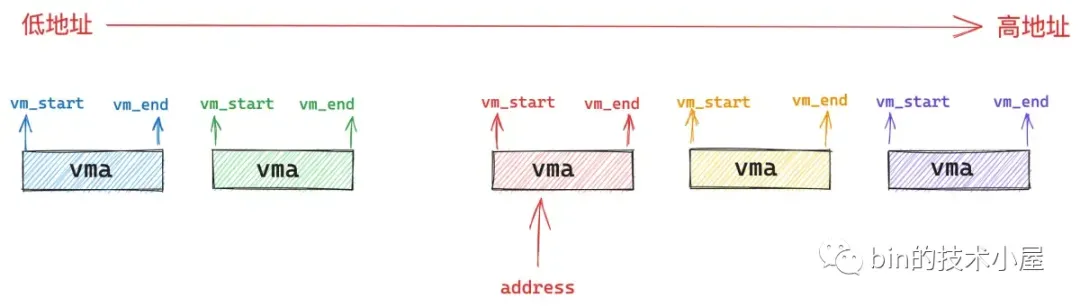
第三种情况是 address 不巧落在了 find_vma 的前面,也就是 address < find_vma->vm_start。这种情况自然也是非法地址访问,不需要处理缺页。
在处理这个缺页的过程中函数会返回一个 unsigned int 类型的位图 vm_fault_t,通过这个位图可以简要描述一下在整个缺页异常处理的过程中究竟发生了哪些状况,方便内核对各种状况进行针对性处理。
/**
* Page fault handlers return a bitmask of %VM_FAULT values.
*/
typedef __bitwise unsigned int vm_fault_t;比如,位图 vm_fault_t 的第三个比特位置为 1 表示 VM_FAULT_MAJOR,置为 0 表示 VM_FAULT_MINOR。
enum vm_fault_reason {
VM_FAULT_MAJOR = (__force vm_fault_t)0x000004,
};- VM_FAULT_MAJOR 的意思是本次缺页所需要的物理内存页还不在内存中,需要重新分配以及需要启动磁盘 IO,从磁盘中 swap in 进来。
- VM_FAULT_MINOR 的意思是本次缺页所需要的物理内存页已经加载进内存中了,缺页处理只需要修改页表重新映射一下就可以了。
来看一个具体的例子,多个进程调用 mmap 对磁盘上的同一个文件进行共享文件映射的时候,此时在各个进程的地址空间中都只是各自分配了一段虚拟内存用于共享文件映射而已,还没有分配物理内存页。
当第一个进程开始访问这段虚拟内存映射区时,由于没有物理内存页,页表还是空的,于是产生缺页中断,内核则会在伙伴系统中分配一个物理内存页,然后将新分配的内存页加入到 page cache 中。然后调用 readpage 激活块设备驱动从磁盘中读取映射的文件内容,用读取到的内容填充新分配的内存页,最后在进程 1 页表中建立共享映射的这段虚拟内存与 page cache 中缓存的文件页之间的关联。
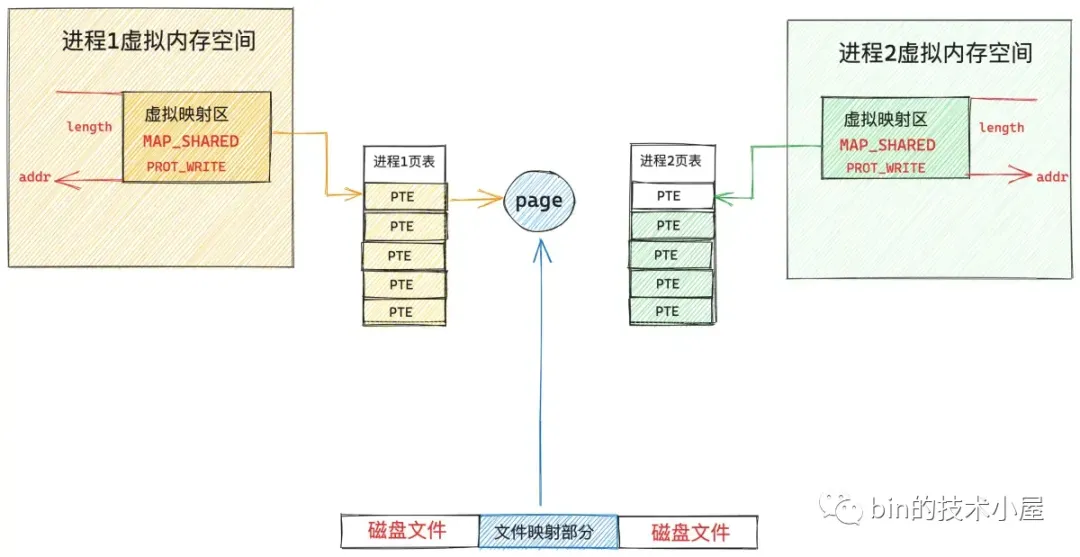
由于进程 1 的缺页处理发生了物理内存的分配以及磁盘 IO ,所以本次缺页处理属于 VM_FAULT_MAJOR。
当进程 2 访问其地址空间中映射的这段虚拟内存时,由于页表是空的,也会发生缺页,但是当进程 2 进入内核中发现所映射的文件页已经被进程 1 加载进 page cache 中了,进程 2 的缺页处理只需要将这个文件页映射进自己的页表就可以了,不需要重新分配内存以及发生磁盘 IO 。这种情况就属于 VM_FAULT_MINOR。
5. handle_mm_fault 完善进程页表体系
起缺页中断的原因大概有三种:
- 第一种是 CPU 访问的虚拟内存地址 address 之前完全没有被映射过,其在页表中对应的各级页目录项以及页表项都还是空的。
- 第二种是 address 之前被映射过,但是映射的这块物理内存被内核 swap out 到磁盘上了。
- 第三种是 address 背后映射的物理内存还在,只是由于访问权限不够引起的缺页中断,比如,后面要为大家介绍的写时复制(COW)机制就属于这一种。
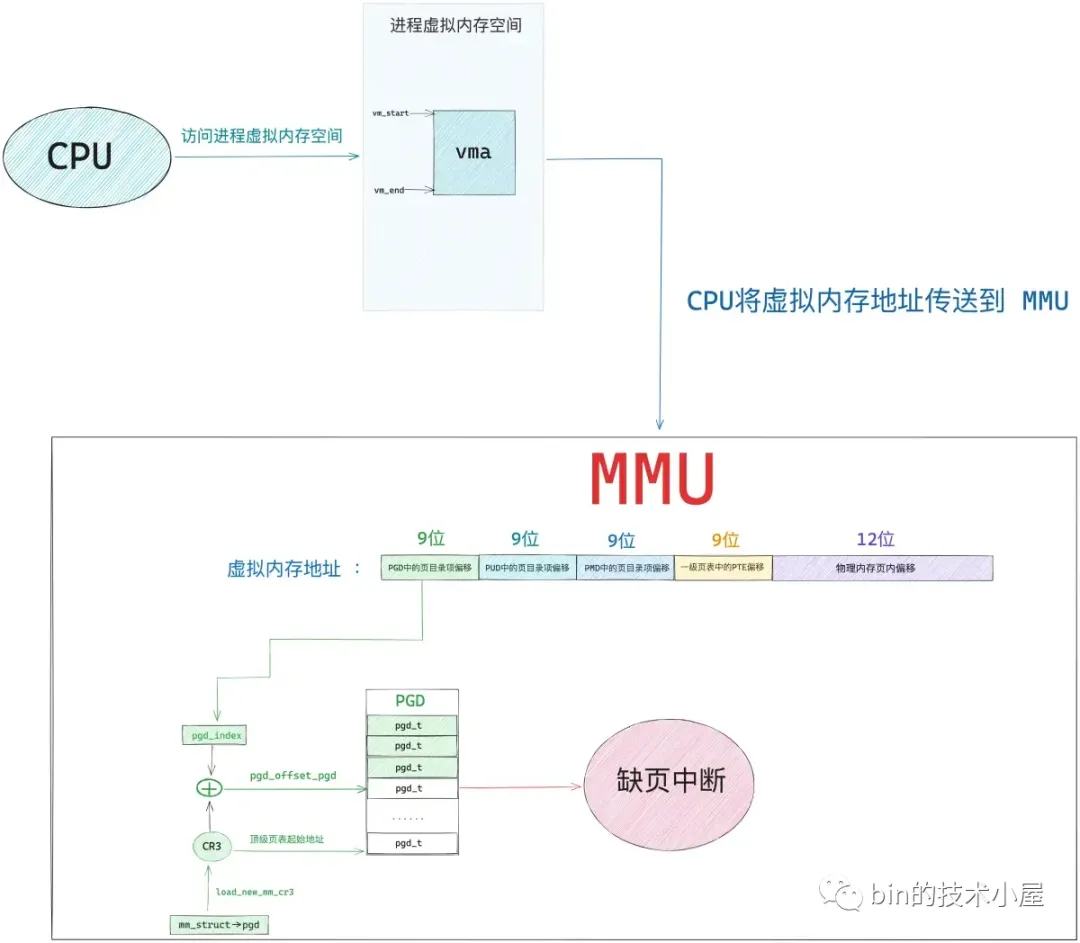
由于现在正在被访问的虚拟内存地址 address 之前从来没有被映射过,所以该虚拟内存地址在进程页表中的各级页目录表中的目录项以及页表中的页表项都是空的。内核的首要任务就是先要将这些缺失的页目录项和页表项一一补齐。
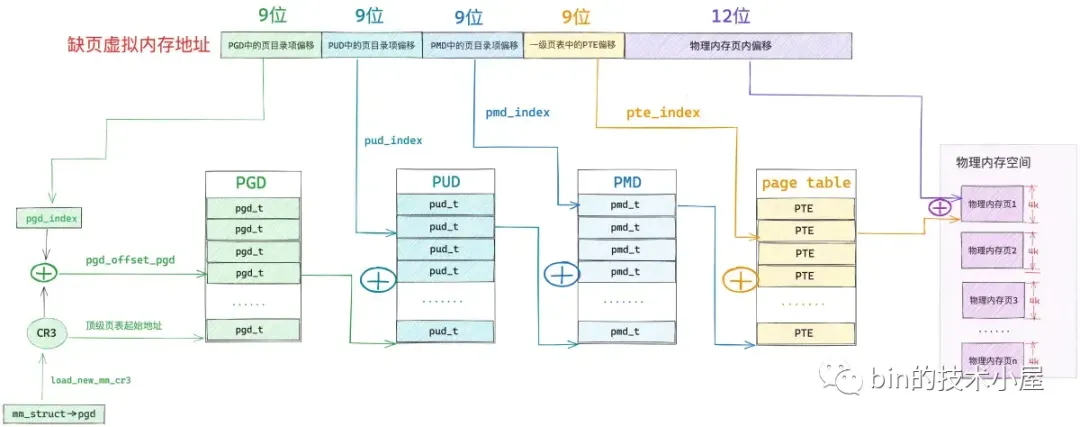
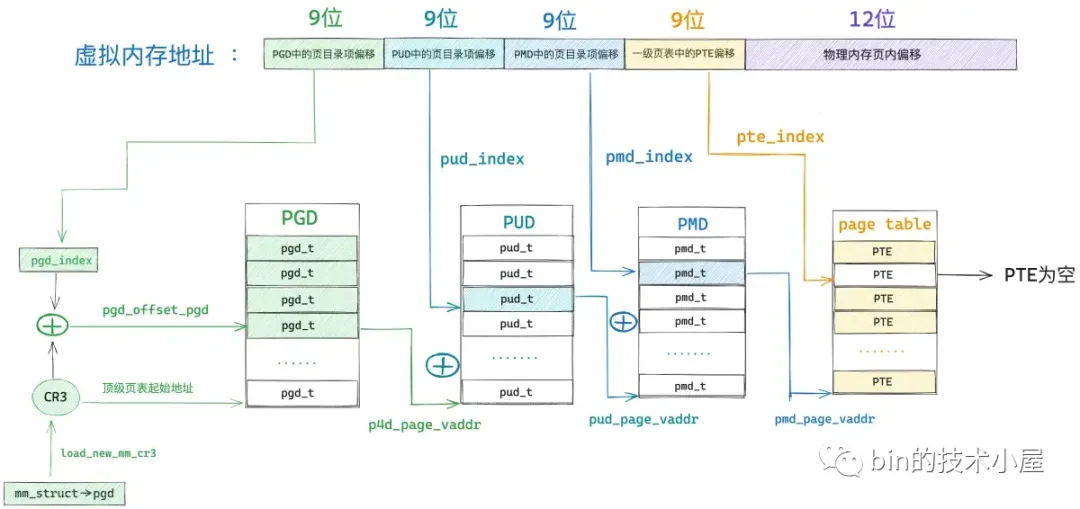
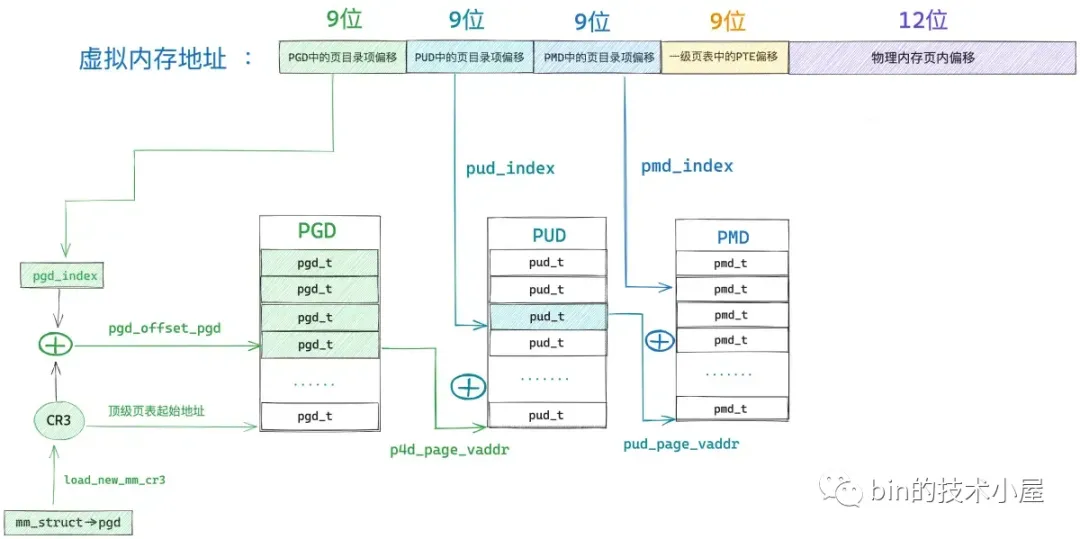
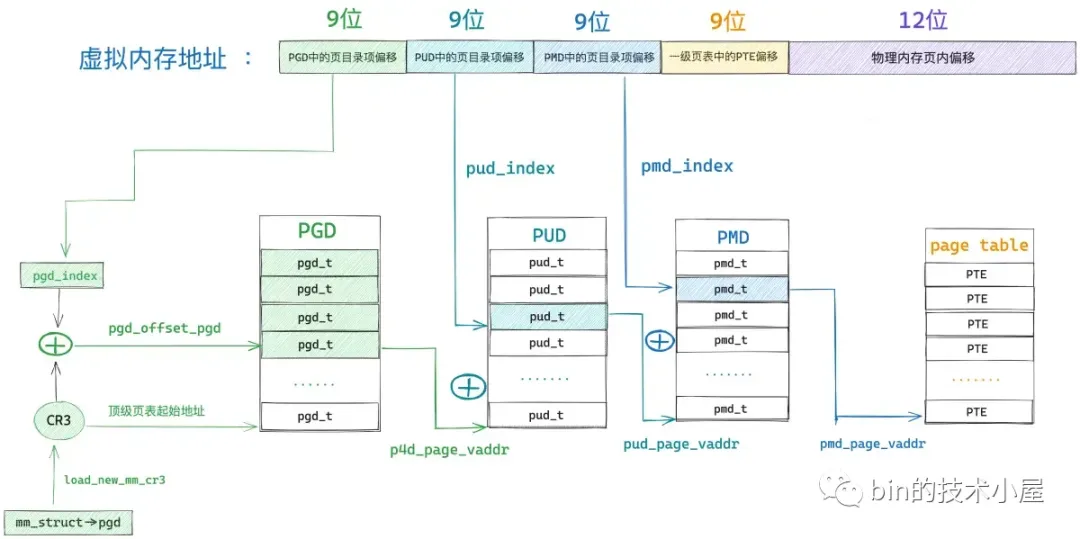
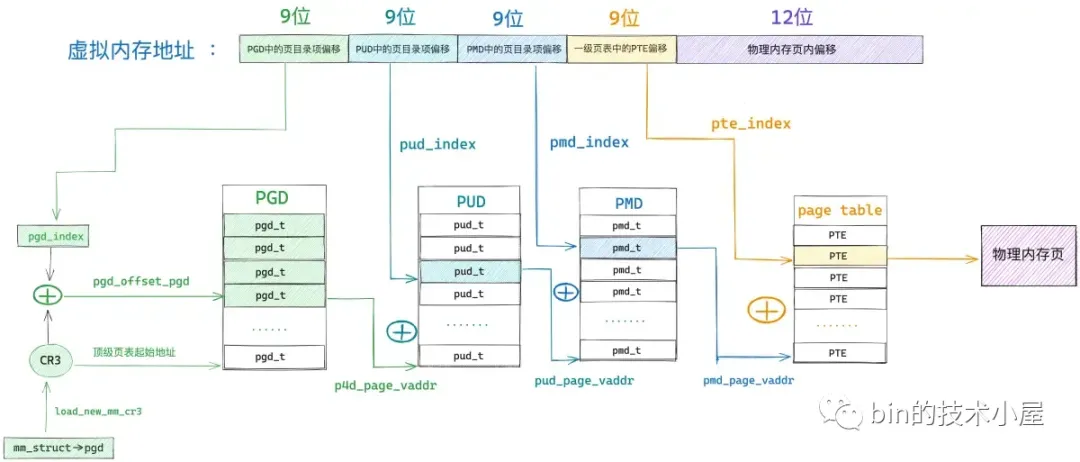
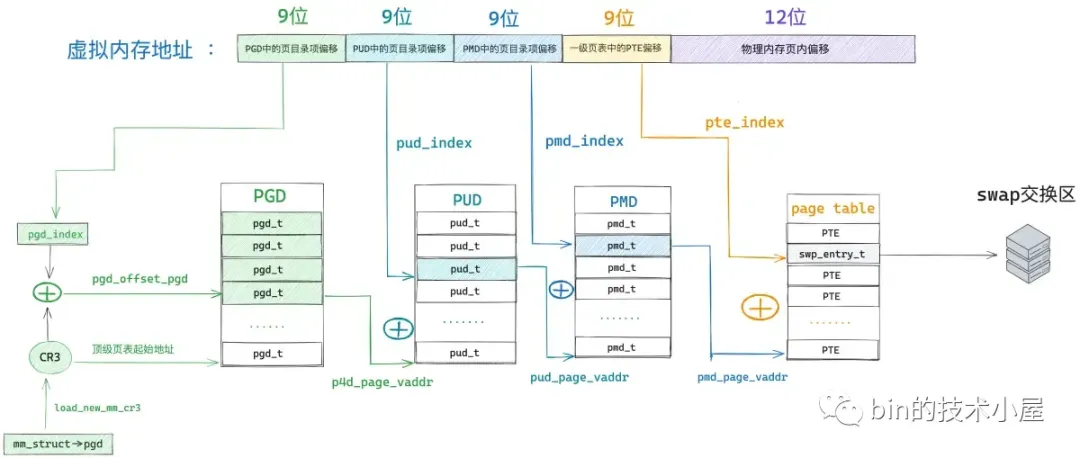
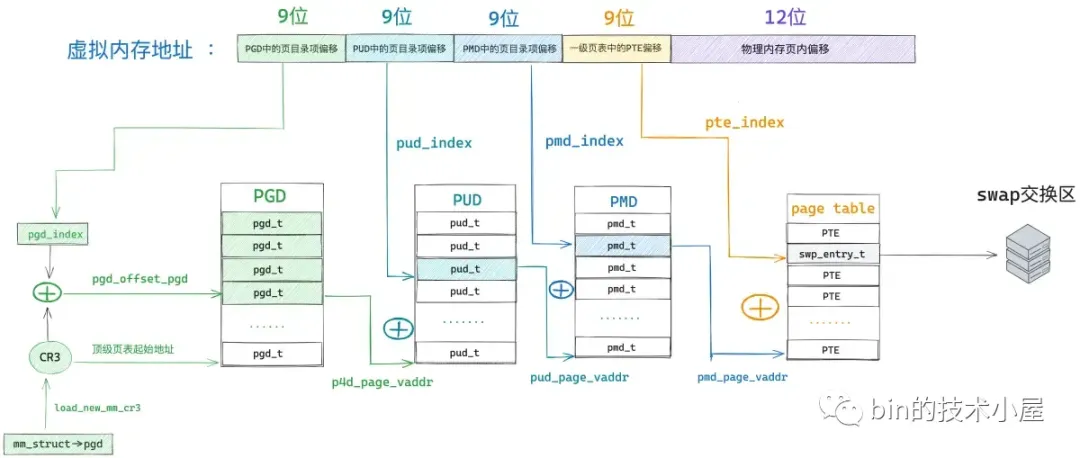
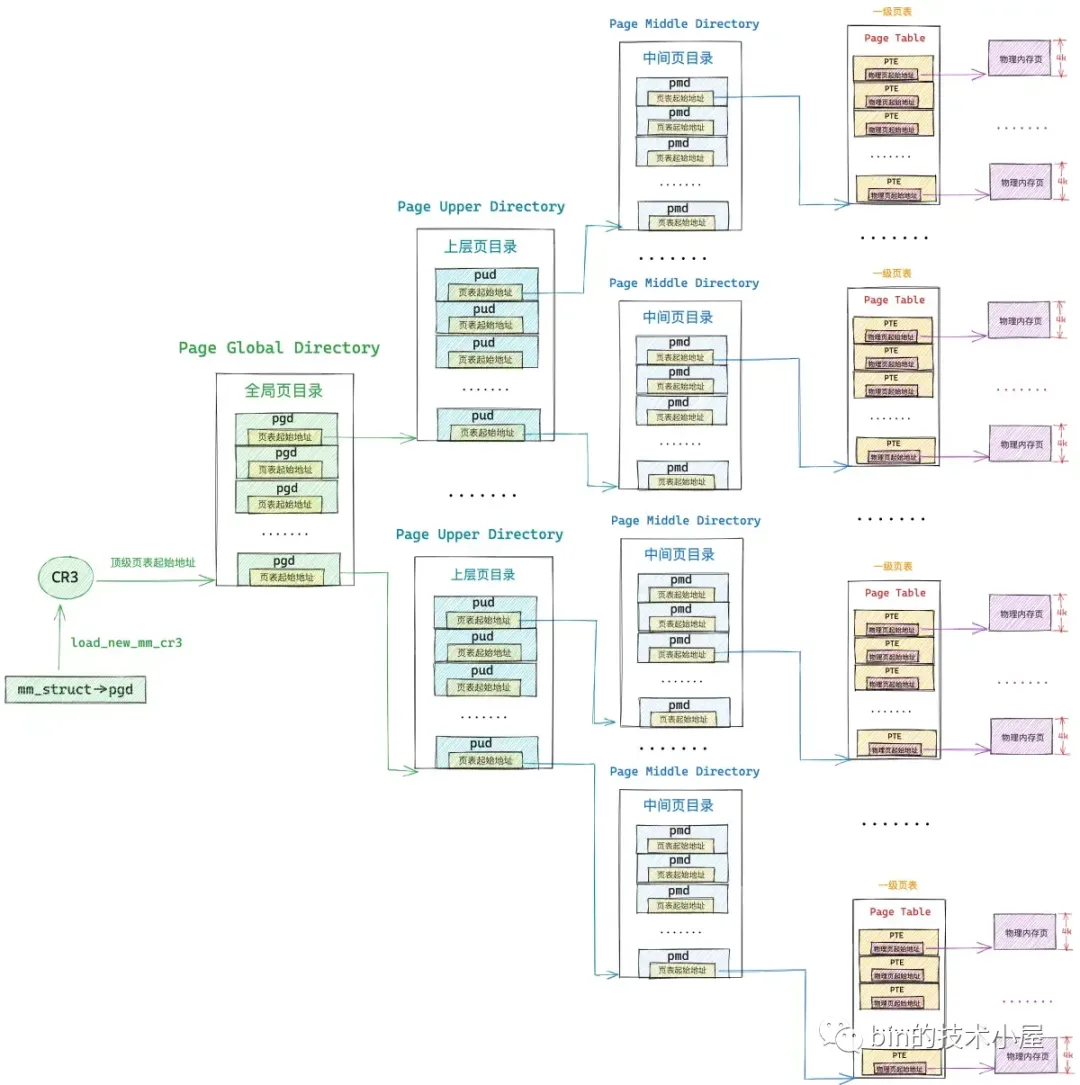
48 位的虚拟内存地址内又分为五个部分,它们分别是虚拟内存地址在全局页目录表 PGD 中对应的页目录项 pgd_t 的偏移,在上层页目录表 PUD 中对应的页目录项 pud_t 的偏移,在中间页目录表 PMD 中对应的页目录项 pmd_t 的偏移,在页表中对应的页表项 pte_t 的偏移,以及在其背后映射的物理内存页中的偏移。
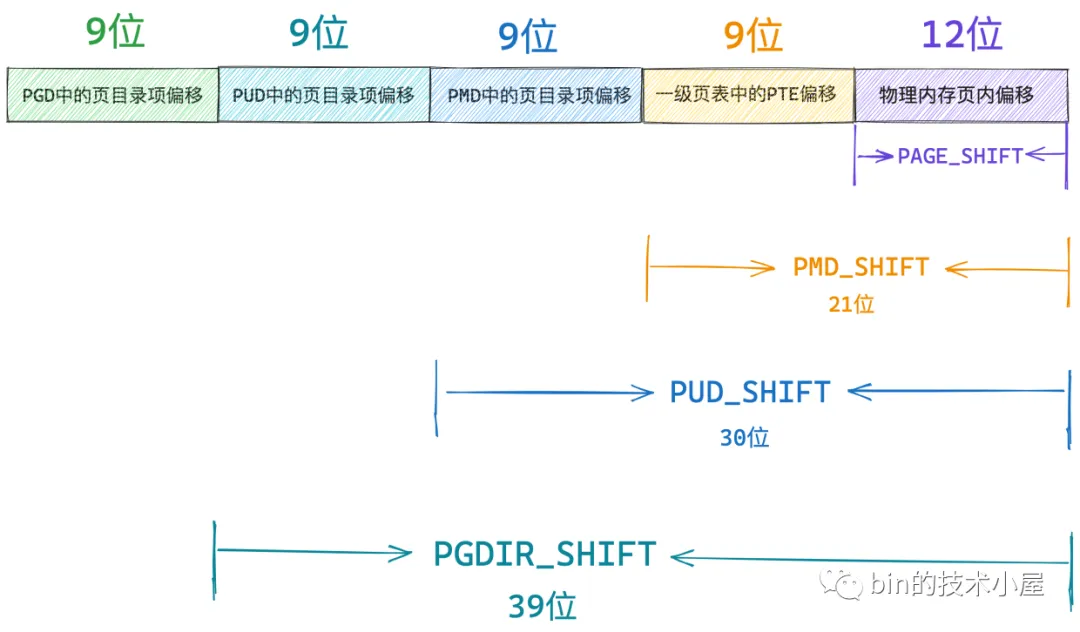
而各级页目录表以及页表在内核中其实本质上都是一个 4K 物理内存页,只不过这些物理内存页存放的内容比较特殊,它们存放的是页目录项和页表项。一张页目录表可以存放 512 个页目录项,一张页表可以存放 512 个页表项。
// 全局页目录表 PGD 可以容纳的页目录项 pgd_t 的个数
#define PTRS_PER_PGD 512
// 上层页目录表 PUD 可以容纳的页目录项 pud_t 的个数
#define PTRS_PER_PUD 512
// 中间页目录表 PMD 可以容纳的页目录项 pmd_t 的个数
#define PTRS_PER_PMD 512
// 页表可以容纳的页表项 pte_t 的个数
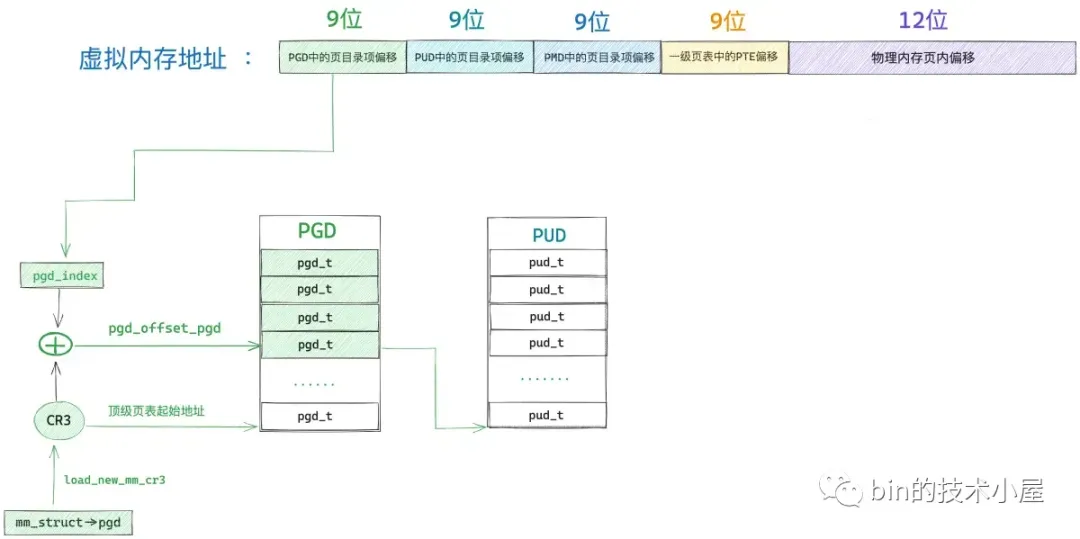
#define PTRS_PER_PTE 512因此我们可以把全局页目录表 PGD 看做是一个能够存放 512 个 pgd_t 的数组 —— pgd_t[PTRS_PER_PGD],虚拟内存地址对应在 pgd_t[PTRS_PER_PGD] 数组中的索引使用 9 个比特位就可以表示了。在内核中使用 pgd_offset 函数来定位虚拟内存地址在全局页目录表 PGD 中对应的页目录项 pgd_t,这个过程和访问数组一模一样,事实上整个 PGD 就是一个 pgd_t[PTRS_PER_PGD] 数组。
首先我们通过 mm_struct-> pgd 获取 pgd_t[PTRS_PER_PGD] 数组的首地址(全局页目录表 PGD 的起始内存地址),然后将虚拟内存地址右移 PGDIR_SHIFT(39)位再用掩码 PTRS_PER_PGD - 1 将高位全部掩去,只保留低 9 位得到虚拟内存地址在 pgd_t[PTRS_PER_PGD] 数组中的索引偏移 pgd_index。然后将 mm_struct-> pgd 与 pgd_index 相加就可以定位到虚拟内存地址在全局页目录表 PGD 中的页目录项 pgd_t 了。现在我们已经通过 pgd_offset 定位到虚拟内存地址 address 对应在全局页目录 PGD 的页目录项 pgd_t(p4d_t)了。
接下来的任务就是根据这个 p4d_t 定位虚拟内存对应在上层页目录 PUD 中的页目录项 pud_t。但在定位之前,我们需要首先判断这个 p4d_t 是否是空的,如果是空的,说明在目前的进程页表中还不存在对应的 PUD,需要马上创建一个新的出来。如果我们通过 p4d_none 函数判断出顶级页目录项 p4d 是空的,那么就需要调用 __pud_alloc 函数分配一个新的上层页目录表 PUD 出来,然后用 PUD 的起始物理内存地址以及页目录项的初始权限位 _PAGE_TABLE 填充 p4d。
由于页目录项所承担的一项最重要的工作就是定位其下一级页目录表的起始物理内存地址,这里的下一级页目录表就是刚刚我们新创建出来的 PUD。所以第一件重要的事情就是通过 __pa(pud) 来获取 PUD 的起始物理内存地址,然后将 PUD 的物理内存地址填充到顶级页目录项 p4d 中的对应比特位上。
由于物理内存地址在内核中都是按照 4K 对齐的,所以 PUD 物理内存地址的低 12 位全部都是 0 ,我们可以利用这 12 个比特位存放一些权限标记位,页目录项在初始化时需要置为 1 的权限标记位定义在 _PAGE_TABLE 中。也就是说 _PAGE_TABLE 定义了页目录项初始权限标记位集合。
我们通过 _PAGE_TABLE 和 __pa(pud) 进行或运算 —— _PAGE_TABLE | __pa(pud),这样就可以按照上图中的比特位布局构造出一个 8 字节的 unsigned long 类型的整数了,这个整数的第 12 到 35 比特位通过 __pa(pud) 填充进来,低 12 位比特通过 _PAGE_TABLE 填充进来。最后我们通过 set_p4d 将我们刚刚构造出来的 p4d_t 赋值给原始的 p4d_t。
这样一来,缺页的虚拟内存地址对应在顶级页目录表中的页目录项 p4d_t 就被填充好了,现在它已经指向了刚刚新创建出来的 PUD,并且拥有了初始的权限位。目前为止,我们只是完善了缺页虚拟内存地址对应在进程页表顶级页目录中的目录项 p4d_t,在四级页表体系下,我们还需要继续向下逐级的去补齐虚拟内存地址对应在其他页目录中的目录项,处理逻辑上都是一模一样的。
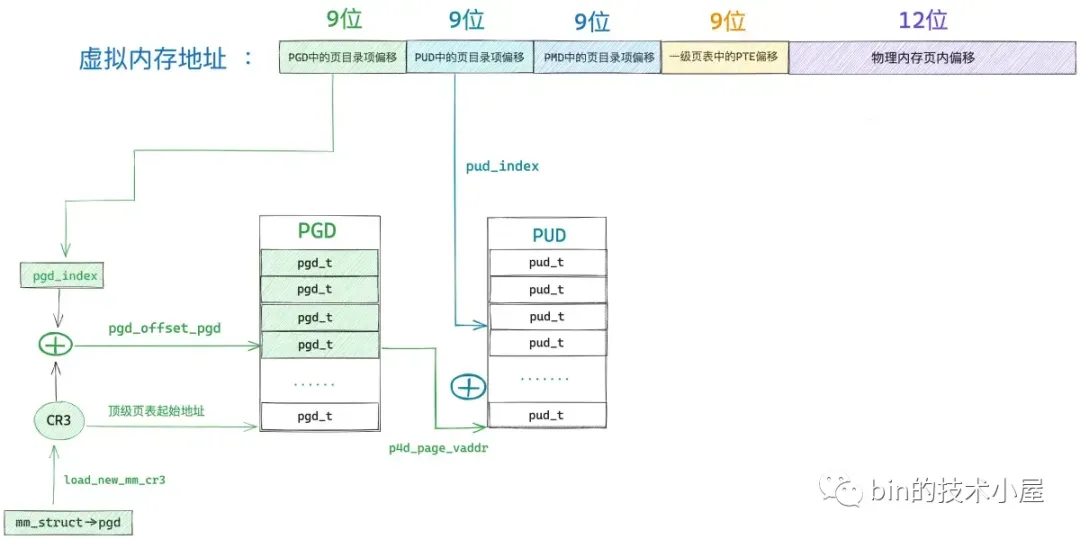
顶级页目录项 p4d 中包含了其下一级页目录 PUD 的相关信息,在内核中使用 pud_offset 函数来定位虚拟内存地址 address 对应在 PUD 中的页目录项 pud_t。和顶级页目录 PGD 一样,上层页目录 PUD 也可以看做是一个能够存放 512 个 pud_t 的数组 —— pud_t[PTRS_PER_PUD] 。
我们有了 pud_index,如果我们还能够知道上层页目录表 PUD 的虚拟内存地址,两者一相加就能得到页目录项 pud_t 了。而 PUD 的物理内存地址恰好保存在刚刚填充好的顶级页目录项 p4d 中,我们可以从 p4d 中将 PUD 的物理内存地址提取出来,然后通过 __va 转换成虚拟内存地址不就行了么。
后面也是类似的,在我们获取到 pmd_t 之后,接下来就该处理页表了,而页表是直接与物理内存页进行映射的,后续我们需要到页表项中,根据权限位的设置来解析出具体的缺页原因,然后进行针对性的缺页处理。
6. handle_pte_fault
物理内存页不在内存
缺页异常主要的三种原因,要么缺页的虚拟内存地址从来还没有被映射过,要么是虽然之前映射过,但是物理内存页被 swap 到磁盘上了,要么是因为访问权限不够的原因引起的缺页。
从总体上来讲引起缺页中断的原因分为两大类,一类是缺页虚拟内存地址背后映射的物理内存页不在内存中,另一类是缺页虚拟内存地址背后映射的物理内存页在内存中,而每一类下边又包含若干种缺页的场景:
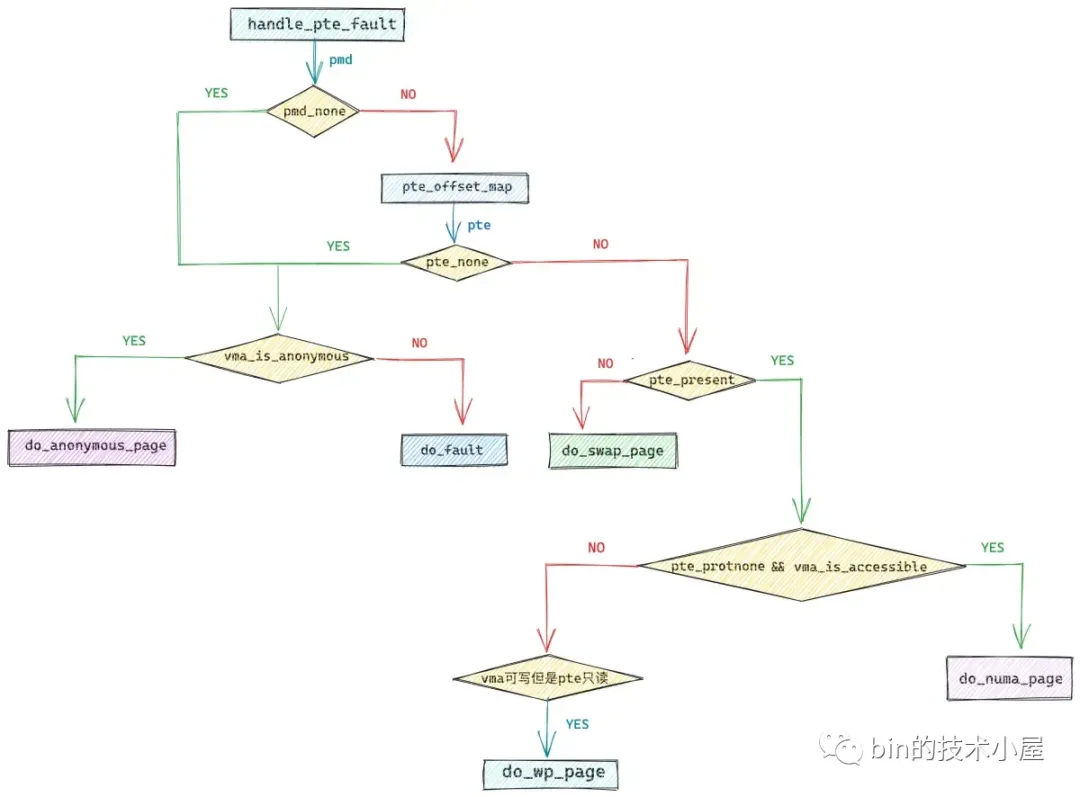
第一种场景是,缺页虚拟内存地址 address 在进程页表中间页目录对应的页目录项 pmd_t 是空的,我们可以通过 pmd_none 方法来判断。
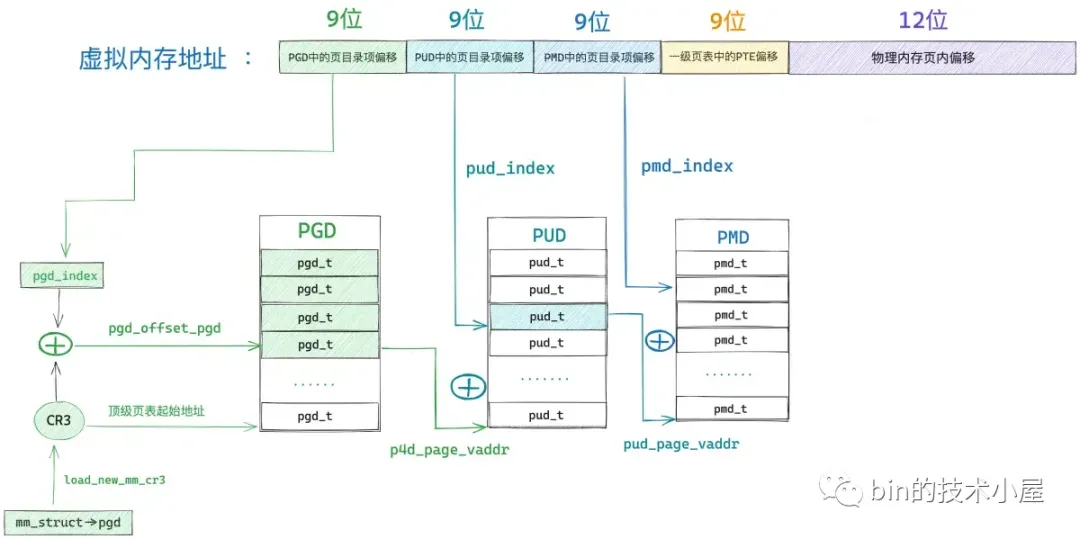
这种情况表示缺页地址 address 对应的 pmd 目前还没有对应的页表,连页表都还没有,那么自然 pte 也是空的,物理内存页就更不用说了,肯定还没有。
第二种场景是,缺页地址 address 对应的 pmd_t 虽然不是空的,页表也存在,但是 address 对应在页表中的 pte 是空的。内核中通过 pte_offset_map 定位 address 在页表中的 pte 。这个过程和前面介绍的定位页目录项的过程一模一样。
这种情况下,虽然页表是存在的,但是奈何 address 在页表中的 pte 是空的,和第一种场景一样,都说明了该 address 之前从来还没有被映射过。既然之前都没有被映射,那么现在就该把这块内容补齐,对于mmap来说分别为:私有匿名映射,私有文件映射,共享文件映射,共享匿名映射。这四种内存映射方式从总体上来说分为两类:一类是匿名映射,另一类是文件映射。
所以在处理虚拟内存映射区 vma 中的缺页时,也需要分为匿名映射区的缺页处理以及文件映射区的缺页处理。那么在这里,我们该如何区分这个缺页的 vma 到底是属于匿名映射区还是文件映射区呢 ?
在mmap内存映射核心函数 mmap_region 中,在处理文件映射的代码中,内核调用了一个叫 call_mmap 的函数,内核在该函数中将虚拟内存的相关操作函数 vma->vm_ops 映射成了文件相关的操作函数 ext4_file_vm_ops。正因为如此,后续进程读写这块虚拟内存就相当于读写文件了。
而在处理匿名映射的代码中,内核调用了一个叫做 vma_set_anonymous 的函数,在这里会将 vma->vm_ops 设置为 null ,因为这里映射的匿名内存页,背后并没有文件来支撑。所以判断一个虚拟内存区域 vma 到底是文件映射区还是匿名映射区就是要看这个 vma 的 vm_ops 是否为 null。
- 如果 vma_is_anonymous 返回 true,那么内核就会在 handle_pte_fault 函数中调用 do_anonymous_page 进行匿名映射区的缺页处理。
- 如果 vma_is_anonymous 返回 false,那么内核就调用 do_fault 进行文件映射区的缺页处理。
第三种缺页场景是,虚拟内存地址 address 在进程页表中的页表项 pte 不是空的,但是其背后映射的物理内存页被内核 swap out 到磁盘上了,CPU 访问的时候依然会产生缺页。
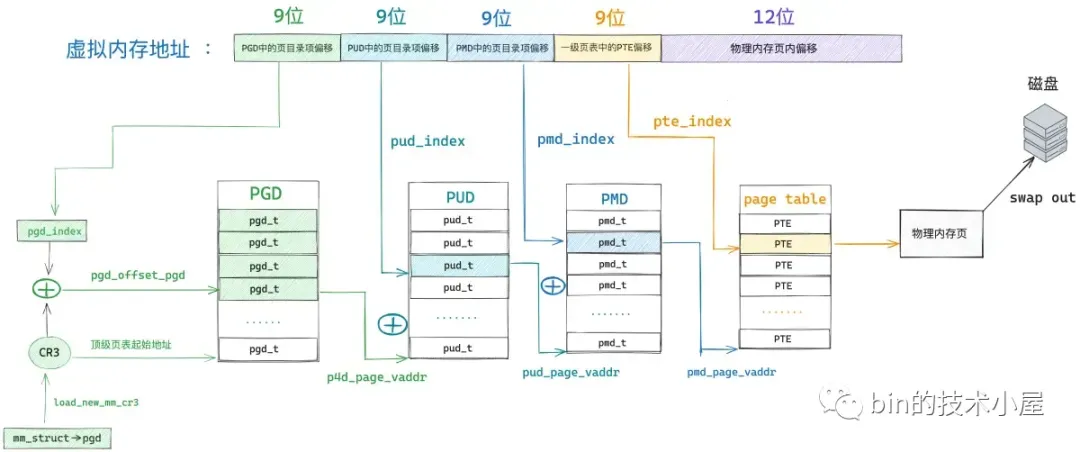
那么我们如何知道 pte 背后映射的物理内存页在不在内存中呢 ?查看表头的比特位布局,其中 pte 的第 0 个比特位表示该 pte 映射的物理内存页是否在内存中,值为 1 表示物理内存页在内存中驻留,值为 0 表示物理内存页不在内存中,可能被 swap 到磁盘上了。如果我们通过 pte_present 判断映射的物理内存页不在内存中了,说明它已经被内核 swap out 到磁盘上了,这种情况下的缺页处理就需要调用 do_swap_page 函数,将磁盘上的物理内存页重新 swap in 到内存中来。
if (!pte_present(vmf->orig_pte))
// 将之前映射的物理内存页从磁盘中重新 swap in 到内存中
return do_swap_page(vmf);以上介绍的这三种缺页场景都是属于缺页内存地址 address 背后映射的物理内存页不在内存中的类别。
物理内存页在内存中
下面我们来看下另一类别,也就是缺页虚拟内存地址背后映射的物理内存页在内存中的情况 ,这里又会近一步分为两种缺页场景。
在 NUMA 架构下,我们缺页处理的场景中就是缺页虚拟内存地址背后映射的物理内存页虽然在内存中,但是它可能是进程所在 CPU 中的本地 NUMA 节点上的内存,也可能是其他 NUMA 节点上的内存。因为 CPU 对不同 NUMA 节点上的内存有访问速度上的差异,所以内核通常倾向于让 CPU 尽量访问本地 NUMA 节点上的内存。NUMA Balancing 机制就是用来解决这个问题的。
通俗来讲,NUMA Balancing 主要干两件事情,一件事是让内存跟着 CPU 走,另一件事是让 CPU 跟着内存走。进程申请到的物理内存页可能在当前 CPU 的本地 NUMA 节点上,也可能在其他 NUMA 节点上。
- 所谓让内存跟着 CPU 走的意思就是,当进程访问的物理内存页不在当前 CPU 的本地 NUMA 节点上时,NUMA Balancing 就会尝试将远程 NUMA 节点上的物理内存页迁移到本地 NUMA 节点上,加快进程访问内存的速度。
- 所谓让 CPU 跟着内存走的意思就是,当进程经常访问的大部分物理内存页均不在当前 CPU 的本地 NUMA 节点上时,NUMA Balancing 干脆就把进程重新调度到这些物理内存页所在的 NUMA 节点上。当然整个 NUMA Balancing 的过程会根据我们设置的 NUMA policy 以及各个 NUMA 节点上缺页的次数来综合考虑是否迁移内存页。
说回来,这种情况下调用 pte_present 依然很返回 true ,因为当前的物理内存页毕竟是在内存中的,只不过不在当前 CPU 的本地 NUMA 节点上而已。当 pte 被标记为 _PAGE_PROTNONE 之后,这意味着该 pte 背后映射的物理内存页进程对其没有读写权限,也没有可执行的权限。进程在访问这段虚拟内存地址的时候就会发生缺页。
当进入缺页异常的处理程序之后,内核会在 handle_pte_fault 函数中通过 pte_protnone 函数判断,缺页的 pte 是否被标记了 _PAGE_PROTNONE 标识。
static inline int pte_protnone(pte_t pte)
{
return (pte_flags(pte) & (_PAGE_PROTNONE | _PAGE_PRESENT))
== _PAGE_PROTNONE;
}当 pte 被标记为 _PAGE_PROTNONE 之后,这意味着该 pte 背后映射的物理内存页进程对其没有读写权限,也没有可执行的权限。进程在访问这段虚拟内存地址的时候就会发生缺页。如果 pte 被标记了 _PAGE_PROTNONE,并且对应的虚拟内存区域是一个具有读写,可执行权限的 vma。这就说明该 vma 背后映射的物理内存页不在当前 CPU 的本地 NUMA 节点上。这里需要调用 do_numa_page,将这个远程 NUMA 节点上的物理内存页迁移到当前 CPU 的本地 NUMA 节点上,从而加快进程访问内存的速度。
第二种场景就是写时复制了(Copy On Write, COW),这种场景和 NUMA Balancing 一样,都属于缺页虚拟内存地址背后映射的物理内存页在内存中而引起的缺页中断。
COW 在内核的内存管理子系统中很常见了,比如,父进程通过 fork 系统调用创建子进程之后,父子进程的虚拟内存空间完全是一模一样的,包括父子进程的页表内容都是一样的,父子进程页表中的 PTE 均指向同一物理内存页面,此时内核会将父子进程页表中的 PTE 均改为只读的,并将父子进程共同映射的这个物理页面引用计数 + 1。
static inline unsigned long
copy_one_pte(struct mm_struct *dst_mm, struct mm_struct *src_mm,
pte_t *dst_pte, pte_t *src_pte, struct vm_area_struct *vma,
unsigned long addr, int *rss)
{
/*
* If it's a COW mapping, write protect it both
* in the parent and the child
*/
if (is_cow_mapping(vm_flags) && pte_write(pte)) {
// 设置父进程的 pte 为只读
ptep_set_wrprotect(src_mm, addr, src_pte);
// 设置子进程的 pte 为只读
pte = pte_wrprotect(pte);
}
// 获取 pte 中映射的物理内存页(此时父子进程共享该页)
page = vm_normal_page(vma, addr, pte);
// 物理内存页的引用计数 + 1
get_page(page);
}当父进程或者子进程对该页面发生写操作的时候,我们现在假设子进程先对页面发生写操作,随后子进程发现自己页表中的 PTE 是只读的,于是产生缺页中断,子进程进入内核态,内核会在本小节介绍的缺页中断处理程序中发现,访问的这个物理页面引用计数大于 1,说明此时该物理内存页面存在多进程共享的情况,于是发生写时复制(Copy On Write, COW),内核为子进程重新分配一个新的物理页面,然后将原来物理页中的内容拷贝到新的页面中,最后子进程页表中的 PTE 指向新的物理页面并将 PTE 的 R/W 位设置为 1,原来物理页面的引用计数 - 1。
后面父进程在对页面进行写操作的时候,同样也会发现父进程的页表中 PTE 是只读的,也会产生缺页中断,但是在内核的缺页中断处理程序中,发现访问的这个物理页面引用计数为 1 了,那么就只需要将父进程页表中的 PTE 的 R/W 位设置为 1 就可以了。
在以上介绍的两种写时复制应用场景中,他们都有一个共同的特点,就是进程的虚拟内存区域 vma 的权限是可写的,但是其对应在页表中的 pte 却是只读的,而 pte 映射的物理内存页也在内存中。内核正是利用这个特点来判断本次缺页中断是否是由写时复制引起的。如果是,则调用 do_wp_page 进行写时复制的缺页处理。
在我们清楚了以上背景知识之后,再来看 handle_pte_fault 的缺页处理逻辑就很清晰了:
static vm_fault_t handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
if (unlikely(pmd_none(*vmf->pmd))) {
// 如果 pmd 是空的,说明现在连页表都没有,页表项 pte 自然是空的
vmf->pte = NULL;
} else {
// vmf->pte 表示缺页虚拟内存地址在页表中对应的页表项 pte
// 通过 pte_offset_map 定位到虚拟内存地址 address 对应在页表中的 pte
// 这里根据 address 获取 pte_index,然后从 pmd 中提取页表起始虚拟内存地址相加获取 pte
vmf->pte = pte_offset_map(vmf->pmd, vmf->address);
// vmf->orig_pte 表示发生缺页时,address 对应的 pte 值
vmf->orig_pte = *vmf->pte;
// 这里 pmd 不是空的,表示现在是有页表存在的,但缺页虚拟内存地址在页表中的 pte 是空值
if (pte_none(vmf->orig_pte)) {
pte_unmap(vmf->pte);
vmf->pte = NULL;
}
}
// pte 是空的,表示缺页地址 address 还从来没有被映射过,接下来就要处理物理内存的映射
if (!vmf->pte) {
// 判断缺页的虚拟内存地址 address 所在的虚拟内存区域 vma 是否是匿名映射区
if (vma_is_anonymous(vmf->vma))
// 处理匿名映射区发生的缺页
return do_anonymous_page(vmf);
else
// 处理文件映射区发生的缺页
return do_fault(vmf);
}
// 走到这里表示 pte 不是空的,但是 pte 中的 p 比特位是 0 值,表示之前映射的物理内存页已不在内存中(swap out)
if (!pte_present(vmf->orig_pte))
// 将之前映射的物理内存页从磁盘中重新 swap in 到内存中
return do_swap_page(vmf);
// 这里表示 pte 背后映射的物理内存页在内存中,但是 NUMA Balancing 发现该内存页不在当前进程运行的 numa 节点上
// 所以将该 pte 标记为 _PAGE_PROTNONE(无读写,可执行权限)
// 进程访问该内存页时发生缺页中断,在这里的 do_numa_page 中,内核将该 page 迁移到进程运行的 numa 节点上。
if (pte_protnone(vmf->orig_pte) && vma_is_accessible(vmf->vma))
return do_numa_page(vmf);
entry = vmf->orig_pte;
// 如果本次缺页中断是由写操作引起的
if (vmf->flags & FAULT_FLAG_WRITE) {
// 这里说明 vma 是可写的,但是 pte 被标记为不可写,说明是写保护类型的中断
if (!pte_write(entry))
// 进行写时复制处理,cow 就发生在这里
return do_wp_page(vmf);
// 如果 pte 是可写的,就将 pte 标记为脏页
entry = pte_mkdirty(entry);
}
// 将 pte 的 access 比特位置 1 ,表示该 page 是活跃的。避免被 swap 出去
entry = pte_mkyoung(entry);
// 经过上面的缺页处理,这里会判断原来的页表项 entry(orig_pte) 值是否发生了变化
// 如果发生了变化,就把 entry 更新到 vmf->pte 中。
if (ptep_set_access_flags(vmf->vma, vmf->address, vmf->pte, entry,
vmf->flags & FAULT_FLAG_WRITE)) {
// pte 既然变化了,则刷新 mmu (体系结构相关)
update_mmu_cache(vmf->vma, vmf->address, vmf->pte);
} else {
// 如果 pte 内容本身没有变化,则不需要刷新任何东西
// 但是有个特殊情况就是写保护类型中断,产生的写时复制,产生了新的映射关系,需要刷新一下 tlb
/*
* This is needed only for protection faults but the arch code
* is not yet telling us if this is a protection fault or not.
* This still avoids useless tlb flushes for .text page faults
* with threads.
*/
if (vmf->flags & FAULT_FLAG_WRITE)
flush_tlb_fix_spurious_fault(vmf->vma, vmf->address);
}
return 0;
}7. do_anonymous_page 处理匿名页缺页
在之前完成了各级页目录的补齐填充工作,但是现在最后一级页表还没有着落,所以在处理缺页之前,我们需要调用 pte_alloc 继续把页表补齐了。
#define pte_alloc(mm, pmd) (unlikely(pmd_none(*(pmd))) && __pte_alloc(mm, pmd))首先我们通过 pmd_none 判断缺页地址 address 在进程页表中间页目录 PMD 中对应的页目录项 pmd 是否是空的,如果 pmd 是空的,说明此时还不存在一级页表,这样一来,就需要调用 __pte_alloc 来分配一张页表,然后用页表的 pfn 以及初始权限位 _PAGE_TABLE 来填充 pmd。
static inline void pmd_populate(struct mm_struct *mm, pmd_t *pmd,
struct page *pte)
{
// 通过页表 page 获取对应的 pfn
unsigned long pfn = page_to_pfn(pte);
// 将页表 page 的 pfn 以及初始权限位 _PAGE_TABLE 填充到 pmd 中
set_pmd(pmd, __pmd(((pteval_t)pfn << PAGE_SHIFT) | _PAGE_TABLE));
}都是创建其下一级页目录或者页表,然后填充对应的页目录项:
现在我们已经有了一级页表,但是页表中的 pte 还都是空的,接下来就该用这个空的 pte 来映射物理内存页了。首先我们通过 alloc_zeroed_user_highpage_movable 来分配一个物理内存页出来。这个物理内存页就是为缺页地址 address 映射的物理内存了,随后我们通过 mk_pte 利用物理内存页 page 的 pfn 以及缺页内存区域 vma 中记录的页属性 vma->vm_page_prot 填充一个新的页表项 entry 出来。
entry 这里只是一个临时的值,后续会将 entry 的值设置到真正的 pte 中。
#define mk_pte(page, pgprot) pfn_pte(page_to_pfn(page), (pgprot))
如果缺页内存地址 address 所在的虚拟内存区域 vma 是可写的,那么我们就通过 pte_mkwrite 和 pte_mkdirty 将临时页表项 entry 的 R/W(1) 比特位和D(6) 比特位置为 1 。表示该页表项背后映射的物理内存页 page 是可写的,并且标记为脏页。注意,此时缺页内存地址 address 在页表中的 pte 还是空的,我们还没有设置呢,目前只是先将值初始化到临时的页表项 entry 中,下面才到设置真正的 pte 的时候。
调用 pte_offset_map_lock,首先获取 address 在一级页表中的真正 pte,然后将一级页表锁定。
#define pte_offset_map_lock(mm, pmd, address, ptlp) \
({ \
// 获取 pmd 映射的一级页表锁
spinlock_t *__ptl = pte_lockptr(mm, pmd); \
// 获取 pte
pte_t *__pte = pte_offset_map(pmd, address); \
*(ptlp) = __ptl; \
// 锁定一级页表
spin_lock(__ptl); \
__pte; \
})按理说此时获取到的 pte 应该是空的,如果 pte 不为空,说明已经有其他线程把缺页处理好了,pte 已经被填充了,那么本次缺页处理就该停止,不能在往下走了,直接跳转到 release 处,释放页表锁,释放新分配的物理内存页 page。
if (!pte_none(*vmf->pte))
goto release;如果 pte 为空,说明此时没有其他线程对缺页进行并发处理,我们可以接着处理缺页。
进程使用到的常驻内存等相关统计信息保存在 task->rss_stat 字段中:
struct task_struct {
// 统计进程常驻内存信息
struct task_rss_stat rss_stat;
}由于这里我们新分配一个匿名内存页用于缺页处理,所以相关 rss_stat 统计信息 —— task->rss_stat.count[MM_ANONPAGES] 要加 1 。
// MM_ANONPAGES —— Resident anonymous pages
inc_mm_counter_fast(vma->vm_mm, MM_ANONPAGES);
#define inc_mm_counter_fast(mm, member) add_mm_counter_fast(mm, member, 1)
static void add_mm_counter_fast(struct mm_struct *mm, int member, int val)
{
struct task_struct *task = current;
if (likely(task->mm == mm))
task->rss_stat.count[member] += val;
else
add_mm_counter(mm, member, val);
}随后调用 page_add_new_anon_rmap 建立匿名页的反向映射关系,反向映射建立好之后,调用 lru_cache_add_active_or_unevictable 将匿名内存页加入到 LRU 活跃链表中。最后调用 set_pte_at 将之间我们临时填充的页表项 entry 赋值给缺页 address 真正对应的 pte。
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
#define set_pte_at(mm, addr, ptep, pte) native_set_pte_at(mm, addr, ptep, pte)
static inline void native_set_pte_at(struct mm_struct *mm, unsigned long addr,
pte_t *ptep , pte_t pte)
{
native_set_pte(ptep, pte);
}
static inline void native_set_pte(pte_t *ptep, pte_t pte)
{
WRITE_ONCE(*ptep, pte);
}到这里我们才算是真正把进程的页表体系给补齐了。
8. do_fault 处理文件页缺页
之前提到 mmap 文件映射的源码实现时,特别强调了一下,mmap 内存文件映射的本质其实就是将虚拟映射区 vma 的相关操作 vma->vm_ops 映射成文件的相关操作 ext4_file_vm_ops。
在 vma->vm_ops 中有个重要的函数 fault,在 ext4 文件系统中的实现是:ext4_filemap_fault 函数。
static const struct vm_operations_struct ext4_file_vm_ops = {
.fault = ext4_filemap_fault,
.map_pages = filemap_map_pages,
.page_mkwrite = ext4_page_mkwrite,
};vma->vm_ops->fault 函数就是专门用于处理文件映射区缺页的。而文件页的缺页处理的核心就是依赖这个函数完成的。我们知道 mmap 进行文件映射的时候只是单纯地建立了虚拟内存与文件之间的映射关系,此时并没有物理内存分配。当进程对这段文件映射区进行读取操作的时候,会触发缺页,然后分配物理内存(文件页),这一部分逻辑在下面的 do_read_fault 函数中完成,它主要处理的是由于对文件映射区的读取操作而引起的缺页情况。
而 mmap 文件映射又分为私有文件映射与共享文件映射两种映射方式,而私有文件映射的核心特点是读共享的,当任意进程对私有文件映射区发生写入操作时候,就会发生写时复制 COW,这一部分逻辑在下面的 do_cow_fault 函数中完成。
对共享文件映射区进行的写入操作而引起的缺页,内核放在 do_shared_fault 函数中进行处理。
static vm_fault_t do_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct mm_struct *vm_mm = vma->vm_mm;
vm_fault_t ret;
// 处理 vm_ops->fault 为 null 的异常情况
if (!vma->vm_ops->fault) {
// 如果中间页目录 pmd 指向的一级页表不在内存中,则返回 SIGBUS 错误
if (unlikely(!pmd_present(*vmf->pmd)))
ret = VM_FAULT_SIGBUS;
else {
// 获取缺页的页表项 pte
vmf->pte = pte_offset_map_lock(vmf->vma->vm_mm,
vmf->pmd,
vmf->address,
&vmf->ptl);
// pte 为空,则返回 SIGBUS 错误
if (unlikely(pte_none(*vmf->pte)))
ret = VM_FAULT_SIGBUS;
else
// pte 不为空,返回 NOPAGE,即本次缺页处理不会分配物理内存页
ret = VM_FAULT_NOPAGE;
pte_unmap_unlock(vmf->pte, vmf->ptl);
}
} else if (!(vmf->flags & FAULT_FLAG_WRITE))
// 缺页如果是读操作引起的,进入 do_read_fault 处理
ret = do_read_fault(vmf);
else if (!(vma->vm_flags & VM_SHARED))
// 缺页是由私有映射区的写入操作引起的,则进入 do_cow_fault 处理写时复制
ret = do_cow_fault(vmf);
else
// 处理共享映射区的写入缺页
ret = do_shared_fault(vmf);
return ret;
}8.1 do_read_fault 处理读操作引起的缺页
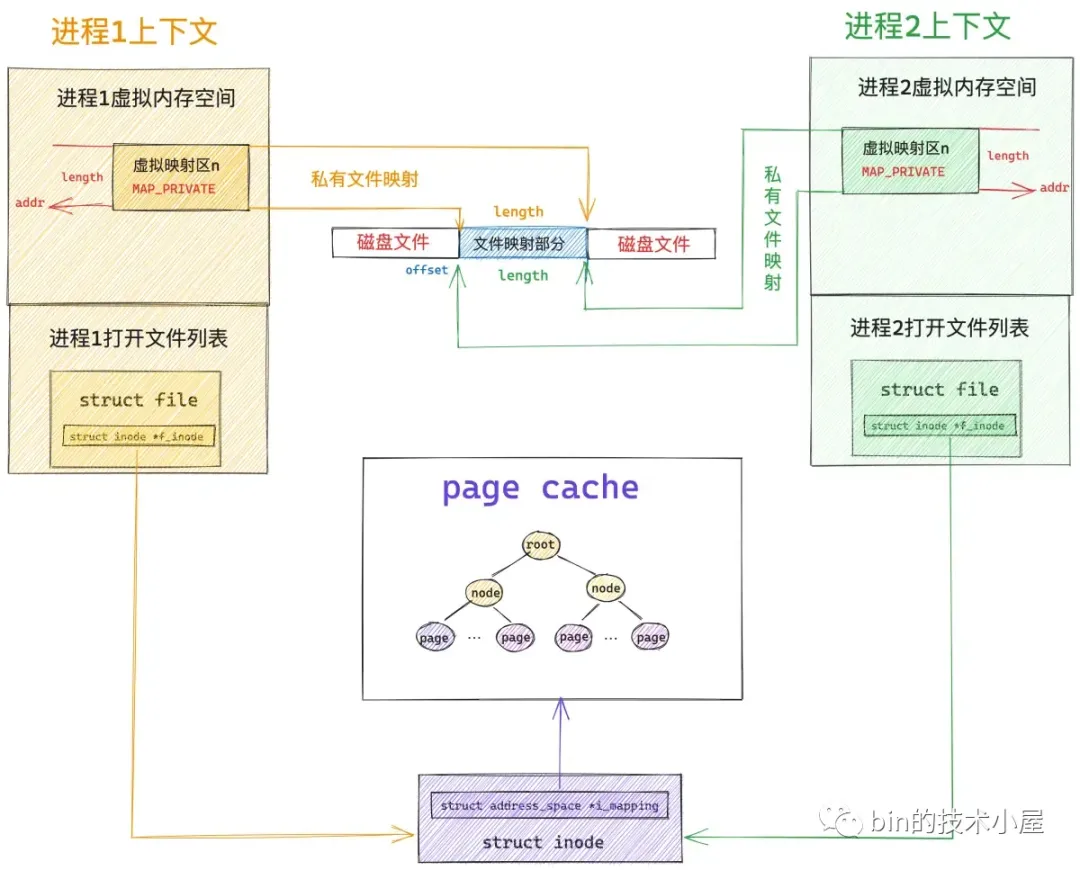
当我们调用 mmap 对文件进行映射的时候,无论是采用私有文件映射的方式还是共享文件映射的方式,内核都只是会在进程的地址空间中为本次映射创建出一段虚拟映射区 vma 出来,然后将这段虚拟映射区 vma 与映射文件关联起来就结束了,整个映射过程并未涉及到物理内存的分配。
下面是多进程对同一文件中的同一段文件区域进行私有映射后,内核中的结构图:
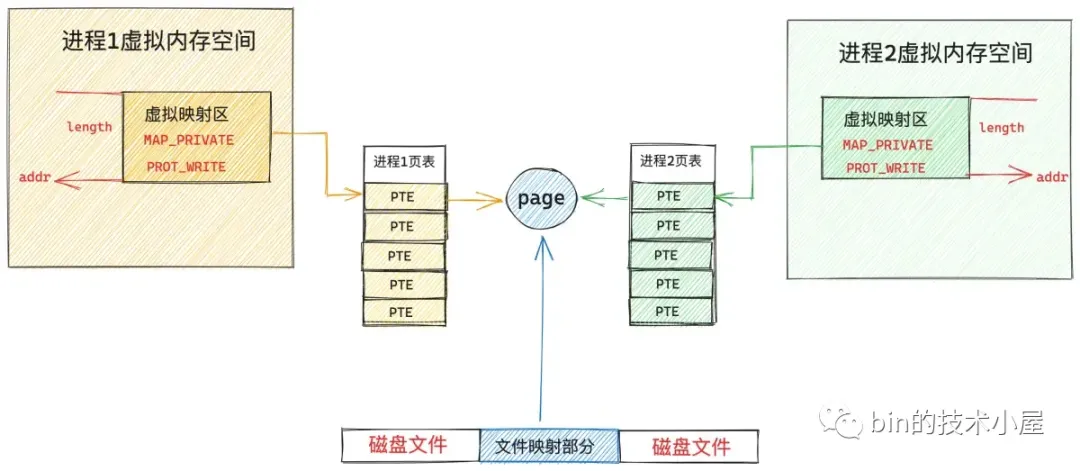
当任意进程开始访问其地址空间中的这段虚拟内存区域 vma 时,由于背后没有对应文件页进行映射,所以会发生缺页中断,在缺页中断中内核会首先分配一个物理内存页并加入到 page cache 中,随后将映射的文件内容读取到刚刚创建出来的物理内存页中,然后将这个物理内存页映射到缺页虚拟内存地址 address 对应在进程页表中的 pte 中。
除此之外,内核还会考虑到进程访问内存的空间局部性,所以内核除了会映射本次缺页需要的文件页之外,还会将其相邻的文件页读取到 page cache 中,然后将这些相邻的文件页映射到对应的 pte 中。这一部分预先提前映射的逻辑在 map_pages 函数中实现。
static const struct vm_operations_struct ext4_file_vm_ops = {
.fault = ext4_filemap_fault,
.map_pages = filemap_map_pages,
.page_mkwrite = ext4_page_mkwrite,
};如果不满足预先提前映射的条件,那么内核就只会专注处理映射本次缺页所需要的文件页。首先通过上面的 fault 函数,当映射文件所在文件系统是 ext4 时,该函数的实现为 ext4_filemap_fault,该函数只负责获取本次缺页所需要的文件页。
当获取到文件页之后,内核会调用 finish_fault 函数,将文件页映射到缺页地址 address 在进程页表中对应的 pte 中,do_read_fault 函数处理就完成了,不过需要注意的是,对于私有文件映射的话,此时的这个 pte 还是只读的,多进程之间读共享,当任意进程尝试写入的时候,会发生写时复制。内核在这里首先会调用 find_get_page 从 page cache 中尝试获取文件页,如果文件页存在,则继续调用 do_async_mmap_readahead 启动异步预读机制,将相邻的若干文件页一起预读进 page cache 中。
如果文件页不在 page cache 中,内核则会调用 do_sync_mmap_readahead 来同步预读,这里首先会分配一个物理内存页出来,然后将新分配的内存页加入到 page cache 中,并增加页引用计数。
随后会通过 address_space_operations 中定义的 readpage 激活块设备驱动从磁盘中读取映射的文件内容,然后将读取到的内容填充新分配的内存页中。并同步预读若干相邻的文件页到 page cache 中。文件页现在有了,接下来内核就会调用 finish_fault 将文件页映射到 pte 中。通过alloc_set_pte 将之前我们准备好的文件页,映射到缺页地址 address 在进程页表对应的 pte 中。
8.2 do_cow_fault 处理私有文件映射的写时复制
上小节 do_read_fault 函数处理的场景是,进程在调用 mmap 对文件进行私有映射或者共享映射之后,立马进行读取的缺页场景。
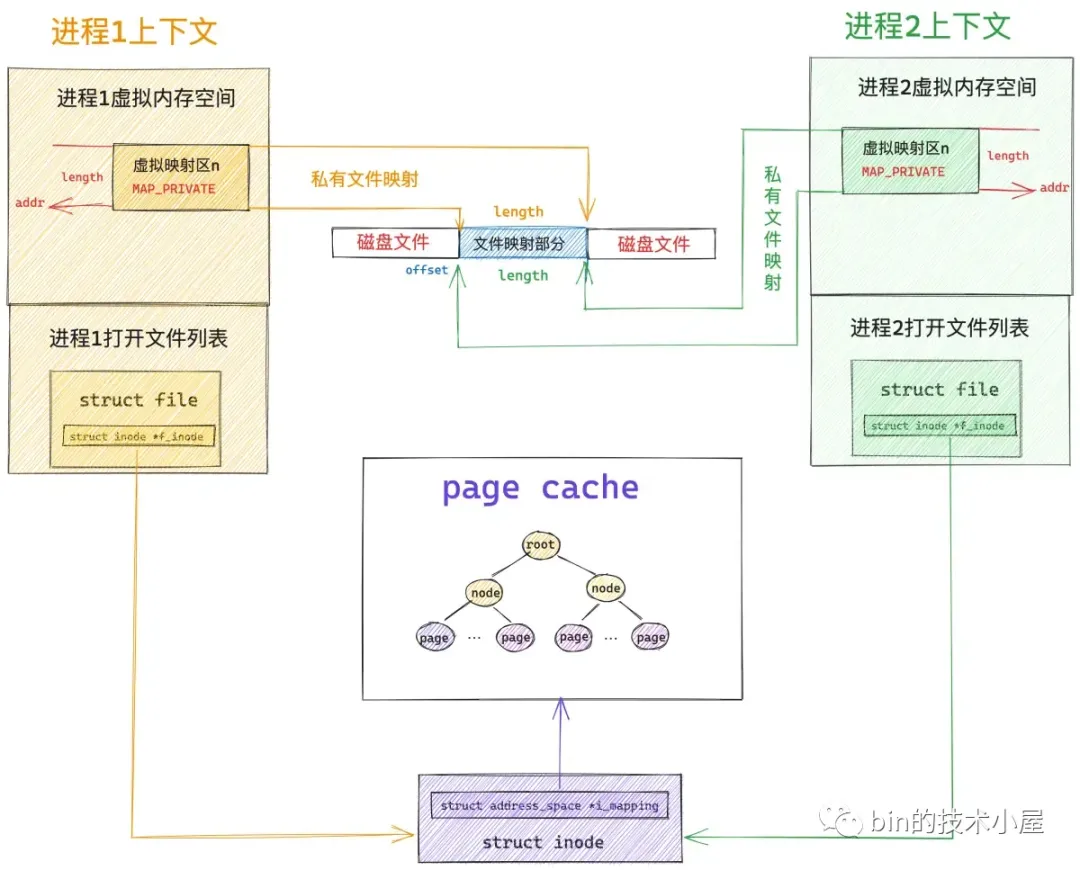
但是如果当我们采用的是 mmap 进行私有文件映射时,在映射之后,立马进行写入操作时,就会发生写时复制,写时复制的缺页处理流程内核封装在 do_cow_fault 函数中。由于我们这里要进行写时复制,所以首先要调用 alloc_page_vma 从伙伴系统中重新申请一个物理内存页出来,我们先把这个刚刚新申请出来用于写时复制的内存页称为 cow_page。
然后调用 __do_fault 函数,将原来的文件页从 page cache 中读取出来,我们把原来的文件页称为 page 。最后调用 copy_user_highpage 将原来文件页 page 中的内容拷贝到刚刚新申请的内存页 cow_page 中,完成写时复制之后,接着调用 finish_fault 将 cow_page 映射到缺页地址 address 在进程页表中的 pte 上。
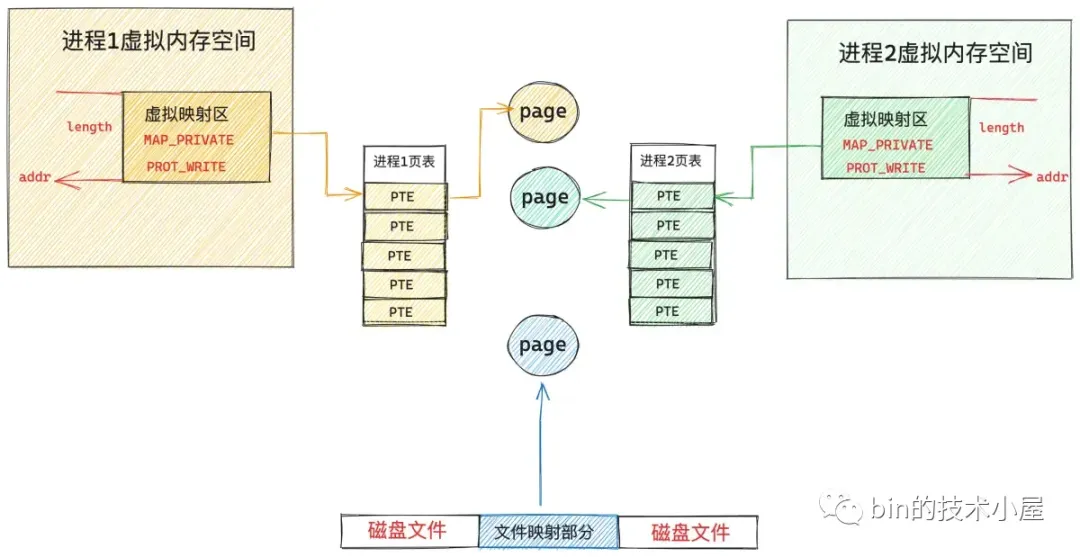
这样一来,进程的这段虚拟文件映射区就映射到了专属的物理内存页 cow_page 上,而且内容和原来文件页 page 中的内容一模一样,进程对各自虚拟内存区的修改只能反应到各自对应的 cow_page上,而且各自的修改在进程之间是互不可见的。
由于 cow_page 已经脱离了 page cache,所以这些修改也都不会回写到磁盘文件中,这就是私有文件映射的核心特点。
8.3 do_shared_fault 处理对共享文件映射区写入引起的缺页
如果我们调用 mmap 对文件进行共享文件映射之后,然后立即对虚拟映射区进行写入操作,这背后的缺页处理逻辑又是怎样的呢 ?
其实和之前的文件缺页处理逻辑的核心流程都差不多,不同的是由于这里我们进行的共享文件映射,所以多个进程中的虚拟文件映射区都会映射到 page cache 中的文件页上,由于没有写时复制,所以进程对文件页的修改都会直接反映到 page cache 中,近而后续会回写到磁盘文件上。
由于共享文件映射涉及到脏页回写,所以在共享文件映射的缺页处理场景中,为了防止数据的丢失会额外有一些文件系统日志的记录工作。
9. do_wp_page 进行写时复制
do_wp_page 函数和之前介绍的 do_cow_fault 函数都是用于处理写时复制的,其最为核心的逻辑都是差不多的,只是在触发场景上会略有不同:
- do_cow_fault 函数主要处理的写时复制场景是,当我们使用 mmap 进行私有文件映射时,在刚映射完之后,此时进程的页表或者相关页表项 pte 还是空的,就立即进行写入操作。
- do_wp_page 函数主要处理的写时复制场景是,访问的这块虚拟内存背后是有物理内存页映射的,对应的 pte 不为空,只不过相关 pte 的权限是只读的,而虚拟内存区域 vma 是有写权限的,在这种类型的虚拟内存进行写入操作的时候,触发的写时复制就在 do_wp_page 函数中处理。
比如,我们使用 mmap 进行私有文件映射之后,此时只是分配了虚拟内存,进程页表或者相关 pte 还是空的,这时对这块映射的虚拟内存进行访问的时候就会触发缺页中断,最后在之前介绍的 do_read_fault 函数中将映射的文件内容加载到 page cache 中,pte 指向 page cache 中的文件页。
但此时的 pte 是只读的,如果我们对这块映射的虚拟内存进行写入操作,就会发生写时复制,由于现在 pte 不为空,背后也映射着文件页,所以会在 do_wp_page 函数中进行处理。除了私有映射的文件页之外,do_wp_page 还会对匿名页相关的写时复制进行处理。比如,我们通过 fork 系统调用创建子进程的时候,内核会拷贝父进程占用的所有资源到子进程中,其中也包括了父进程的地址空间以及父进程的页表。
一个进程中申请的物理内存页既会有文件页也会有匿名页,而这些文件页和匿名页既可以是私有的也可以是共享的,当内核在拷贝父进程的页表时,如果遇到私有的匿名页或者文件页,就会将其对应在父子进程页表中的 pte 设置为只读,进行写保护。并将父子进程共同引用的匿名页或者文件页的引用计数加 1。
static inline unsigned long
copy_one_pte(struct mm_struct *dst_mm, struct mm_struct *src_mm,
pte_t *dst_pte, pte_t *src_pte, struct vm_area_struct *vma,
unsigned long addr, int *rss)
{
/*
* If it's a COW mapping, write protect it both
* in the parent and the child
*/
if (is_cow_mapping(vm_flags) && pte_write(pte)) {
// 设置父进程的 pte 为只读
ptep_set_wrprotect(src_mm, addr, src_pte);
// 设置子进程的 pte 为只读
pte = pte_wrprotect(pte);
}
// 获取 pte 中映射的物理内存页(此时父子进程共享该页)
page = vm_normal_page(vma, addr, pte);
// 物理内存页的引用技术 + 1
get_page(page);
}
static inline bool is_cow_mapping(vm_flags_t flags)
{
// vma 是私有可写的
return (flags & (VM_SHARED | VM_MAYWRITE)) == VM_MAYWRITE;
}现在父子进程拥有了一模一样的地址空间,页表是一样的,页表中的 pte 均指向同一个物理内存页面,对于私有的物理内存页来说,父子进程的相关 pte 此时均变为了只读的,私有物理内存页的引用计数为 2 。而对于共享的物理内存页来说,内核就只是简单的将父进程的 pte 拷贝到子进程页表中即可,然后将子进程 pte 中的脏页标记清除,其他的不做改变。
当父进程或者子进程对该页面发生写操作的时候,我们现在假设子进程先对页面发生写操作,随后子进程发现自己页表中的 pte 是只读的,于是就会产生写保护类型的缺页中断,由于子进程页表中的 pte 不为空,所以会进入到 do_wp_page 函数中处理。
由于现在子进程和父子进程页表中的相关 pte 指向的均是同一个物理内存页,内核在 do_wp_page 函数中会发现这个物理内存页的引用计数大于 1,存在多进程共享的情况,所以就会触发写时复制,这一过程在 wp_page_copy 函数中处理。
在 wp_page_copy 函数中,内核会首先为子进程分配一个新的物理内存页 new_page,然后调用 cow_user_page 将原有内存页 old_page 中的内容全部拷贝到新内存页中。创建一个临时的页表项 entry,然后让 entry 指向新的内存页,将 entry 重新设置为可写,通过 set_pte_at_notify 将 entry 值设置到子进程页表中的 pte 上。最后将原有内存页 old_page 的引用计数减 1 。
现在子进程处理完了,下面我们再来看当父进程发生写入操作的时候会发生什么 ?
首先和子进程一样,现在父进程页表中的相关 pte 仍然是只读的,访问这段虚拟内存地址依然会产生写保护类型的缺页中断,和子进程不同的是,此时父进程 pte 中指向的原有物理内存页 old_page 的引用计数已经变为 1 了,说明父进程是独占的,复用原来的 old_page 即可,不必进行写时复制,只是简单的将父进程页表中的相关 pte 改为可写就行了。
理解了上面的核心内容,我们再来看 do_wp_page 的处理逻辑就很清晰了:
static vm_fault_t do_wp_page(struct vm_fault *vmf)
__releases(vmf->ptl)
{
struct vm_area_struct *vma = vmf->vma;
// 获取 pte 映射的物理内存页
vmf->page = vm_normal_page(vma, vmf->address, vmf->orig_pte);
...... 省略处理特殊映射相关逻辑 ....
// 物理内存页为匿名页的情况
if (PageAnon(vmf->page)) {
...... 省略处理 ksm page 相关逻辑 ....
// reuse_swap_page 判断匿名页的引用计数是否为 1
if (reuse_swap_page(vmf->page, &total_map_swapcount)) {
// 如果当前物理内存页的引用计数为 1 ,并且只有当前进程在引用该物理内存页
// 则不做写时复制处理,而是复用当前物理内存页,只是将 pte 改为可写即可
wp_page_reuse(vmf);
return VM_FAULT_WRITE;
}
unlock_page(vmf->page);
} else if (unlikely((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))) {
// 处理共享可写的内存页
// 由于大家都可写,所以这里也只是调用 wp_page_reuse 复用当前内存页即可,不做写时复制处理
// 由于是共享的,对于文件页来说是可以回写到磁盘上的,所以会额外调用一次 fault_dirty_shared_page 判断是否进行脏页的回写
return wp_page_shared(vmf);
}
copy:
// 走到这里表示当前物理内存页的引用计数大于 1 被多个进程引用
// 对于私有可写的虚拟内存区域来说,就要发生写时复制
// 而对于私有文件页的情况来说,不必判断内存页的引用计数
// 因为是私有文件页,不管文件页的引用计数是不是 1 ,都要进行写时复制
return wp_page_copy(vmf);
}10. do_swap_page 处理 swap 缺页异常
如果在遍历进程页表的时候发现,虚拟内存地址 address 对应的页表项 pte 不为空,但是 pte 中第 0 个比特位置为 0 ,则表示该 pte 之前是被物理内存映射过的,只不过后来被内核 swap out 出去了。
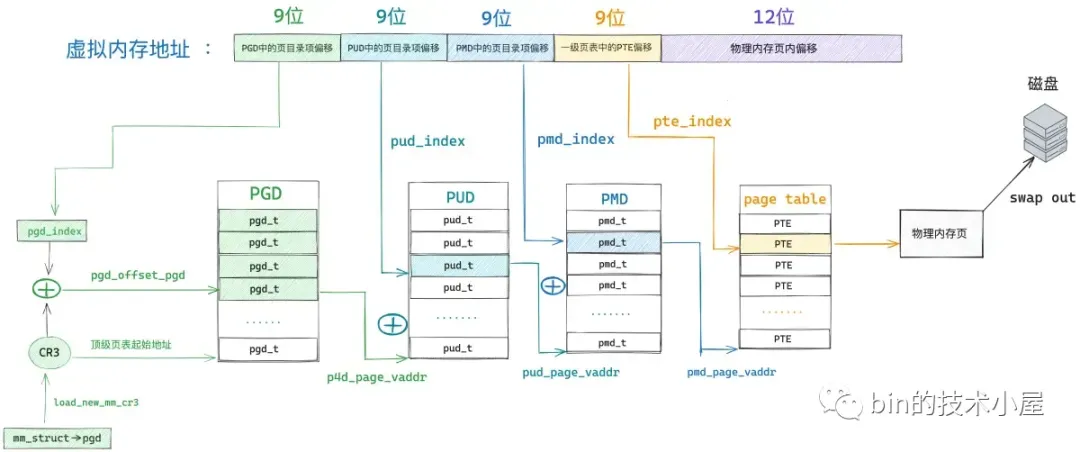
我们需要的物理内存页不在内存中反而在磁盘中,现在我们就需要将物理内存页从磁盘中 swap in 进来。但在 swap in 之前内核需要知道该物理内存页的内容被保存在磁盘的什么位置上。
64 位的 pte 主要用来表示物理内存页的地址以及相关的权限标识位,但是当物理内存页不在内存中的时候,这些比特位就没有了任何意义。我们何不将这些已经没有任何意义的比特位利用起来,在物理内存页被 swap out 到磁盘上的时候,将物理内存页在磁盘上的位置保存在这些比特位中。本质上还利用的是之前 pte 中的那 64 个比特,为了区别 swap 的场景,内核使用了一个新的结构体 swp_entry_t 来包装。
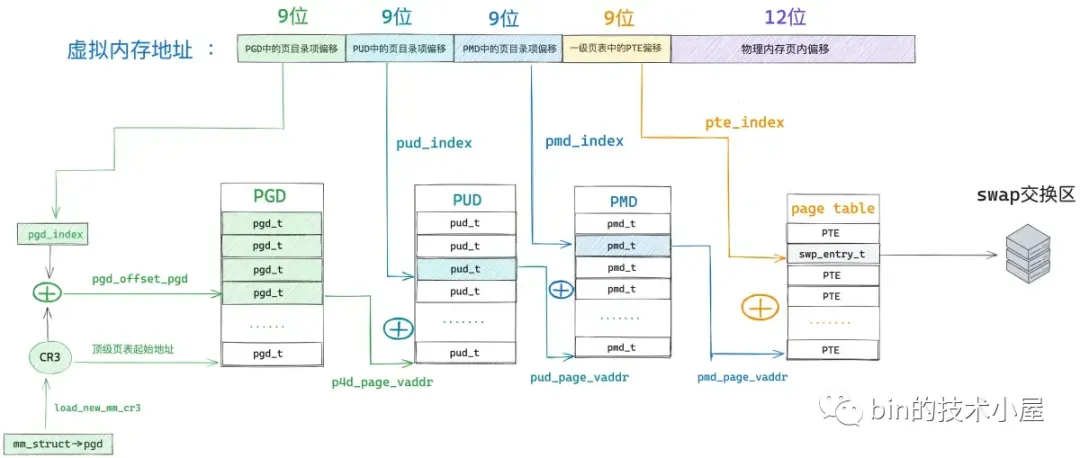
swap in 的首要任务就是先要从进程页表中将这个 swp_entry_t 读取出来,然后从 swp_entry_t 中解析出内存页在 swap 交换区中的位置,根据磁盘位置信息将内存页的内容读取到内存中。由于产生了新的物理内存页,所以就要创建新的 pte 来映射这个物理内存页,然后将新的 pte 设置到页表中,替换原来的 swp_entry_t。
10.1 交换区的布局及其组织结构
要明白这个,我们就需要先了解一下 swap 交换区(swap area)的布局,swap 交换区共有两种类型,一种是 swap 分区(swap partition),另一种是 swap 文件(swap file)。
- swap partition 可以认为是一个没有文件系统的裸磁盘分区,分区中的磁盘块在磁盘中是连续分布的。
- swap file 可以认为是在某个现有的文件系统上,创建的一个定长的普通文件,专门用于保存匿名页被 swap 出来的内容。背后的磁盘块是不连续的。
Linux 系统中可以允许多个这样的 swap 交换区存在,我们可以同时使用多个交换区,也可以为这些交换区指定优先级,优先级高的会被内核优先使用。这些交换区都可以被灵活地添加,删除,而不需要重启系统。多个交换区可以分散在不同的磁盘设备上,这样可以实现硬件的并行访问。
在使用交换区之前,我们可以通过 mkswap 首先创建一个交换区出来,如果我们创建的是 swap partition,则在 mkswap 命令后面直接指定分区的设备文件名称即可。
mkswap /dev/sdb7如果我们创建的是 swap file,则需要额外先使用 dd 命令在现有文件系统中创建出一个定长的文件出来。比如下面通过 dd 命令从 /dev/zero 中拷贝创建一个 /swapfile 文件,大小为 4G。
dd if=/dev/zero of=/swapfile bs=1M count=4096然后使用 mkswap 命令创建 swap file :
mkswap /swapfile当 swap partition 或者 swap file 创建好之后,我们通过 swapon 命令来初始化并激活这个交换区。
swapon /swapfile在每个交换区 swap area 内部又会分为很多连续的 slot (槽),每个 slot 的大小刚好和一个物理内存页的大小相同都是 4K,物理内存页在被 swap out 到交换区时,就会存放在 slot 中。交换区中的这些 slot 会被组织在一个叫做 swap_map 的数组中,数组中的索引就是 slot 在交换区中的 offset (这个位置信息很重要),数组中的值表示该 slot 总共被多少个进程同时引用。
什么意思呢 ? 比如现在系统中一共有三个进程同时共享一个物理内存页(内存中的概念),当这个物理内存页被 swap out 到交换区上时,就变成了 slot (内存页在交换区中的概念),现在物理内存页没了,这三个共享进程就只能在各自的页表中指向这个 slot,因此该 slot 的引用计数就是 3,对应在数组 swap_map 中的值也是 3 。
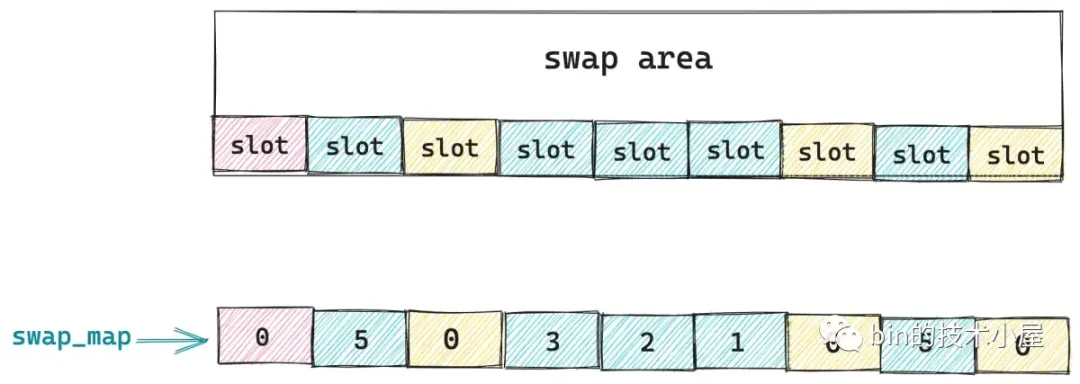
交换区中的第一个 slot 用于存储交换区的元信息,比如交换区对应底层各个磁盘块的坏块列表。swap_map 数组中的值表示的就是对应 slot 被多少个进程同时引用,值为 0 表示该 slot 是空闲的,下次 swap out 的时候首先查找的就是空闲 slot 。 查找范围就是 lowest_bit 到 highest_bit 之间的 slot。当查找到空闲 slot 之后,就会将整个物理内存页回写到这个 slot 中。
struct swap_info_struct {
unsigned char *swap_map; /* vmalloc'ed array of usage counts */
unsigned int lowest_bit; /* index of first free in swap_map */
unsigned int highest_bit; /* index of last free in swap_map */但是这里会有一个问题就是交换区面向的是整个系统,而系统中会有很多进程,如果多个进程并发进行 swap 的时候,swap_map 数组就会面临并发操作的问题,这样一来就不得不需要一个全局锁来保护,但是这也导致了多个 CPU 只能串行访问,大大降低了并发度。
于是内核会将锁分段,这样可以将锁竞争分散开来,大大提升并发度。将 swap_map 数组中的这些 slot,按照常量 SWAPFILE_CLUSTER 指定的个数,256 个 slot 分为一个 cluster。
#define SWAPFILE_CLUSTER 256每个 cluster 中包含一把 spinlock_t 锁,如果 cluster 是空闲的,那么 swap_cluster_info 结构中的 data 指向下一个空闲的 cluster,如果 cluster 不是空闲的,那么 data 保存的是该 cluster 中已经分配的 slot 个数。为了进一步利用 cpu cache,以及实现无锁化查找 slot,内核会给每个 cpu 分配一个 cluster —— percpu_cluster,cpu 直接从自己的 cluster 中查找空闲 slot,近一步提高了 swap out 的吞吐。当 cpu 自己的 percpu_cluster 用尽之后,内核则会调用 swap_alloc_cluster 函数从 free_clusters 中获取一个新的 cluster。
现在交换区的整体布局为大家介绍完了,这里我们把交换区 swap_info_struct 与进程的内存空间 mm_struct 放到一起一对比:
首先进程虚拟内存空间中的虚拟内存别管说的如何天花乱坠,说到底还是要保存在真实的物理内存中的,虚拟内存与物理内存通过页表来关联起来。同样的道理,别管交换区布局的如何天花乱坠,swap out 出来的数据说到底还是要保存在真实的磁盘中的,而交换区中是按照 slot 为单位进行组织管理的,磁盘中是按照磁盘块来组织管理的,大小都是 4K 。
交换区中的 slot 就好比于虚拟内存空间中的虚拟内存,都是虚拟的概念,物理内存页与磁盘块才是真实本质的东西。虚拟内存是连续的,但其背后映射的物理内存可能是不连续,交换区中的 slot 也都是连续的,但磁盘中磁盘块的扇区地址却不一定是连续的。页表可以将不连续的物理内存映射到连续的虚拟内存上,内核也需要一种机制,将不连续的磁盘块映射到连续的 slot 中。
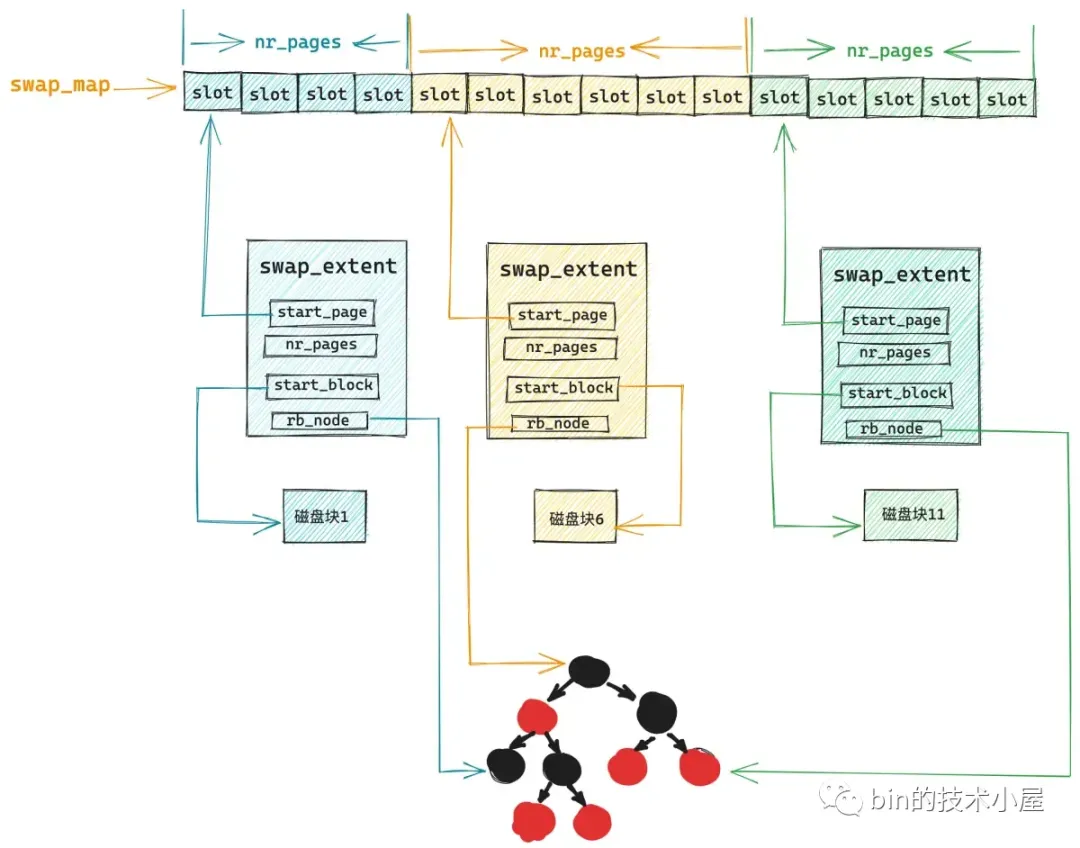
当我们使用 swapon 命令来初始化激活交换区时,内核会扫描交换区中各个磁盘块的扇区地址,以确定磁盘块与扇区的对应关系,然后搜集扇区地址连续的磁盘块,将这些连续的磁盘块组成一个块组,slot 就会一个一个的映射到这些块组上,块组之间的扇区地址是不连续的,但是 slot 是连续的。
/*
* A swap extent maps a range of a swapfile's PAGE_SIZE pages onto a range of
* disk blocks. A list of swap extents maps the entire swapfile. (Where the
* term `swapfile' refers to either a blockdevice or an IS_REG file. Apart
* from setup, they're handled identically.
*
* We always assume that blocks are of size PAGE_SIZE.
*/
struct swap_extent {
// 红黑树节点
struct rb_node rb_node;
// 块组内,第一个映射的 slot 编号
pgoff_t start_page;
// 映射的 slot 个数
pgoff_t nr_pages;
// 块组内第一个磁盘块
sector_t start_block;
};由于一个块组内的磁盘块都是连续的,slot 本来又是连续的,所以 swap_extent 结构中只需要保存映射到该块组内第一个 slot 的编号 (start_page),块组内第一个磁盘块在磁盘上的块号,以及磁盘块个数就可以了。
虚拟内存页类比 slot,物理内存页类比磁盘块,这里的 swap_extent 可以看做是虚拟内存区域 vma,进程的虚拟内存空间正是由一段一段的 vma 组成,这些 vma 被组织在一颗红黑树上。
交换区也是一样,它是由一段一段的 swap_extent 组成,同样也会被组织在一颗红黑树上。我们可以通过 slot 在交换区中的 offset,在这颗红黑树中快速查找出 slot 背后对应的磁盘块。
10.2 swp_entry_t
匿名内存页在被内核 swap out 到磁盘上之后,内存页中的内容保存在交换区的 slot 中,在 swap in 的场景中,内核需要根据 swp_entry_t 里的信息找到这个 slot,进而找到其对应的磁盘块,然后从磁盘块中读取出被 swap out 出去的内容。
我们首先需要知道匿名内存页到底被 swap out 到哪个交换区里了,所以 swp_entry_t 里必须包含交换区在 swap_info 数组中的索引,而这个索引正是 swap_info_struct 结构中的 type 字段。
struct swap_info_struct {
// 该交换区在 swap_info 数组中的索引
signed char type;
}在确定了交换区的位置后,我们需要知道匿名页被 swap out 到交换区中的哪个 slot 中,所以 swp_entry_t 中也必须包含 slot 在交换区中的 offset,这个 offset 就是 swap_info_struct 结构里 slot 所在 swap_map 数组中的下标。
struct swap_info_struct {
unsigned char *swap_map;
}所以总结下来 swp_entry_t 中需要包含以下三种信息:
- 第一, swp_entry_t 需要标识该页表项是一个 pte 还是 swp_entry_t,因为它俩本质上是一样的,都是
unsigned long类型的无符号整数,是可以相互转换的。第 0 个比特位置 1 表示是一个 pte,背后映射的物理内存页存在于内存中。如果第 0 个比特位置 0 则表示该 pte 背后映射的物理内存页已经被 swap out 出去了,那么它就是一个 swp_entry_t,指向内存页在交换区中的位置。
#define __pte_to_swp_entry(pte) ((swp_entry_t) { pte_val(pte) })
#define __swp_entry_to_pte(swp) ((pte_t) { (swp).val })- 第二,swp_entry_t 需要包含被 swap 出去的匿名页所在交换区的索引 type,第 2 个比特位到第 7 个比特位,总共使用 6 个比特来表示匿名页所在交换区的索引。
- 第三,swp_entry_t 需要包含匿名页所在 slot 的位置 offset,第 8 个比特位到第 57 个比特位,总共 50 个比特来表示匿名页对应的 slot 在交换区的 offset 。
内核提供了宏 __swp_type 用于从 swp_entry_t 中将匿名页所在交换区编号提取出来,还提供了宏 __swp_offset 用于从 swp_entry_t 中将匿名页所在 slot 的 offset 提取出来。先获取交换区所在磁盘分区底层的块设备,然后利用 offset 在红黑树 swap_extent_root 中查找其对应的 swap_extent。
前面我们提到过 swap file 背后所在的磁盘块不一定是连续的,而 swap file 中的 slot 却是连续的,内核需要用 swap_extent 结构来描述 slot 与磁盘块的映射关系。所以对于 swap file 来说,我们找到了 swap_extent 也就确定了 slot 对应的磁盘块了。终于我们就获得了slot 对应的磁盘块 sector_t 。有了 sector_t,内核接着就会利用 bdev_read_page 函数将 slot 对应在 sector 中的内容读取到物理内存页 page 中,这就是整个 swap in 的过程。
swap_readpage 函数负责将匿名页中的内容从交换区中读取到物理内存页中来,这里也是 swap in 的核心实现:
int swap_readpage(struct page *page, bool synchronous)
{
struct bio *bio;
int ret = 0;
struct swap_info_struct *sis = page_swap_info(page);
blk_qc_t qc;
struct gendisk *disk;
// 处理交换区是 swap file 的情况
if (sis->flags & SWP_FS) {
// 从交换区中获取交换文件 swap_file
struct file *swap_file = sis->swap_file;
// swap_file 本质上还是文件系统中的一个文件,所以它也会有 page cache
struct address_space *mapping = swap_file->f_mapping;
// 利用 page cache 中的 readpage 方法,从 swap_file 所在的文件系统中读取匿名页内容到 page 中。
// 注意这里只是利用 page cache 的 readpage 方法从文件系统中读取数据,内核并不会把 page 加入到 page cache 中
// 这里 swap_file 和普通文件的读取过程是不一样的,page cache 不缓存内存页。
// 对于 swap out 的场景来说,内核也只是利用 page cache 的 writepage 方法将匿名页的内容写入到 swap_file 中。
ret = mapping->a_ops->readpage(swap_file, page);
if (!ret)
count_vm_event(PSWPIN);
return ret;
}
// 如果交换区是 swap partition,则直接从磁盘块中读取
// 对于 swap out 的场景,内核调用 bdev_write_page,直接将匿名页的内容写入到磁盘块中
ret = bdev_read_page(sis->bdev, swap_page_sector(page), page);
out:
return ret;
}swap_readpage 是内核 swap 机制的最底层实现,直接和磁盘打交道,负责搭建磁盘与内存之间的桥梁。虽然直接调用 swap_readpage 可以基本完成 swap in 的目的,但在某些特殊情况下会导致 swap 的性能非常糟糕。
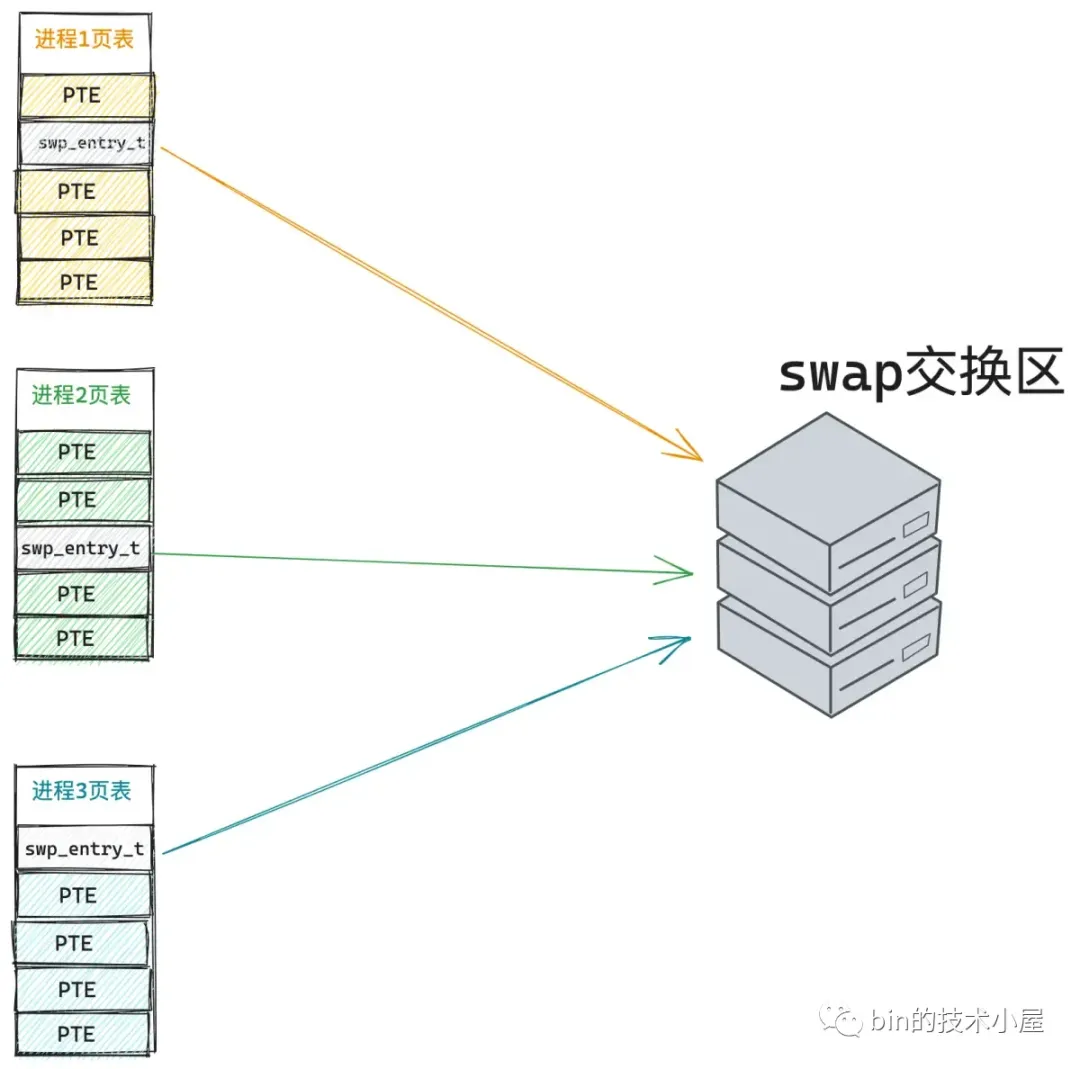
比如下图所示,假设当前系统中存在三个进程,它们共享引用了同一个物理内存页 page。
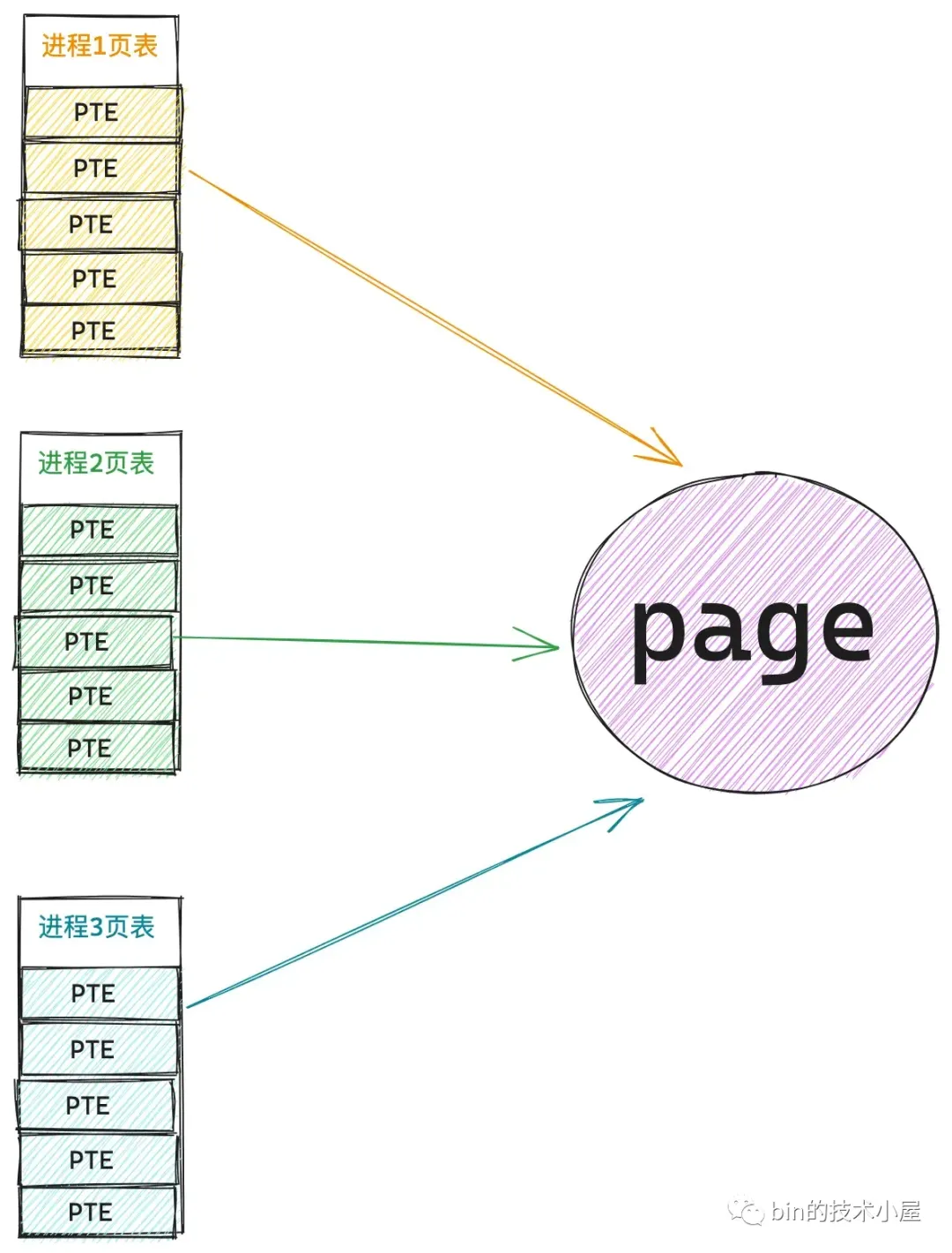
当这个被共享的 page 被内核 swap out 到交换区之后,三个共享进程的页表会发生如下变化:
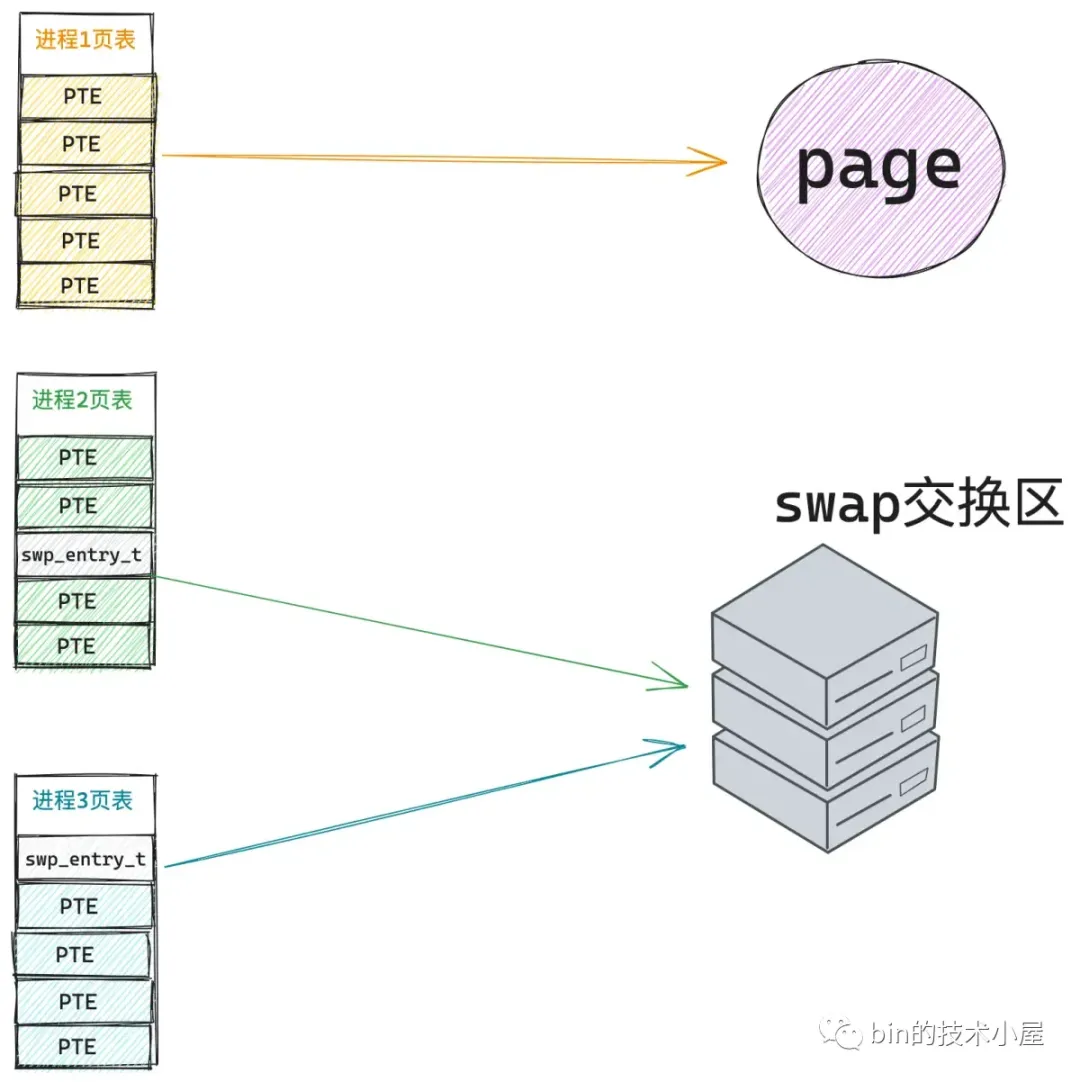
当 进程1 开始读取这个共享 page 的时候,由于 page 已经 swap out 到交换区了,所以会发生 swap 缺页异常,进入内核通过 swap_readpage 将共享 page 的内容从磁盘中读取进内存,此时三个进程的页表结构变为下图所示:
现在共享 page 已经被 进程1 swap in 进来了,但是 进程2 和 进程 3 是不知道的,它们的页表中还储存的是 swp_entry_t,依然指向 page 所在交换区的位置。
按照之前的逻辑,当 进程2 以及 进程3 开始读取这个共享 page 的时候,其实 page 已经在内存了,但是它们此刻感知不到,因为 进程2 和 进程3 的页表中存储的依然是 swp_entry_t,还是会产生 swap 缺页中断,重新通过 swap_readpage 读取交换区中的内容,这样一来就产生了额外重复的磁盘 IO。
除此之外,更加严重的是,由于 进程2 和 进程3 的 swap 缺页,又会产生两个新的内存页用来存放从 swap_readpage 中读取进来的交换区数据。怎么解决这个问题呢?还有一种极端场景是一个进程试图读取一个正在被 swap out 的 page ,由于 page 正在被内核 swap out,此时进程页表指向该 page 的 pte 已经变成了 swp_entry_t。很简单,没有什么问题是加cache解决不了的。
10.3 swap cache
有了 swap cache 之后,情况就会变得大不相同,我们在回过头来看第一个问题 —— 多进程共享内存页。进程1 在 swap in 的时候首先会到 swap cache 中去查找,看看是否有其他进程已经把内存页 swap in 进来了,如果 swap cache 中没有才会调用 swap_readpage 从磁盘中去读取。
当内核通过 swap_readpage 将内存页中的内容从磁盘中读取进内存之后,内核会把这个匿名页先放入 swap cache 中。进程 1 的页表将原来的 swp_entry_t 填充为 pte 并指向 swap cache 中的这个内存页。由于进程1 页表中对应的页表项现在已经从 swp_entry_t 变为 pte 了,指向的是 swap cache 中的内存页而不是 swap 交换区,所以对应 slot 的引用计数就要减 1 。
还记得我们之前介绍的 swap_map 数组吗 ?slot 被进程引用的计数就保存在这里,现在这个 slot 在 swap_map 数组中保存的引用计数从 3 变成了 2 。表示还有两个进程也就是 进程2 和 进程3 仍在继续引用这个 slot 。
当进程2 发生 swap 缺页中断的时候进入内核之后,也是首先会到 swap cache 中查找是否现在已经有其他进程把共享的内存页 swap in 进来了,内存页 page 在 swap cache 的索引就是页表中的 swp_entry_t。由于这三个进程共享的同一个内存页,所以三个进程页表中的 swp_entry_t 都是相同的,都是指向交换区的同一位置。
由于共享内存页现在已经被 进程1 swap in 进来了,并存放在 swap cache 中,所以 进程2 通过 swp_entry_t 一下就在 swap cache 中找到了,同理,进程 2 的页表也会将原来的 swp_entry_t 填充为 pte 并指向 swap cache 中的这个内存页。slot 的引用计数减 1。
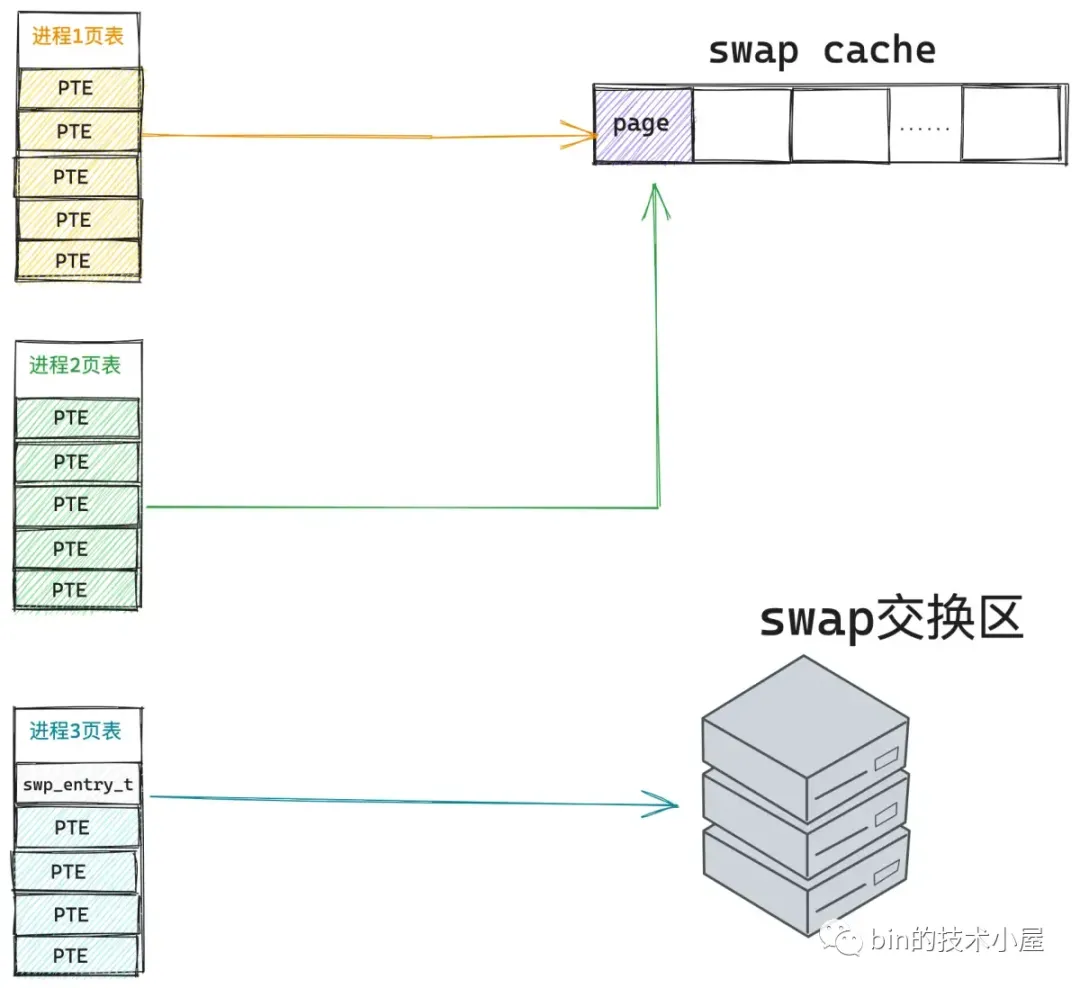
现在这个 slot 在 swap_map 数组中保存的引用计数从 2 变成了 1 。表示只有 进程3 在引用这个 slot 了。
当 进程3 发生 swap 缺页中断的之后,内核还是先通过 swp_entry_t 到 swap cache 中去查找,找到之后,将 进程 3 页表原来的 swp_entry_t 填充为 pte 并指向 swap cache 中的这个内存页,slot 的引用计数减 1。
现在 slot 的引用计数已经变为 0 了,这意味着所有共享该内存页的进程已经全部知道了新内存页的地址,它们的 pte 已经全部指向了新内存页,不在指向 slot 了,此时内核便将这个内存页从 swap cache 中移除。
针对第二个问题 —— 进程试图 swap in 这个正在被内核 swap out 的 page,内核的处理方法也是一样,内核在 swap out 的时候首先会在交换区中为这个 page 分配 slot 确定其在交换区的位置,通过匿名页反向映射机制找到所有引用该内存页的进程,将它们页表中的 pte 修改为指向 slot 的 swp_entry_t。
然后将匿名页 page 先是放入到 swap cache 中,慢慢地通过 swap_writepage 回写。当匿名页被完全回写到交换区中时,内核才会将 page 从 swap cache 中移除。
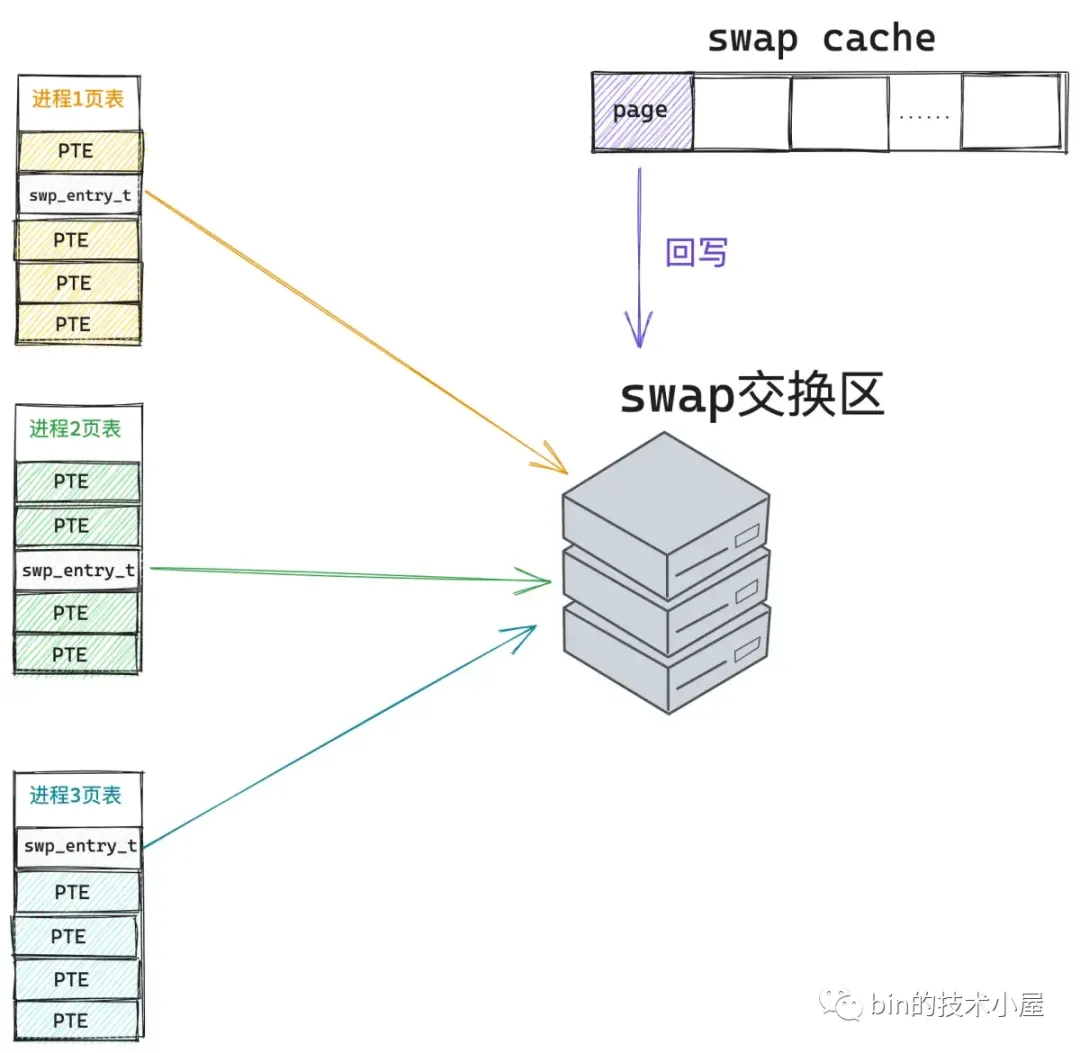
如果当内核正在回写的过程中,不巧有一个进程又要访问该内存页,同样也会发生 swap 缺页中断,但是由于此时没有回写完成,内存页还保存在 swap cache 中,内核通过进程页表中的 swp_entry_t 一下就在 swap cache 中找到了,避免了再次发生磁盘 IO,后面的过程就和第一个问题一样了。
10.4 swap 预读
现在我们已经清楚了当进程虚拟内存空间中的某一段 vma 发生 swap 缺页异常之后,内核的 swap in 核心处理流程。但是整个完整的 swap 流程还没有结束,内核还需要考虑内存访问的空间局部性原理。
当进程访问某一段内存的时候,在不久之后,其附近的内存地址也将被访问。对应于本小节的 swap 场景来说,当进程地址空间中的某一个虚拟内存地址 address 被访问之后,那么其周围的虚拟内存地址在不久之后,也会被进程访问。
而那些相邻的虚拟内存地址,在进程页表中对应的页表项也都是相邻的,当我们处理完了缺页地址 address 的 swap 缺页异常之后,如果其相邻的页表项均是 swp_entry_t,那么这些相邻的 swp_entry_t 所指向交换区的内容也需要被内核预读进内存中。
这样一来,当 address 附近的虚拟内存地址发生 swap 缺页的时候,内核就可以直接从 swap cache 中读到了,避免了磁盘 IO,使得 swap in 可以快速完成,这里和文件的预读机制有点类似。
swap 预读在 Linux 内核中由 swapin_readahead 函数负责,它有两种实现方式:
- 第一种是根据缺页地址 address 周围的虚拟内存地址进行预读,但前提是它们必须属于同一个 vma,这个逻辑在 swap_vma_readahead 函数中完成。
- 第二种是根据内存页在交换区中周围的磁盘地址进行预读,但前提是它们必须属于同一个交换区,这个逻辑在 swap_cluster_readahead 函数中完成。
当要 swap in 的内存页在交换区的位置已经接近末尾了,则需要减少预读页的个数,防止预读超出交换区的边界。如果预读的页表项不是 swp_entry_t,则说明该页表项是一个空的还没有进行过映射或者页表项指向的内存页还在内存中,这种情况下则跳过,继续预读后面的 swp_entry_t。这样一来,经过 swap_vma_readahead 预读之后,缺页内存地址 address 周围的页表项所指向的内存页就全部被加载到 swap cache 中了。当进程下次访问 address 周围的内存地址时,虽然也会发生 swap 缺页异常,但是内核直接从 swap cache 中就可以读取到了,避免了磁盘 IO。
10.5 还原 do_swap_page 完整面貌
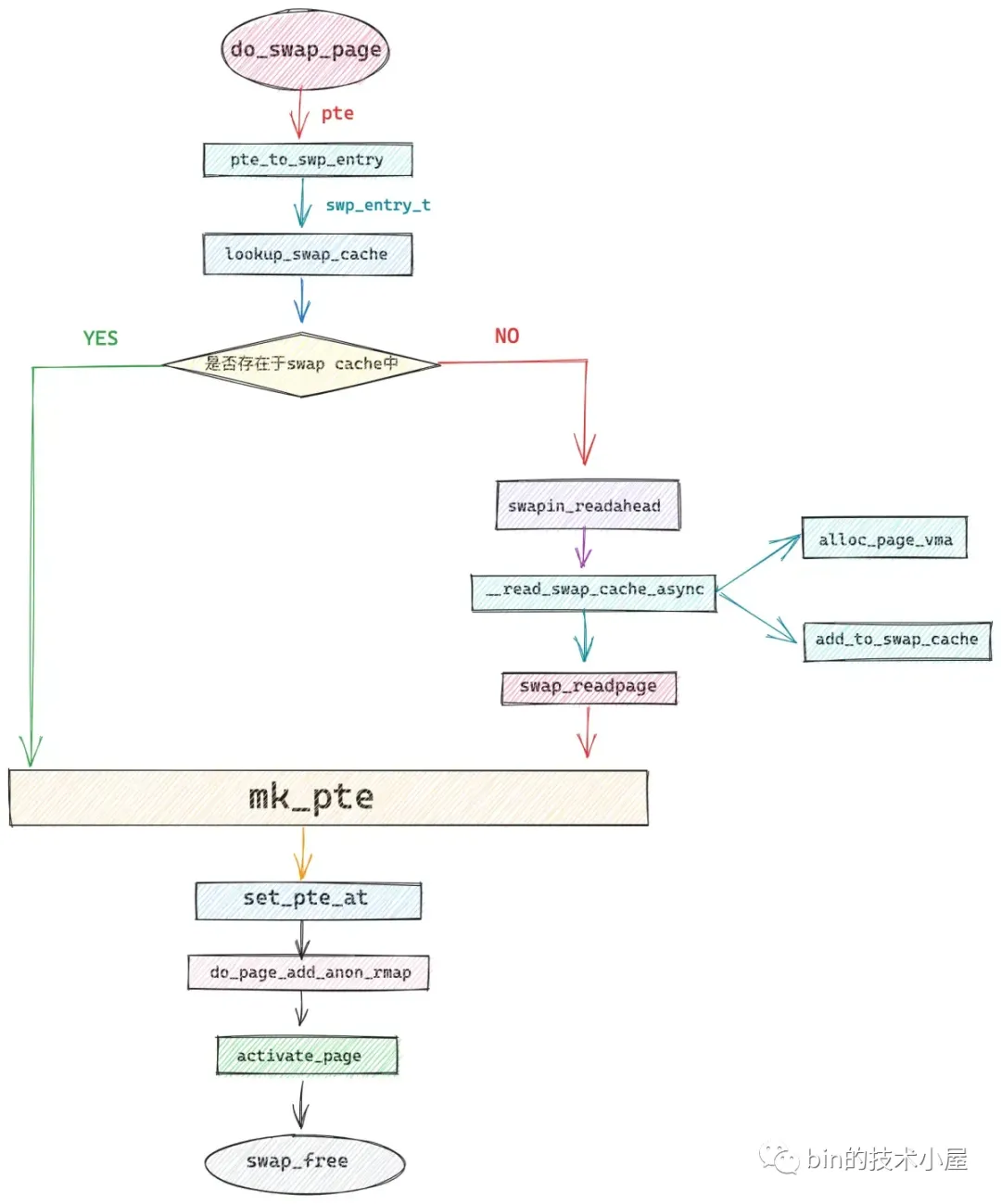
当我们明白了前面介绍的这些背景知识之后,再回过头来看内核完整的 swap in 过程就很清晰了
- 首先内核会通过 pte_to_swp_entry 将进程页表中的 pte 转换为 swp_entry_t
- 通过 lookup_swap_cache 根据 swp_entry_t 到 swap cache 中查找是否已经有其他进程将内存页 swap 进来了。
- 如果 swap cache 没有对应的内存页,则调用 swapin_readahead 启动预读,在这个过程中,内核会重新分配物理内存页,并将这个物理内存页加入到 swap cache 中,随后通过 swap_readpage 将交换区的内容读取到这个内存页中。
- 现在我们需要的内存页已经 swap in 到内存中了,后面的流程就和普通的缺页处理一样了,根据 swap in 进来的内存页地址重新创建初始化一个新的 pte,然后用这个新的 pte,将进程页表中原来的 swp_entry_t 替换掉。
- 为新的内存页建立反向映射关系,加入 lru active list 中,最后 swap_free 释放交换区中的资源。
总结
从 Linux 内核如何通过缺页中断将进程页表从 0 到 1 一步一步的完整构建出来。从进程虚拟内存空间布局的角度来讲,缺页中断主要分为两个方面:
- 内核态缺页异常处理 —— do_kern_addr_fault,这里主要是处理 vmalloc 虚拟内存区域的缺页异常,其中涉及到主内核页表与进程页表内核部分的同步问题。
- 用户态缺页异常处理 —— do_user_addr_fault,其中涉及到的主内容是如何从 0 到 1 一步一步构建完善进程页表体系。
总体上来讲引起缺页中断的原因分为两大类:
- 第一类是缺页虚拟内存地址背后映射的物理内存页不在内存中
- 第二类是缺页虚拟内存地址背后映射的物理内存页在内存中。
第一类缺页中断的原因涉及到三种场景:
- 缺页虚拟内存地址 address 在进程页表中间页目录对应的页目录项 pmd_t 是空的。
- 缺页地址 address 对应的 pmd_t 虽然不是空的,页表也存在,但是 address 对应在页表中的 pte 是空的。
- 虚拟内存地址 address 在进程页表中的页表项 pte 不是空的,但是其背后映射的物理内存页被内核 swap out 到磁盘上了。
第二类缺页中断的原因涉及到两种场景:
- NUMA Balancing。
- 写时复制了(Copy On Write, COW)。
最后我们介绍了内核整个 swap in 的完整过程,其中涉及到的重要内容包括交换区的布局以及在内核中的组织结构,swap cache 与 page cache 之间的区别,swap 预读机制。

