概述
对比赛时miniob官方文档的学习,但由于后面miniob迭代过同时官方文档更新不及时,可能有与实际不匹配的地方,但根本原理上是不变的。
MiniOB框架
为了参加oceanbase数据库的比赛,首先得先学习了解初赛使用的MiniOB,功能模块的设计比较简单,类似于一个toy一样的数据库,好处是可以比较方便的上手和练习。
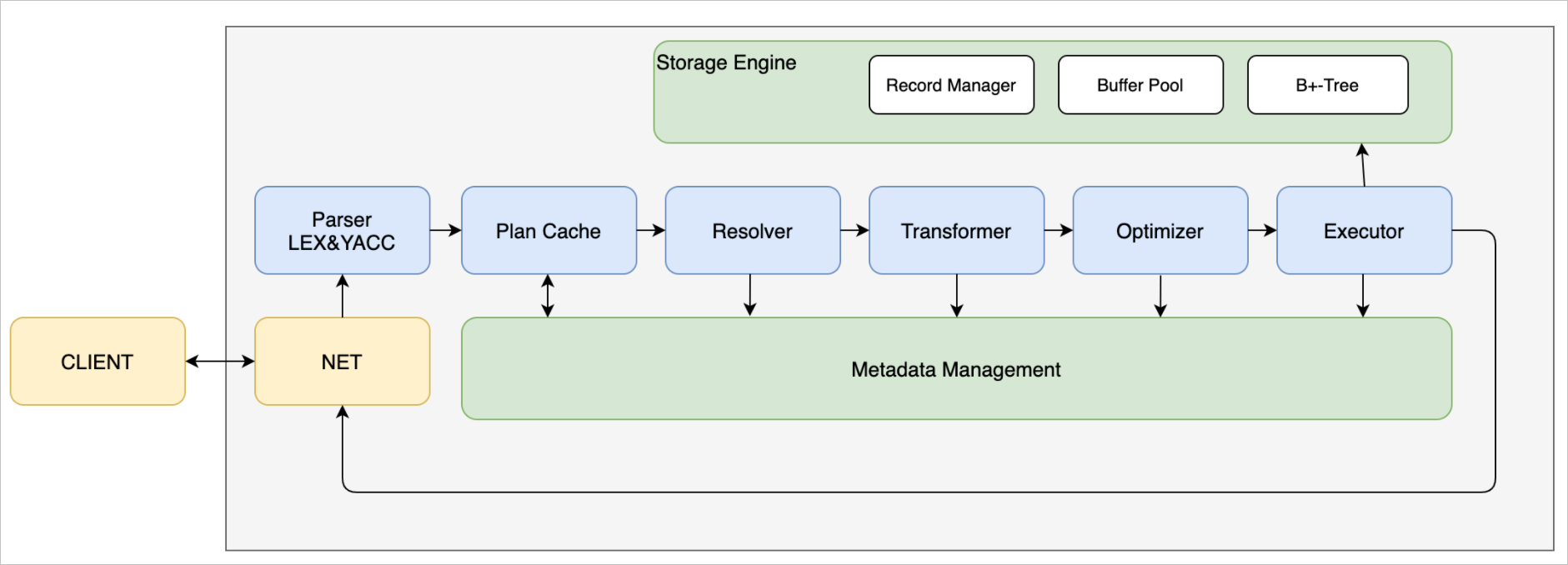
存储引擎控制整个数据、记录是如何在文件和磁盘中存储,以及如何跟内部 SQL 模块之间进行交互。存储引擎中有三个关键模块:
- Record Manager:组织记录一行数据在文件中如何存放。
- Buffer Pool:文件跟内存交互的关键组件。
- B+Tree:索引结构。
如图所示左边是客户端,右边是服务端。客户端发起命令,通过网络通讯和服务端的网络模块去通讯收发命令。服务端的网络模块收到 SQL 请求后,交给词法/语法解析模块(Parser 模块),经过词法解析和语法解析模块将 SQL 请求字符串转换成带有语法结构信息的内存数据结构(语法树),再转发给下一个 Plan Cache,Plan Cache 目前不做特殊处理,直接再转发给 Resolver 模块。
Resolver 模块会将判断模块解析出来的语法树,进一步细化后转换成真实的对象。比如查询一张表,会把表名转换成具体的表对象;如果是查询某个字段,会转换成对应的字段名;如果是 select *,会把 * 转换成对应表的各个字段。除此之外还会做一些预检,比如查询一张不存在的表,就会提前返回错误。
经过 Resolver 阶段,会把处理的结果给到 Transformer 和下一个优化阶段。这两个阶段在部分数据库中,就是优化模块,如 MySQL。虽然图中是两个模块,但不一定按照 Transformer 和 Optimizer 的流程顺序来执行,可能会多次的循环,在保证低成本下选择较优的查询方案。
Transformer 可以理解为根据一些规则去做转换,让后面的优化器能更好地优化。比如在查询表时,查询条件为 where 1=1,永远是真,那就会直接把这个条件删除。
经过这个规则转换后,交给优化模块。优化模块会根据一些条件找到更好的查询路径。比如查询数据,需要先判断直接使用索引查询,速度更快,还是通过全表遍历查询速度更快。因为有时部分因素或条件会导致索引查询更慢,所以优化模块会做一些判断,选择较好的查询计划,再转发给下一个执行模块。
执行模块(Executor)会按照查询计划去执行,访问索引、Buffer Pool、记录管理、以及底层的模块。然后把查询的结果返回给网络模块。网络模块再通过 Socket 返回给客户端。
总结一下,即:
- 网络模块:负责与客户端交互,收发客户端请求与应答;
- SQL解析:将用户输入的SQL语句解析成语法树;
- 执行计划缓存:执行计划缓存模块会将该 SQL第一次生成的执行计划缓存在内存中,后续的执行可以反复执行这个计划,避免了重复查询优化的过程(未实现)。
- 语义解析模块:将生成的语法树,转换成数据库内部数据结构(部分实现);
- 查询缓存:将执行的查询结果缓存在内存中,下次查询时,可以直接返回(未实现);
- 查询优化:根据一定规则和统计数据,调整/重写语法树。当前实现为空,留作实验题目;
- 计划执行:根据语法树描述,执行并生成结果;
- 会话管理:管理用户连接、调整某个连接的参数;
- 元数据管理:记录当前的数据库、表、字段和索引元数据信息;
- 客户端:作为测试工具,接收用户请求,向服务端发起请求。
各模块工作原理介绍
seda异步事件框架
miniob使用了seda框架,在介绍其它模块之前有必要先了解一下seda。 SEDA全称是:stage event driver architecture,它旨在结合事件驱动和多线程模式两者的优点,从而做到易扩展,解耦合,高并发。 各个stage之间的通信由event来传递,event的处理由stage的线程池异步处理。线程池内部会维护一个事件队列。 在miniob中,从接收请求开始,到SQL解析、查询优化、计划执行都使用event来传递数据,并且可以通过seda来配置线程池的个数。
服务端启动过程
虽然代码是模块化的,并且面向对象设计思想如此流行,但是很多同学还是喜欢从main函数看起。那么就先介绍一下服务端的启动流程。
main函数参考 main@src/observer/main.cpp。启动流程大致如下:
- 解析命令行参数
parse_parameter@src/observer/main.cpp - 加载配置文件
Ini::load@deps/common/conf/ini.cpp - 初始化日志
init_log@src/observer/init.cpp - 初始化seda
init_seda@src/observer/init.cpp - 初始化网络服务
init_server@src/observer/main.cpp - 启动网络服务
Server::serve@src/net/server.cpp
建议把精力更多的留在核心模块上,以更快的了解数据库的工作。
网络模块
网络模块代码参考src/observer/net,主要是Server类。 在这里,采用了libevent作为网络IO工具。libevent的工作原理可以参考libevent官方网站。 网络服务启动时,会监听端口,接受到新的连接,会将新的连接描述字加入到libevent中。在有网络事件到达时(一般期望是新的消息到达),libevent会调用我们注册的回调函数(参考Server::recv@src/observer/net/server.cpp)。当连接接收到新的消息时,我们会创建一个SessionEvent(参考seda中的事件概念),然后交由seda调度。
SQL解析
SQL解析模块是接收到用户请求,开始正式处理的第一步。它将用户输入的数据转换成内部数据结构,一个语法树。 解析模块的代码在src/observer/sql/parser下,其中lex_sql.l是词法解析代码,yacc_sql.y是语法解析代码,parse_defs.h中包含了语法树中各个数据结构。 对于词法解析和语法解析,原理概念可以参考《编译原理》。 其中词法解析会把输入(这里比如用户输入的SQL语句)解析成成一个个的“词”,称为token。解析的规则由自己定义,比如关键字SELECT,或者使用正则表达式,比如"[A-Za-z_]+[A-Za-z0-9_]*" 表示一个合法的标识符。 对于语法分析,它根据词法分析的结果(一个个token),按照编写的规则,解析成“有意义”的“话”,并根据这些参数生成自己的内部数据结构。比如SELECT * FROM T,可以据此生成一个简单的查询语法树,并且知道查询的columns是”*”,查询的relation是”T”。 NOTE:在查询相关的地方,都是用关键字relation、attribute,而在元数据中,使用table、field与之对应。
计划执行
在miniob的实现中,SQL解析之后,就直接跳到了计划执行,中间略去了很多重要的阶段,但是不影响最终结果。 计划执行的代码在src/observer/sql/executor/下,主要参考execute_stage.cpp的实现。
seda编程注意事项
seda使用异步事件的方式,在线程池中调度。每个事件(event),再每个阶段完成处理后,都必须调用done接口。比如
event->done(); // seda异步调用event的善后处理event->done_immediate(); // seda将直接在当前线程做event的删除处理event->done_timeout(); // 一般不使用
当前Miniob为了方便和简化,都执行event->done_immediate。
在event完成之后,seda会调用event的回调函数。通过 event->push_callback 放置回调函数,在event完成后,会按照push_callback的反向顺序调用回调函数。 注意,如果执行某条命令后,长时间没有返回结果,通过pstack也无法找到执行那条命令的栈信息,就需要检查下,是否有event没有调用done操作。 当前的几种event流程介绍:
recv@server.cpp接收到用户请求时创建SessionEvent并交给SessionStageSessionStage处理SessionEvent并创建SQLStageEvent,流转->ParseStage处理SQLStageEvent流转到->ResolveStage流转SQLStageEvent->QueryCacheStage流转SQLStageEvent->PlanCacheStage流转SQLStageEvent->OptimizeStage流转ExecutionPlanEvent->ExecuteStage处理ExecutionPlanEvent并创建StorageEvent,流转到->DefaultStorageStage处理StorageEvent
元数据管理模块
元数据是指数据库一些核心概念,包括db、table、field、index等,记录它们的信息。比如db,记录db文件所属目录;field,记录字段的类型、长度、偏移量等。代码文件分散于src/observer/storage/table,field,index中,文件名中包含meta关键字。
客户端
这里的客户端提供了一种测试miniob的方法。从标准输入接收用户输入,将请求发给服务端,并展示返回结果。这里简化了输入的处理,用户输入一行,就认为是一个命令。
通信协议
miniob采用TCP通信,纯文本模式,使用’\0’作为每个消息的终结符。 注意:测试程序也使用这种方法,_请不要修改协议,后台测试程序依赖这个协议_。 注意:返回的普通数据结果中不要包含’\0’,也不支持转义处理。
当前MiniOB已经支持了MySQL协议,具体请参考MiniOB 通讯协议简介。
初始化仓库
官方教程提供了非常详细的流程,跟着设置好Gitee提测流程即可,这里官方额外提供了日常使用的git命令来方便使用,可以学习使用。
查看当前分支
git branch # 查看本地分支 git branch -a # 查看所有分支,包括远程分支创建分支
git checkout -b 'your branch name' git branch -d 'your branch name' # 删除一个分支切换分支
git checkout 'branch name'提交代码
# 添加想要提交的文件或文件夹 git add 'the files or directories you want to commit' # 这一步也可以用 git add . 添加当前目录 # 提交到本地仓库 # -m 中是提交代码的消息,建议写有意义的信息,方便后面查找 git commit -m 'commit message'推送代码到远程仓库
git push # 可以将多次提交,一次性 push 到远程仓库合并代码
# 假设当前处于分支 develop 下 git merge feature/update # 会将 feature/update 分支的修改,merge 到 develop 分支临时修改另一个分支的代码
# 有时候,正在开发一个新功能时,突然来了一个紧急 BUG,这时候需要切换到另一个分 去开发 # 这时可以先把当前的代码提交上去,然后切换分支。 # 或者也可以这样: git stash # 将当前的修改保存起来 git checkout main # 切换到主分支,或者修复 BUG 的分支 git checkout -b fix/xxx # 创建一个新分支,用于修复问题 # 修改完成后,merge 到 main 分支 # 然后,继续我们的功能开发 git checkout feature/update # 假设我们最开始就是在这个分支上 git stash pop # stash 还有很多好玩的功能,大家可以探索一下
构建官方MiniOB
下载源码
git clone https://github.com/oceanbase/miniob.git环境初始化
如果是第一次在这个环境上编译 MiniOB,需要执行如下命令安装 MiniOB 的依赖库。
git clone https://github.com/oceanbase/miniob.git命令执行后,脚本会自动拉取依赖库,并编译安装到系统目录。
- 编译
执行如下命令将编译 debug 版本的 MiniOB。
bash build.sh执行如下命令将编译 release 版本的 MiniOB。
bash build.sh release详细使用方法可执行 bash build.sh -h 查看帮助信息。
MiniOB运行
编译完成后,可在 build 目录(build_debug 或 build_release)下找到 bin/observer 目录,这是 MiniOB 的服务端进程,bin/obclient 是自带的客户端进程,当前服务端程序启动已经支持了多种模式,可以以 TCP、unix socket 方式启动,这时需要启动客户端以发起命令。observer 还支持直接执行命令的模式,这时不需要启动客户端,直接在命令行输入命令即可。observer 提供的参数可通过 ./bin/observer -h 命令查看帮助。
以直接执行命令启动服务端进程
可执行如下命令以直接执行命令的方式启动服务端程序,这种情况下可以直接输入命令,不需要启动客户端,所有请求都会以单线程的方式运行,配置项中的线程数不再有实际意义。
./bin/observer -f ../etc/observer.ini -P cli以监听 TCP 端口方式启动
可执行如下命令以监听端口的方式启动服务端程序,此处以 6789 端口为例。
./bin/observer -f ../etc/observer.ini -p 6789这种情况下需执行如下命令启动客户端程序,启动后客户端会连接到服务端的 6789 端口。
./bin/obclient -p 6789以监听 unix socket 方式启动
可执行如下命令以监听 unix socket 的方式启动服务端程序。
./bin/observer -f ../etc/observer.ini -s miniob.sock这种情况下需执行如下命令启动客户端程序,启动后客户端会连接到服务端的 miniob.sock 文件。
./bin/obclient -s miniob.sock并发模式
默认情况下,编译后的程序不支持并发操作,如若需要支持并发,需要在编译时增加 -DCONCURRENCY=ON 选项,示例如下。
cmake -DCONCURRENCY=ON ..或执行如下命令,在vscode中需要再.vscode中修改tasks.json,在build_debug或者其他阶段添加command如下:
bash build.sh -DCONCURRENCY=ON之后使用上述命令启动服务端进程,即可支持并发操作。
常见问题
问题现象:在启动服务端进程时出现报错找不到链接库 A。
可能原因:安装依赖时,默认安装在 /usr/local/ 目录下,而环境变量中没有将目录包含到动态链接库查找路径。
解决方法:
您可将如下命令添加到 HOME 目录的 .bashrc 中,之后执行 source ~/.bashrc 命令加载环境变量后重新启动程序。
export LD_LIBRARY_PATH=/usr/local/lib64:$LD_LIBRARY_PATHLD_LIBRARY_PATH 是 Linux 环境中运行时查找动态链接库的路径,路径之间以冒号(:)分隔。将数据写入 bashrc 或其它文件中,下次启动程序时会自动加载,而不需要再次执行 source 命令加载。
**注意**:如果终端脚本使用的不是 bash,而是 zsh,那么就需要修改 `.zshrc`。MiniOB调试
MiniOB 的关键数据结构
parse_def.h:
struct Selects; //查询相关
struct CreateTable; //建表相关
struct DropTable; //删表相关
enum SqlCommandFlag; //SQL 语句对应的 command 枚举
union Queries; //各类 DML 和 DDL 操作的联合
table.h
class Table;
db.h
class Db;MiniOB 的关键接口
RC parse(const char *st, Query *sqln); //sql parse 入口
ExecuteStage::handle_request
ExecuteStage::do_select
DefaultStorageStage::handle_event
DefaultHandler::create_index
DefaultHandler::insert_record
DefaultHandler::delete_record
DefaultHandler::update_record
Db::create_table
Db::find_table
Table::create
Table::scan_record
Table::insert_record
Table::update_record
Table::delete_record
Table::scan_record
Table::create_index打印日志调试
MiniOB 提供的日志接口:
deps/common/log/log.h:
#define LOG_PANIC(fmt, ...)
#define LOG_ERROR(fmt, ...)
#define LOG_WARN(fmt, ...)
#define LOG_INFO(fmt, ...)
#define LOG_DEBUG(fmt, ...)
#define LOG_TRACE(fmt, ...)日志相关配置项 observer.ini:
LOG_FILE_NAME = observer.log
# LOG_LEVEL_PANIC = 0,
# LOG_LEVEL_ERR = 1,
# LOG_LEVEL_WARN = 2,
# LOG_LEVEL_INFO = 3,
# LOG_LEVEL_DEBUG = 4,
# LOG_LEVEL_TRACE = 5,
# LOG_LEVEL_LAST
LOG_FILE_LEVEL=5
LOG_CONSOLE_LEVEL=1工具
为了帮助定位与调试问题,写了一个简单的日志解析工具,可以在miniob编译后找到二进制文件clog_reader,使用方法如下:
clog_reader miniob/db/sys/
补充内容
- ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging 该论文提出了ARIES算法,这是一种基于日志记录的恢复算法,支持细粒度锁和部分回滚,可以在数据库崩溃时恢复事务。如果想要对steal/no-force的概念有比较详细的了解,可以直接阅读该论文相关部分。
- Shadow paging 除了日志做恢复,Shadow paging 是另外一种做恢复的方法。
- Aether: A Scalable Approach to Logging 介绍可扩展日志系统的。
- InnoDB之REDO LOG 非常详细而且深入的介绍了一下InnoDB的redo日志。
- B+树恢复 介绍如何恢复B+树。
- CMU 15445 Logging
MiniOB线程模型
SEDA框架
Resolver、优化器等处理阶段在 SEDA 中都是一个个的 Stage,各个 Stage 之间通过事件来传递数据。MiniOB 的多线程能力是基于 SEDA 来做的,SEDA 本身就是支持线程池的。
下图所示是一个简单的 SEDA 框架图,能够很好的帮助理解 MiniOB 中的每个 Stage 和 event,以及线程池之间的关系。线程池可以有多个,每个线程池可以包含多个 Stage,一个 Stage 会绑定到某一个线程池里面。每个线程池可以设置自己的线程的个数、事件队列的大小,线程池中的多个 Stage 之间是通过事件通讯的。虽然示例图中写的都是 StageEvent,但也可以是不同的名字。另外,不同的线程池之间的 Stage 也可以通过事件通讯,并且每一个线程池里面的 Stage 可以是不同的。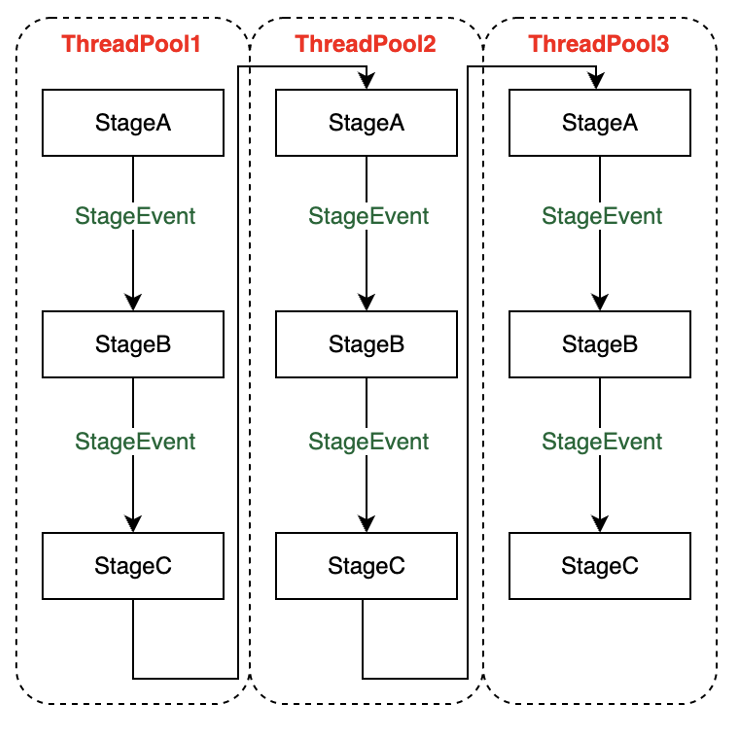
SEDA 框架有一个好处是可以将 Stage 进行分类,比如把处理 SQL 的分作一类,把 IO 处理的分作为一类,并把不同的分类分配到不同的线程池。这样在处理任务时不容易受到其他干扰,并且也能够根据真实的业务场景去调整每个线程池的大小。
接下来看一个简单的 Stage 模型。一个 Stage 对应一个类型的事件,事件是放在线程池事件队列中的。线程池事件指当事件队列有事件后,就将其交给对应的 Stage 来处理。

事件的生命周期]
创建 event 的时候,它就会被加到一个线程事件队列里面(参考 net/server.cpp 中 session_stage_->add_event(sev);)。添加到事件队列里面之后,就会由 Stage 调用 handle_event 去处理(参考 session/session_stage.cpp 中 SessionStage::handle_event)。处理完成之后,event 就结束了。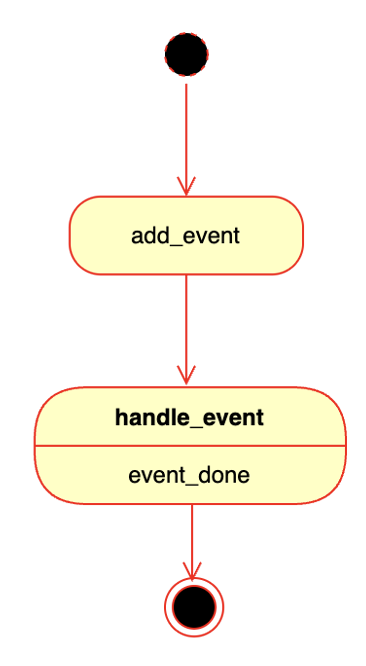
事件在处理的时候,还可以增加一些回调函数(比如 session/session_stage.cpp 中的 sev->push_callback(cb);),后续将事件交给其它的 Stage 做处理,处理完成后就会调用回调函数。也可以在回调函数中做一些任务处理,在代码里可以看到很多,比如 done_immediate 就是立即处理完成(比如 parser/parse_stage.cpp 中的 event->done_immediate())。
事件执行过程
客户端通过网络发送一个请求到服务端,服务端在接收到消息后会创建一个消息包,并创建对应的 SessionEvent。然后调用 add_event 把 SessionEvent 添加到 SessionStage 里(参考 net/server.cpp 中 session_stage_->add_event(sev);),再放到对应的事件队列中。SessionStage 以及后续处理事件的几个 Stage,都在 SQLThreads 线程池中。
SessionStage 处理 SessionEvent 后,会创建一个 SQLStageEvent 传递给后面的 Stage。后续的 Stage 都是处理这个 SQLStageEvent 的事件。如下图所示,事件经过一个流转,处理完成后返回结果给客户端。

MiniOB 代码中的 SEDA 框架、线程池以及各个 Stage代码解读,在配置文件 etc/observer.ini 中可以很清晰的看到 MiniOB 有哪些线程池(SQL、IO 和 Default)以及 Stage。每个 Stage 可以配置自己位于哪个线程池、关联的下一个 Stage 以及所属线程池,如果不配置,则使用默认的线程池。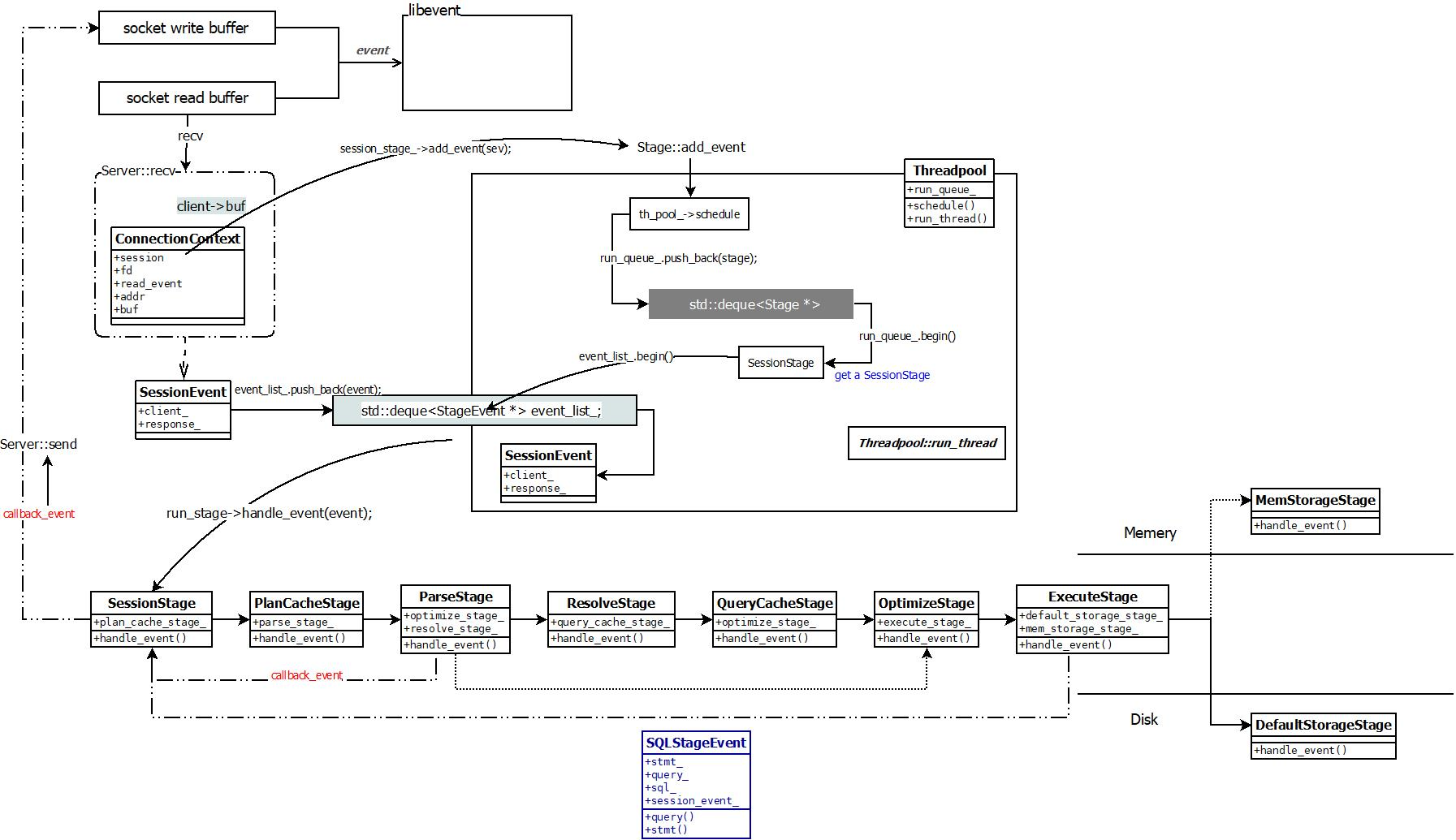
MiniOB存储实现
首先介绍 MiniOB 中文件是怎么存放,文件需要管理一些基础对象,如数据结构、表、索引。数据库在 MiniOB 这里体现就是一个文件夹,如下图所示,最上面就是一个目录,MiniOB 启动后会默认创建一个 sys 数据库,所有的操作都默认在 sys 中。
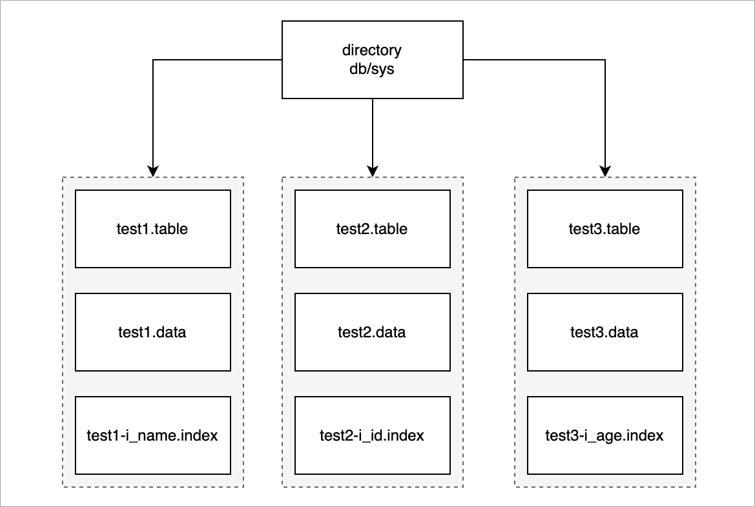
一个数据库下会有多张表。上图示例中只有三张表,接下来以 test1 表为例介绍一下表里都存放什么内容。
- test1.table:元数据文件,这里面存放了一些元数据。如:表名、数据的索引、字段类型、类型长度等。
- test1.data:数据文件,真正记录存放的文件。
- test1-i_name.index:索引文件,索引文件有很多个,这里只展示一个示例。
记录修改
对于记录的修改,一般就存在三种,插入更新以及删除:
数据插入
数据插入在存储中的流程可以简单概括为以下几步:
- 找到空闲块。
- 把记录插入块的空闲位置。
- 维护新插入记录的偏移。
如下图所示,先从未使用的空间中找到可以插入的位置,写入记录后,再把记录相对于块的偏移写入到偏移表中进行维护。

数据删除
数据删除一般在数据库中的实现,并非把实际的数据内容马上从存储介质中擦除,而是在需要删除的记录中打上一个删除的标记,例如删除了记录 1,则把记录 1 前面的一个字节或一个 bit 标记为 delete,然后数据库系统再根据具体的场景(如 GC 流程),再统一回收这部分的空间。

数据修改
记录的修改主要有两种场景:
定长记录的修改
定长记录的修改,因为记录定长,因此可以使用覆盖写的方式进行修改,把修改后的数据在原地址中覆盖写入。变长记录的修改
变长记录的修改,因为修改后数据的长度可能会发生变更,所以不能使用覆盖写这种方式。而是会在块中重新查找空闲的位置,把修改的记录写入到新位置中,最后对原记录打上删除的标记,避免旧数据被访问。
MiniOB Buffer Pool
Buffer Pool 在传统数据库里是非常重要的基础组件,数据库的数据是存放在磁盘里的,但不能直接从磁盘中读取数据,而是需要先把磁盘的数据读取到内存中,再在 CPU 做一些运算之后,展示给前端用户。写入也是一样的,一般都会先写入到内存,再把内存中的数据写入到磁盘。这种做法也是一个很常见的缓存机制。
接着来看 Buffer Pool 在 MiniOB 中是如何组织的。如上图所示,左边是内存,把内存拆分成不同的帧(frame)。假如内存中有四个 frame,对应了右边的多个文件,每个文件按照每页来划分,每个页的大小都是固定的,每个页读取时是以页为单位跟内存中的一个 frame 相对应。
Buffer Pool 在 MiniOB 里面组织的时候,一个 DiskBufferPool 对象对应一个物理文件。所有的 DiskBufferPool 都使用一个内存页帧管理组件 BPFrameManager,他是公用的。
再来看下读取文件时,怎么跟内存去做交互的。如上图所示,frame1 关联了磁盘中一个文件的页面,frame2 关联了另一个页面,frame3 是空闲页面,没有关联任何磁盘文件,frame4 也关联了一个页面。
比如现在要去读取 file3 的 Page3 页面,首先需要从 BPFrameManager 里面去找一个空闲的 frame,很明显,就是 frame3,然后再把 frame3 跟它关联起来,把 Page3 的数据读取到 frame3 里。现在内存中的所有 frame 都对应了物理页面。
如果再去读取一个页面,如 Page5,这时候已经找不到内存了,通常有两种情况:
- 内存还有空闲空间,可以再申请一个 frame,跟 Page5 关联起来。
- 内存没有空闲空间,还要再去读 Page4,已经没有办法去申请新的内存了。此时就需要从现有的 frame 中淘汰一个页面,比如把 frame1 淘汰掉了,然后把 frame1 跟 Page4 关联起来,再把 Page4 的数据读取到 frame1 里面。淘汰机制也是有一些淘汰条件和算法的,可以先做简单的了解,暂时先不深入讨论细节。
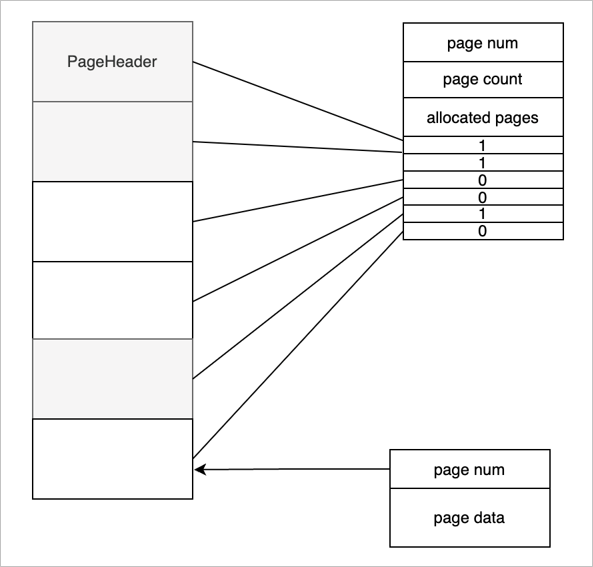
再来看一下,一个物理的文件上面都有哪些组织结构,如上图所示。
- 文件上的第一页称为页头或文件头。文件头是一个特殊的页面,这个页面上会存放一个页号,这个页号肯定都是零号页,即 page num 是 0。
- page count 表示当前的文件一共有多少个页面。
- allocated pages 表示已经分配了多少个页面。如图所示标灰的是已经分配的三个页面。
- Bitmap 表示每一个 bit 位当前对应的页面的分配状态,1 已分配页面,0 空闲页面。
当前这一种组织结构是有一个缺陷的,整个文件能够支持的页面的个数受页面大小的限制,也就是说能够申请的页面的个数受页面大小的限制的。
接下来介绍一下普通页面(除 PageHeader 外),普通页面对 Buffer Pool 来说,第一个字段是用四字节的 int 来表示,就是 page num。接下来是数据,这个数据是由使用 Buffer Pool 的一些模块去控制。比如 Record Manage 或 B+Tree,他们会定义自己的结构,但第一个字段都是 page num,业务模块使用都是 page data 去做组织。
MiniOB 记录管理
记录管理模块(Record Manager)主要负责组织记录在磁盘上的存放,以及处理记录的新增与删除。需要尽可能高效的利用磁盘空间,尽量减少空洞,支持高效的查找和新增操作。
MiniOB 的 Record Manager 做了简化,有一些假设,记录通常都是比较短的,加上页表头,不会超出一个页面的大小。另外记录都是固定长度的,这个简化让学习 MiniOB 变得更简单一点。

上面的图片展示了 MiniOB 的 Record Manager 是怎么实现的,以及 Record 在文件中是如何组织的。
Record Manage 是在 Buffer Pool 的基础上实现的,比如 page0 是 Buffer Pool 里面使用的元数据,Record Manage 利用了其他的一些页面。每个页面有一个头信息 Page Header,一个 Bitmap,Bitmap 为 0 表示最近的记录是不是已经有有效数据;1 表示有有效数据。Page Header 中记录了当前页面一共有多少记录、最多可以容纳多少记录、每个记录的实际长度与对齐后的长度等信息。
MiniOB B+Tree实现
MiniOB中的B+Tree和其他B+Tree是一致的,查询和插入都是从根逐层定位到叶子节点,再从叶结点内获取或者插入。如果插入过程发生叶节点满则进行分裂并向上递归。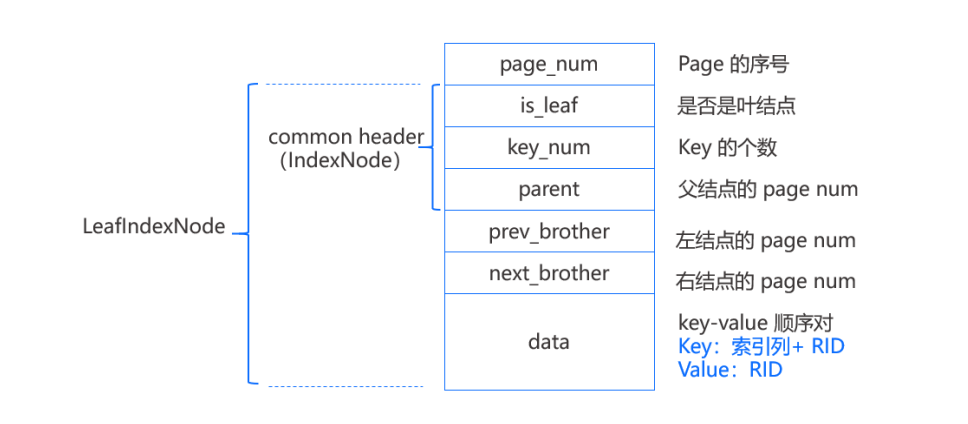
如上图,每个结点组织丞一个固定大小的page,其中page_num表示page在文件中的序号,每个结点page都有一个头,具体实现为IndexNode结构,其中当parent=-1时说明结点没有父节点为根节点。
除此之外,Leaf page还有左结点和右节点的page_num,用来最后遍历查询时使用,除此之外剩余的部分用来顺序存储键值对,叶节点所存放的key是索引列的值加上RID(该行数据在磁盘上的位置),value则是RID。也就是说键值数据存放在叶结点上,和B+Tree中叶结点的值是指向记录的指针不同,即类似Innode一样是类似聚集索引。
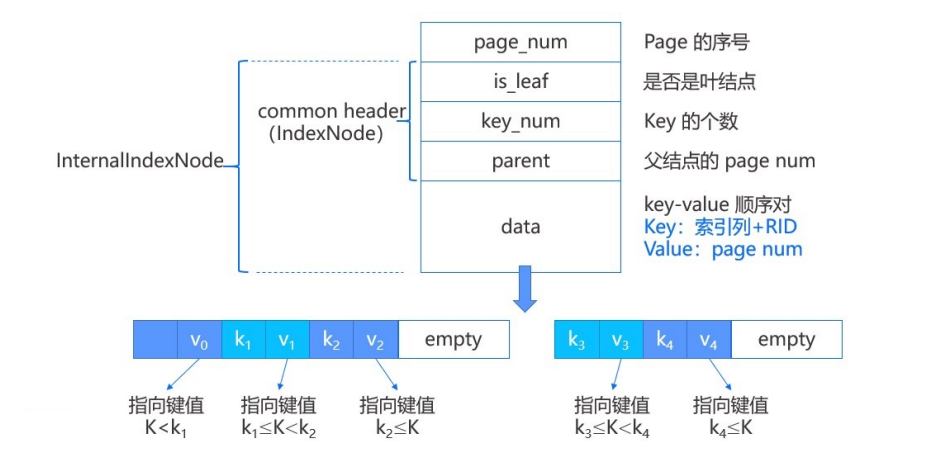
内部结点和叶结点相比,内部结点不存在左右结点的page num,其次是data中存放的value是page num,标识了子结点的page位置。键值对在内部结点的表示中,第一个键值对中的key是无效的,只有k1和k2用于比较。

所有的结点(即page)都存储在外存中的索引文件IndexFile中,其中文件的第一个page是索引文件头,存储了索引相关的元数据。
对于MiniOB来说,其B+树的实现进行了简化,具体可以看官方教程中的第三章。
MiniOB 并发B+Tree实现
Crabing Protocol
在操作B+树时加对应的读写锁是一种最简单粗暴但是有效的方法,只是这样实现效率不高。于是就有一些研究创建了更高效的并发协议,并且会在协议设计上防止死锁的发生。
B+树是一个树状的结构,并且所有的数据都是在叶子节点上,每次操作,几乎都是从根节点开始向下遍历,直到找到对应的叶子节点。然后在叶子节点执行相关操作,如果对上层节点会产生影响,必须需要重新平衡,那就反方向回溯调整节点。 Crabing协议是从根节点开始加锁,找到对应的子节点,就加上子节点的锁。一直循环到叶子节点。在拿到某个子节点锁时,如果当前节点是“安全的”,那就可以释放上级节点的锁。
什么是“安全的” 如果在操作某个节点时,可以确定这个节点上的动作,不会影响到它的父节点,那就说是“安全的”。 B+树上节点的操作有三个:插入、删除和查询。
- 插入:一次仅插入一个数据。如果插入一个数据后,这个节点不需要分裂,就是当前节点元素个数再增加一个,也不会达到一个节点允许容纳的最大个数,那就是安全的。不会分裂就不会影响到父节点。
- 删除:一次仅删除一个数据。如果删除一个数据后,这个节点不需要与其它节点合并,就是当前节点元素个数删除一个后,也不会达到节点允许容纳的最小值,那就是安全的。不需要合并就不会影响到父节点。
- 查询:读取数据对节点来说永远是安全的。
B+树的操作除了上述的插入、删除和查询,还有一个扫描操作。比如遍历所有的数据,通常是从根节点,找到最左边的叶子节点,然后从向右依次访问各个叶子节点。此时与加锁的顺序,与之前描述的几种方式是不同的,那为了防止死锁,就需要对遍历做特殊处理。一种简单的方法是,在访问某个叶子节点时,尝试对叶子节点加锁,如果判断需要等待,那就退出本次遍历扫描操作,重新来一遍。当然这种方法很低效,Concurrency of Operations on B-Trees可以了解更高效的扫描加锁方案。
B+树与Buffer Pool
在MiniOB中,Buffer Pool的实现是 class DiskBufferPool。对Buffer Pool实现不太了解也没关系,这里接单介绍一下。
DiskBufferPool 将一个磁盘文件按照页来划分(假设一页是8K,但是不一定),每次从磁盘中读取文件或者将数据写入到文件,都是以页为单位的。在将文件某个页面加载到内存中时,需要申请一块内存。内存通常会比磁盘要小很多,就需要引入内存管理。在这里引入Frame(页帧)的概念(参考 class Frame),每个Frame关联一个页面。FrameManager负责分配、释放Frame,并且在没有足够Frame的情况下,淘汰掉一些Frame,然后将这些Frame关联到新的磁盘页面。
那如何知道某个Frame关联的页面是否可以释放,然后可以与其它页面关联? 如果这个Frame没有任何人使用,就可以重新关联到其它页面。这里使用的方法是引用计数,称为 pin_count。每次获取某个Frame时,pin_count就加1,操作完释放时,pin_count减1。如果pin_count是0,就可以将页面数据刷新到磁盘(如果需要的话),然后将Frame与磁盘文件的其它数据块关联起来。
为了支持并发操作,Frame引入了读写锁。操作B+树时,就需要加对应的读写锁。
B+ 树的数据保存在磁盘,其树节点,包括内部节点和叶子节点,都对应一个页面。当对某个节点操作时,需要申请相应的Frame,pin_count加1,然后加读锁/写锁。由于访问子节点时,父节点的锁可能可以释放,也可能不能释放,那么需要记录下某个某个操作在整个过程中,加了哪些锁,对哪些frame 做了pin操作,以便在合适的时机,能够释放掉所有相关的资源,防止资源泄露。这里引入class LatchMemo 记录当前访问过的页面,加过的锁。
问题:为什么一定要先执行解锁,再执行unpin(frame引用计数减1)?
如果子节点调用UnlockAncestors()来释放祖先节点上的锁,注意这里是先解锁再Unpin(),如果先Unpin()可能导致在解锁之前页被换出,这时候解锁的是别人的页了:
处理流程
B+树相关的操作一共有4个:插入、删除、查找和遍历/扫描。这里对每个操作的流程都做一个汇总说明,希望能帮助大家了解大致的流程。
插入操作 除了查询和扫描操作需要加读锁,其它操作都是写锁。
- leaf_node = find_leaf // 查找叶子节点是所有操作的基本动作
memo.init // memo <=> LatchMemo,记录加过的锁、访问过的页面
lock root page
- node = crabing_protocal_fetch_page(root_page)
loop: while node is not leaf // 循环查找,直到找到叶子节点
child_page = get_child(node)
- node = crabing_protocal_fetch_page(child_page)
frame = get_page(child_page, memo)
lock_write(memo, frame)
node = get_node(frame)
// 如果当前节点是安全的,就释放掉所有父节点和祖先节点的锁、pin_count
release_parent(memo) if is_safe(node)
- insert_entry_into_leaf(leaf_node)
- split if node.size == node.max_size
- loop: insert_entry_into_parent // 如果执行过分裂,那么父节点也会受到影响
- memo.release_all // LatchMemo 帮我们做资源释放删除操作 与插入一样,需要对操作的节点加写锁。
- leaf_node = find_leaf // 查找的逻辑与插入中的相同
- leaf_node.remove_entry
- node = leaf_node
- loop: coalesce_or_redistribute(node) if node.size < node.min_size and node is not root
neighbor_node = get_neighbor(node)
// 两个节点间的数据重新分配一下
redistribute(node, neighbor_node) if node.size + neighbor_node.size > node.max_size
// 合并两个节点
coalesce(node, neighbor_node) if node.size + neighbor_node.size <= node.max_size
memo.release_all查找操作 查找是只读的,所以只加读锁
- leaf_node = find_leaf // 与插入的查找叶子节点逻辑相同。不过对所有节点的操作都是安全的
- return leaf_node.find(entry)
- memo.release_all扫描/遍历操作
- leaf_node = find_left_node
loop: node != nullptr
scan node
node_right = node->right // 遍历直接从最左边的叶子节点,一直遍历到最右边
return LOCK_WAIT if node_right.try_read_lock // 不直接加锁,而是尝试加锁,一旦失败就返回
node = node_right
memo.release_last // 释放当前节点之前加到的锁
根节点处理
前面描述的几个操作,没有特殊考虑根节点。根节点与其它节点相比有一些特殊的地方:
- B+树有一个单独的数据记录根节点的页面ID,如果根节点发生变更,这个数据也要随着变更。这个数据不是被Frame的锁保护的;
- 根节点具有一定的特殊性,它是否“安全”,就是根节点是否需要变更,与普通节点的判断有些不同。
按照上面的描述,我们在更新(插入/删除)执行时,除了对节点加锁,还需要对记录根节点的数据加锁,并且使用独特的判断是否“安全的”方法。
在MiniOB中,可以参考LatchMemo,是直接使用xlatch/slatch对Mutex来记录加过的锁,这里可以直接把根节点数据保护锁,告诉LatchMemo,让它来负责相关处理工作。 判断根节点是否安全,可以参考IndexNodeHandler::is_safe中is_root_node相关的判断。
如何测试
想要保证并发实现没有问题是在太困难了,虽然有一些工具来证明自己的逻辑模型没有问题,但是这些工具使用起来也很困难。这里使用了一个比较简单的方法,基于google benchmark框架,编写了一个多线程请求客户端。如果多个客户端在一段时间内,一直能够比较平稳的发起请求与收到应答,就认为B+树的并发没有问题。测试代码在bplus_tree_concurrency_test.cpp文件中,这里包含了多线程插入、删除、查询、扫描以及混合场景测试。
其它
有条件的开启并发
MiniOB是一个用来学习的小型数据库,为了简化上手难度,只有使用-DCONCURRENCY=ON时,并发才能生效,可以参考 mutex.h中class Mutex和class SharedMutex的实现。当CONCURRENCY=OFF时,所有的加锁和解锁函数相当于什么都没做。
并发中的调试
死锁是让人非常头疼的事情,我们给Frame增加了调试日志,并且配合pin_count的动作,每次加锁、解锁以及pin/unpin都会打印相关日志,并在出现非预期的情况下,直接ABORT,以尽早的发现问题。这个调试能力需要在编译时使用条件 -DDEBUG=ON 才会生效。 以写锁为例:
void Frame::write_latch(intptr_t xid)
{
{
std::scoped_lock debug_lock(debug_lock_); // 如果非DEBUG模式编译,什么都不会做
ASSERT(pin_count_.load() > 0, // 加锁时,pin_count必须大于0,可以想想为什么?
"frame lock. write lock failed while pin count is invalid. "
"this=%p, pin=%d, pageNum=%d, fd=%d, xid=%lx, lbt=%s", // 这里会打印各种相关的数据,帮助调试
this, pin_count_.load(), page_.page_num, file_desc_, xid, lbt()); // lbt会打印出调用栈信息
ASSERT(write_locker_ != xid, "frame lock write twice." ...);
ASSERT(read_lockers_.find(xid) == read_lockers_.end(),
"frame lock write while holding the read lock." ...);
}
lock_.lock();
write_locker_ = xid;
LOG_DEBUG("frame write lock success." ...); // 加锁成功也打印一个日志。注意日志级别是DEBUG
}MiniOB中的事务
事务是数据库中非常基础的一个模块,也是非常核心的功能。事务有一些基本的概念,叫做ACID,分别是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
实现简介
MiniOB 作为一个帮助学习数据库的代码,为了使其学习起来更简单,实现了两种类型的事务。一个叫做Vacuous,另一个叫做MVCC,可以在启动observer时,选择特定的事务模块。
Vacuous(真空)
顾名思义,这个事务模块,将不会做任何事务相关的处理,这保留了原始的简单性,有利于学习其它模块时,简化调试。
MVCC
多版本并发控制,是一种常见的事务实现。著名的MySQL数据库也支持MVCC,OceanBase也实现了此机制。
简单来说,MVCC 会在修改 数据MiniOB当前支持插入和删除 时,不会直接在现有的数据上修改,而是创建一个新的行记录,将旧数据复制出来,在新数据上做修改。并将新旧数据使用链表的方式串联起来。每个数据都会有自己的版本号(或者称为时间戳),而版本号通常使用单调递增的数字表示,每个事务根据自己的版本号与数据的版本号,来判断当前能够访问哪个版本的数据。由此可见,MVCC 一个优点就是可以提高只读事务的并发度,它不与其它的写事务产生冲突,因为它访问旧版本的数据就可以了。
如何运行与测试
当前MiniOB支持两种类型的事务模型,并且默认情况下是Vacuous,即不开启事务特性。
测试MVCC
编译时增加选项 -DCONCURRENCY=ON:
然后在build目录执行 make。编译完成后启动 observer 服务端进程。
也可以使用 bash build.sh -DCONCURRENCY=ON 来编译
可以在启动observer时,增加 -t mvcc 选项来开启MVCC,假设当前目录是build(或build_debug之类):
./bin/observer -f ../etc/observer.ini -s miniob.sock -t mvcc
-f 是配置文件,-s 指使用unix socket,-t 指定使用的事务模型, 启动observer后,可以使用obclient连接observer:
./bin/obclient -s miniob.sock
可以开启多个客户端。在命令行界面执行 begin 可以开启事务,执行 commit 提交事务,rollback 回滚事务。
更多的实现原理
事务代码位于 src/observer/storage/trx 目录下,代码很少。
事务模型选择
trx.h 文件中有一个抽象类 TrxKit,它可以根据运行时参数传入的名字来创建对应的 VacuousTrxKit 和 MvccTrxKit。这两个类可以创建相应的事务对象,并且按照需要,初始化行数据中事务需要的额外表字段。当前 Vacuous 什么字段都不需要,而MVCC会额外使用一些表字段。
事务接口
不同的事务模型,使用了一些统一的接口,这些接口定义在 Trx 中。
事务本身相关的操作
- start_if_need。开启一个事务。在SQL请求处理过程中,通常需要开启一个事务;
- commit。提交一个事务;
- rollback。回滚一个事务。
行数据相关的操作
- insert_record。插入一行数据。事务可能需要对记录做一些修改,然后调用table的插入记录接口。提交之前插入的记录通常对其它事务不可见;
- delete_record。删除一行数据。与插入记录类似,也会对记录做一些修改,对MVCC来说,并不是真正的将其删除,而是让他对其它事务不可见(提交后);
- visit_record。访问一行数据。当遍历记录,访问某条数据时,需要由事务来判断一下,这条数据是否对当前事务可见,或者事务有访问冲突。
MVCC 相关实现
版本号与可见性
与常见的MVCC实现方案相似,这里也使用单调递增的数字来作为版本号。并且在表上增加两个额外的字段来表示这条记录有效的版本范围。两个版本字段是begin_xid和end_xid。每个事务在开始时,就会生成一个自己的版本号,当访问某条记录时,判断自己的版本号是否在该条记录的版本号的范围内,如果在,就是可见的,否则就不可见。
有些文章或者某些数据库实现中,使用”时间戳”来表示版本号。如果可以保证时间戳也是单调递增的,那这个时间戳确实更好可以作为版本号,并且在分布式系统中,比单纯的单调递增数字更好用。
记录版本号与事务版本号
行数据上的版本号,是事务设置的,这个版本号也是事务的版本号。一个写事务,通常会有两个版本号,在启动时,会生成一个版本号,用来在运行时做数据的可见性判断。在提交时,会再生成一个版本号,这个版本号是最终设置在记录上的。
trx start:
trx_id = next_id()
read record: is_visible(trx_id, record_begin_xid, record_end_xid)
trx commit:
commit_id = next_id()
foreach updated record: update record begin/end xid with commit_id
Q:为什么一定要在提交时生成一个新的版本号?只用该事务之前的版本号不行吗?会有什么问题?
版本号与插入删除
新插入的记录,在提交后,它的版本号是 begin_xid = 事务提交版本号,end_xid = 无穷大。表示此数据从当前事务开始生效,对此后所有的新事务都可见。 而删除相反,begin_xid 保持不变,而 end_xid 变成了当前事务提交的版本号。表示这条数据对当前事务之后的新事务,就不可见了。 记录还有一个中间状态,就是事务刚插入或者删除,但是还没有提交时,这里的修改对其它事务应该都是不可见的。
比如新插入一条数据,只有当前事务可见,而新删除的数据,只有当前事务不可见。需要使用一种特殊的方法来标记,当然也是在版本号上做动作。对插入的数据,begin_xid 改为 (-当前事务版本号)(负数),删除记录将end_xid改为 (-当前事务版本号)。在做可见性判断时,对负版本号做特殊处理即可。
假设某个事务运行时trx id是 Ta,提交时是 Tc
| operation | trx state | begin xid | end xid |
|---|---|---|---|
| inserted | committed | Tc | +∞ |
| deleted | committed | some trx_id | Tc |
| insert | uncommit | -Ta | +∞ |
| delete | uncommit | some trx_id | -Ta |
并发冲突处理
MVCC很好的处理了只读事务与写事务的并发,只读事务可以在其它事务修改了某个记录后,访问它的旧版本。但是写事务与写事务之间,依然是有冲突的。这里解决的方法简单粗暴,就是当一个写事务想要修改某个记录时,如果看到有另一个事务也在修改,就直接回滚。如何判断其它事务在修改?判断begin_xid或end_xid是否为负数就可以。
隔离级别
我们通常在聊事务隔离级别时,都会说脏读(Read Uncommitted)、读提交(Read Committed)、可重复读(Repeatable Read)和可串行化(Serializable),说这些时也通常都会提到大名鼎鼎的MySQL。但实际上隔离级别不止是这4种。 不过这里也没有对隔离级别做特殊的处理,让它顺其自然。
Q: 通过上面的描述,你知道这里的MVCC是什么隔离级别吗?
遗留问题和扩展
当前的MVCC是一个简化版本,还有一些功能没有实现,并且还有一些已知BUG。同时还可以扩展更多的事务模型。
事务提交时,对外原子可见
当前事务在提交时,会逐个修改之前修改过的行数据,调整版本号。这造成的问题是,在某个时刻,有些行数据的版本号已经修改了,有些还没有。那可能会存在一个事务,能够看到已经修改完成版本号的行,但是看不到未修改的行。 比如事务A,插入了3条数据,在提交的时候,逐个修改版本号,某个情况下可能会存在下面的场景(假设A的事务ID是90,commit id是100):
| record | begin xid | end xid | data |
|---|---|---|---|
| R1 | 100 | +∞ | … |
| R2 | 100 | +∞ | … |
| R3 | -90 | +∞ | … |
此时有一个新的事务,假设事务号是 110,那么它可以看到记录R1和R2,但是看不到R3,因为R3从记录状态来看,还没有提交。
垃圾回收
随着数据库进程的运行,不断有事务更新数据,不断产生新版本的数据,会占用越来越多的资源。此时需要一种机制,来回收对任何事务都不再可见的数据,这称为垃圾回收。垃圾回收也是一个很有趣的话题,实现方式有很多种。最常见的是,开启一个或多个后台线程,定期的扫描所有的行数据,检查它们的版本。如果某个数据对当前所有活跃事务都不可见,那就认为此条数据是垃圾,可以回收掉。当然,这种回收方法最简单,也是最低效的,同学们如何优化或者实现新的回收方法。
多版本存储
当前miniob仅实现了插入和删除,并不支持更新操作。而插入和删除最多会存在两个版本的数据,从实现上来看,最多需要一条数据就可以。这大大简化了MVCC的实现。但是也因此没有涉及到MVCC非常核心的多版本数据存储问题。如何合理的存储多个版本的数据,对数据库的性能影响也是巨大的。比如多个版本数据串联时,使用从新到旧,还是从旧到新。两种方式都有合理性,适用于不同的场景。另外还有,多版本的数据存储在哪里?内存还是磁盘,是与原有的数据放在同一个存储空间,还是规划单独的空间,各有什么优缺点,都适用于什么场景。还有,更新数据时,复制整行数据,还是仅记录更新的字段。各有什么优缺点,各适用于什么场景。
持久化事务
持久性是事务的基本要素之一,是指事务修改后的数据,在数据库重启或者出现异常时,能够从磁盘中将数据恢复出来。除了将修改的数据直接写入到磁盘,还有一个常用的技术手段是WAL,比如Redo日志和Undo日志。那么什么情况下使用Redo,什么时候使用Undo,以及如果只使用Redo或者只使用Undo会有什么问题。另外还有如何存储这些日志,B+树的持久化怎么处理等。有兴趣的同学可以再了解一下
Steal/No-Steal和Force/No-Force的概念。MVCC的并发控制
如前文描述,这里的写事务并发冲突处理过于简单粗暴,以至于可以避免的冲突却没有避免。
基于锁的并发控制
MVCC的并发控制通常认为是乐观事务,就是我们认为此系统中事务之间大部分情况下不会存在冲突。但是在OLTP系统中,访问冲突可能是非常频繁发生的,这时候使用悲观事务,效率会更高一点。常见的悲观事务实现方法就是基于锁来实现。假设使用记录锁(行锁)来实现并发,在读数据时加读锁,写时加写锁,也可以实现多种级别的隔离机制。另外,还可以将使用基于锁的机制与MVCC结合起来,实现更好的并发控制。
顺便提一下一个常见的问题,就是在使用行锁时,如何与页面锁(latch)协调? 大家都知道,latch 都是短锁,在latch保护范围内,都不应该出现长期等待的事情。另外,latch没有死锁检测,不处理锁冲突。而行锁是一种长锁,需要做锁冲突处理,可能需要等待。那在拿着某个latch时,需要等待行锁时,如何处理?
补充学习
事务是非常复杂非常有趣的,相关的话题也已经有非常多的研究。如果对事务感兴趣,可以在了解数据库整体实现基础之上,深入研究事务的实现原理。 这里推荐一些介绍数据库入门的书籍:
- 《数据库系统概念》该书是数据库领域的经典教材之一,涵盖了数据库基本概念、关系型数据库设计、事务处理、并发控制等方面的内容,也可以着重阅读事务相关的内容
- 《数据库系统实现》:该书是一本数据库系统实现方面的教材,讲解了数据库系统的核心组成部分,包括事务处理、索引、查询优化等方面的内容,对事务处理机制进行了较为细致的讲解
- 《MySQL技术内幕:InnoDB存储引擎》:该书是一本MySQL数据库方面的重要教材,对InnoDB存储引擎的事务处理机制进行了详细的阐述,包括事务的隔离级别、MVCC实现、锁机制等方面。
- A Critique of ANSI SQL Isolation Levels 该论文针对ANSI SQL标准中隔离级别的定义进行了深入的分析,提出了一些改进的建议。天天看到RC/RR名词的,可以看看这篇论文,了解更详细一点。
- Granularity of Locks and Degrees of Consistency in a Shared Data Base 这也是一个又老又香的论文,提出了基于锁的并发控制。
- An Empirical Evaluation of InMemory Multi-Version Concurrency Control 介绍MVCC可扩展性的。通过这篇论文可以对MVCC有非常清晰的认识。
- Scalable Garbage Collection for In-Memory MVCC Systems 这里对各种垃圾回收算法做了说明,并且有些创新算法。
MiniOB中的 SQL Parser
SQL 解析分为词法分析与语法分析,与编译原理中介绍的类似。这里主要介绍如何扩展MiniOB的SQL解析器,并对词法分析和语法分析文件做一些简单的介绍。
词法分析
词法分析文件 lex_sql.l
词法分析的基本功能是读取文件或字符串的一个一个字符,然后按照特定的模式(pattern)去判断是否匹配,然后输出一个个的token。比如对于 CALC 1+2,词法分析器会输出 CALC、1、+、2、EOF。
扩展功能时,我们最关心的是词法分析的模式如何编写以及flex如何去执行模式解析的。 在lex_sql.l文件中,我们可以看到这样的代码:
[\-]?{DIGIT}+ yylval->number=atoi(yytext); RETURN_TOKEN(NUMBER);
HELP RETURN_TOKEN(HELP);
DESC RETURN_TOKEN(DESC);
CREATE RETURN_TOKEN(CREATE);
DROP RETURN_TOKEN(DROP);每一行都是一个模式,左边是模式,使用正则表达式编写,右边是我们返回的token,这里的token是枚举类型,是我们在yacc_sql.y中定义的。
[\-]?{DIGIT}+ 就是一个表示数字的正则表达式。 HELP 表示完全匹配”HELP” 字符串。
flex 在匹配这些模式时有一些规则,如果输出的结果与自己的预期不符,可以使用这些规则检查一下,是否自己写的模式和模式中的顺序是否符合这些规则:
- 优先匹配最长的模式
- 如果有多个模式匹配到同样长的字符串,那么优先匹配在文件中靠前的模式
另外还有一些词法分析的知识点,都在lex_sql.l中加了注释,不多做赘述,在这里罗列提示一下。
- flex 根据编写的 .l 规则文件,和指定的命令生成.c代码。不过miniob把.c文件改成了.cpp后缀;
%top{}的代码会放在flex生成的代码最开头的地方;%{ %}中的代码会被移动到flex生成的代码中;- flex提供了一些选项,可以在命令行中指定,也可以在.l文件中,使用 %option指定;
- flex 中编写模式时,有一些变量是预定义的,yylval就是返回值,可以认为是yacc中使用%union定义的结构; yytext 是解析的当前token的字符串,yyleng 是token的长度,yycolumn 是当前的列号,yylineno 是当前行号;
- 如果需要每个token在原始文本中的位置,可以使用宏定义 YY_USER_ACTION,但是需要自己编写代码记录才能传递给yacc;
%% %%之间的代码是模式匹配代码,之后的代码会被复制到生成代码的最后。
语法分析
语法分析文件 yacc_sql.y
语法分析的基本功能是根据词法分析的结果,按照语法规则,生成语法树。
与词法分析类似,语法分析工具(这里使用的是bison)也会根据我们编写的.y规则文件,生成.c代码,miniob 这里把.c代码改成了.cpp代码,因此.y文件中可以使用c++的语法和标准库。
类似词法分析,我们在扩展语法分析时,最关心的也只有规则编写的部分。
在yacc_sql.y文件中,我们可以看到这样的代码:
expression_list:
expression
{
$$ = new std::vector<Expression*>;
$$->emplace_back($1);
}
| expression COMMA expression_list {
if ($3 != nullptr) {
$$ = $3;
} else {
$$ = new std::vector<Expression *>;
}
$$->emplace_back($1);
}
;这个规则描述表达式列表的语法,表达式列表可以是单个表示,或者”单个表达式 逗号 表达式列表”的形式,第二个规则是一个递归的定义。 可以看到,多个规则模式描述使用 “|” 分开。
为了方便说明,这里再换一个语句:
create_table_stmt: /*create table 语句的语法解析树*/
CREATE TABLE ID LBRACE attr_def attr_def_list RBRACE
{
$$ = new ParsedSqlNode(SCF_CREATE_TABLE);
CreateTableSqlNode &create_table = $$->create_table;
create_table.relation_name = $3;
free($3);
std::vector<AttrInfoSqlNode> *src_attrs = $6;
if (src_attrs != nullptr) {
create_table.attr_infos.swap(*src_attrs);
}
create_table.attr_infos.emplace_back(*$5);
std::reverse(create_table.attr_infos.begin(), create_table.attr_infos.end());
delete $5;
}
;
每个规则描述,比如create_table_stmt 都会生成一个结果,这个结果在.y中以 “$$“ 表示,某个语法中描述的各个token,按照顺序可以使用 “$1 $2 $3” 来引用,比如ID 就是 $3, attr_def 是 $5。”$n” 的类型都是 YYSTYPE。
YYSTYPE 是bison根据.y生成的类型,对应我们的规则文件就是 %union,YYSTYPE 也是一个union结构。比如 我们在.y文件中说明 %type <sql_node> create_table_stmt,表示 create_table_stmt 的类型对应了 %union 中的成员变量 sql_node。我们在 %union 中定义了 ParsedSqlNode * sql_node;,那么 create_table_stmt 的类型就是 ParsedSqlNode *,对应了 YYSTYPE.sql_node。
%union 中定义的数据类型,除了简单类型,大部分是在parse_defs.h中定义的,表达式Expression是在expression.h中定义的,Value是在value.h中定义的。
由于在定义语法规则时,这里都使用了左递归,用户输入的第一个元素会放到最前面,因此在计算得出最后的结果时,我们需要将列表(这里很多使用vector记录)中的元素逆转一下。
语法分析中如何使用位置信息
首先我们要在.y文件中增加%locations,告诉bison我们需要位置信息。其次需要与词法分析相配合,需要词法分析返回一个token时告诉语法分析此token的位置信息,包括行号、token起始位置和结束位置。与访问规则结果 $$ 类似,访问某个元素的位置信息可以使用 @$、 @1、@2 等。
词法分析中,yylineno记录当前是第几行,不过MiniOB当前没有处理多行文本。yycolumn记录当前在第几列,yyleng记录当前token文本的长度。词法分析提供了宏定义 YY_USER_INIT 可以在每次解析之前执行一些代码,而 YY_USER_ACTION 宏在每次解析完token后执行的代码。我们可以在YY_USER_INIT宏中对列号进行初始化,然后在YY_USER_ACTION计算token的位置信息,然后使用 yylloc 将位置信息传递给语法分析。而在引用 @$ 时,就是引用了 yylloc。
这些宏定义和位置的引用可以参考lex_sql.l和yacc_sql.y,搜索相应的关键字即可。
如果觉得位置信息传递和一些特殊符号 $$或 @$ 等使用感到困惑,可以直接看 flex和bison生成的代码,会让自己理解的更清晰。
如何编译词法分析和语法分析模块
在 src/observer/sql/parser/ 目录下,执行以下命令:
./gen_parser.sh
将会生成词法分析代码 lex_sql.h 和 lex_sql.cpp,语法分析代码 yacc_sql.hpp 和 yacc_sql.cpp。
注意:flex 使用 2.5.35 版本测试通过,bison使用3.7版本测试通过(请不要使用旧版本,比如macos自带的bision)。
注意:当前没有把lex_sql.l和yacc_sql.y加入CMakefile.txt中,所以修改这两个文件后,需要手动生成c代码,然后再执行编译。
如果使用visual studio code,可以直接选择 “终端/Terminal” -> “Run task…” -> “gen_parser”,即可生成代码。
如何调试词法分析和语法分析模块
代码中可以直接使用日志模块打印日志,对于yacc_sql.y也可以直接使用gdb调试工具调试。
参考
MiniOB中新增支持一种SQL语句
当前的SQL实现已经比较复杂,这里以新增一个简单的SQL语句为例,介绍如何新增一种类型的SQL语句。 在介绍如何新增一种类型的SQL语句之前,先介绍一下MiniOB的SQL语句的执行流程。
SQL语句执行流程
MiniOB的SQL语句执行流程如下图所示:
左侧是执行流程节点,右侧是各个执行节点输出的数据结构。
┌──────────────────┐ ┌──────────────────┐
│ SQL │ ---> │ String │
└────────┬─────────┘ └──────────────────┘
│
┌────────▼─────────┐ ┌──────────────────┐
│ Parser │ ---> │ ParsedSqlNode |
└────────┬─────────┘ └──────────────────┘
│
│
┌────────▼─────────┐ ┌──────────────────┐
│ Resolver │ ---> │ Statement │
└────────┬─────────┘ └──────────────────┘
│
│
┌────────▼─────────┐ ┌──────────────────┐
│ Transformer │ ---> │ LogicalOperator |
└────────┬─────────┘ │ PhysicalOperator │
│ │ or │
┌────────▼─────────┐ │ CommandExecutor |
│ Optimizer │ ---> │ │
└────────┬─────────┘ └──────────────────┘
│
┌────────▼─────────┐ ┌──────────────────┐
│ Executor │ ---> │ SqlResult │
└──────────────────┘ └──────────────────┘
- 我们收到了一个SQL请求,此请求以字符串形式存储;
- 在Parser阶段将SQL字符串,通过词法解析(lex_sql.l)与语法解析(yacc_sql.y)解析成ParsedSqlNode(parse_defs.h);
- 在Resolver阶段,将ParsedSqlNode转换成Stmt(全称 Statement, 参考 stmt.h);
- 在Transformer和Optimizer阶段,将Stmt转换成LogicalOperator,优化后输出PhysicalOperator(参考 optimize_stage.cpp)。如果是命令执行类型的SQL请求,会创建对应的 CommandExecutor(参考 command_executor.cpp);
- 最终执行阶段 Executor,工作量比较少,将PhysicalOperator(物理执行计划)转换为SqlResult(执行结果),或者将CommandExecutor执行后通过SqlResult输出结果。
新增一种类型的SQL语句
这里将以CALC类型的SQL为例介绍。
CALC 不是一个标准的SQL语句,它的功能是计算给定的一个四则表达式,比如:
CALC 1+2*3
CALC 在SQL的各个流程中,与SELECT语句非常类似,因此在增加CALC语句时,可以参考SELECT语句的实现。
首先在Parser阶段,我们需要考虑词法分析和语法分析。CALC 中需要新增的词法不多,简单的四则运算中只需要考虑数字、运算符号和小括号即可。在增加CALC之前,只有运算符号没有全部增加,那我们加上即可。参考 lex_sql.l。
"+" |
"-" |
"*" |
"/" { return yytext[0]; }在语法分析阶段,我们参考SELECT相关的一些解析,在yacc_sql.y中增加CALC的一些解析规则,以及在parse_defs.h中SELECT解析后的数据类型,编写CALC解析出来的数据类型。 当前CALC是已经实现的,可以直接在parse_defs.h中的类型定义。 yacc_sql.y中需要增加calc_stmt,calc_stmt的类型,以及calc_stmt的解析规则。由于calc_stmt涉及到表达式运算,所以还需要增加表达式的解析规则。具体可以参考yacc_sql.y中关于calc的代码。
在语法解析结束后,输出了CalcSqlNode,后面resolver阶段,将它转换为Stmt,这里就是新增CalcStmt。通常在resolver阶段会校验SQL语法树的合法性,比如查询的表是否存在,运算类型是否正确。在CalcStmt中,逻辑比较简单,没有做任何校验,只是将表达式记录下来,并且认为这里的表达式都是值类型的计算。
在Transformer和Optmize阶段,对于查询类型的SQL会生成LogicalOperator和PhysicalOperator,而对于命令执行类型的SQL会生成CommandExecutor。CALC是查询类型的SQL,参考SELECT的实现,在SELECT中,有PROJECT、TABLE_SCAN等类型的算子,而CALC比较简单,我们新增CalcLogicalOperator和CalcPhysicalOperator。
由于具有执行计划的SQL,在Executor阶段,我们仅需要给SqlResult设置对应的TupleSchema即可,可以参考ExecuteStage::handle_request_with_physical_operator。
总结一下,新增一种类型的SQL,需要在以下几个地方做修改:
- 词法解析,增加新的词法规则(lex_sql.l);
- 语法解析,增加新的语法规则(yacc_sql.y);
- 增加新的SQL语法树类型(parse_defs.h);
- 增加新的Stmt类型(stmt.h);
- 增加新的LogicalOperator和PhysicalOperator(logical_operator.h, physical_operator.h, optimize_stage.cpp,如果有需要);
- 增加新的CommandExecutor(command_executor.cpp,如果有需要);
- 设置SqlResult的TupleSchema(execute_stage.cpp,如果有需要)。
MiniOB中的表达式解析
表达式是SQL操作中非常基础的内容。 我们常见的表达式就是四则运算的表达式,比如1+2、3*(10-3)等。在常见的数据库中,比如MySQL、OceanBase,可以运行 select 1+2、select 3*(10-3),来获取这种表达式的结果。但是同时在SQL中,也可以执行 select 1、select field1 from table1,来查询一个常量或者一个字段。那我们就可以把表达式的概念抽象出来,认为常量、四则运算、表字段、函数调用等都是表达式。
MiniOB 中的表达式实现
当前MiniOB并没有实现上述的所有类型的表达式,而是选择扩展SQL语法,增加了 CALC 命令,以支持算术表达式运算。这里就以 CALC 支持的表达式为例,介绍如何在 MiniOB 中实现表达式。在介绍实现细节之前先看下一个例子以及它的执行结果:
CALC 1+2执行结果:1+2 3
注意这个表达式输出时会输出表达式的原始内容。
SQL 语句
MiniOB 从客户端接收到SQL请求后,会创建 SessionEvent,其中 query_ 以字符串的形式保存了SQL请求。 比如 CALC 1+2,记录为”CALC 1+2”。
SQL Parser
Parser部分分为词法分析和语法分析。如果对词法分析语法分析还不了解,建议先查看 SQL Parser。
词法分析
算术表达式需要整数、浮点数,以及加减乘除运算符。我们在lex_sql.l中可以看到 NUMBER 和 FLOAT的token解析。运算符的相关模式匹配定义如下:
"+" | "-" | "*" | "/" { return yytext[0]; }
语法分析
因为 CALC 也是一个完整的SQL语句,那我们先给它定义一个类型。我们定义一个 CALC 语句可以计算多个表达式的值,表达式之间使用逗号分隔,那 CalcSqlNode 定义应该是这样的:
struct CalcSqlNode {
std::vector<Expression *> expressions;
};在 yacc_sql.y 文件中,我们增加一种新的语句类型 calc_stmt,与SELECT类似。它的类型也是sql_node:
%type <sql_node> calc_stmt
接下来分析 calc_stmt 的语法规则。
calc_stmt:
CALC expression_list
{
$$ = new ParsedSqlNode(SCF_CALC); // CALC的最终类型还是一个ParsedSqlNode
std::reverse($2->begin(), $2->end()); // 由于左递归的原因,我们需要得出列表内容后给它反转一下
// 直接从 expression_list 中拿出数据到目标结构中,省的再申请释放内存
$$->calc.expressions.swap(*$2);
delete $2; // expression_list 本身的内存不要忘记释放掉
}
;
CALC expression_list CALC 仅仅是一个关键字。expression_list 是表达式列表,我们需要对它的规则作出说明,还要在%union和 %type 中增加其类型说明。
%union {
...
std::vector<Expression *> *expression_list;
...
}
...
%type <expression_list> expression_list
expression_list 的规则如下:
expression_list:
expression // 表达式列表可以是单个表达式
{
$$ = new std::vector<Expression*>;
$$->emplace_back($1);
}
// 表达式列表也可以是逗号分隔的多个表达式,使用递归定义的方式说明规则
| expression COMMA expression_list
{
if ($3 != nullptr) {
$$ = $3;
} else {
$$ = new std::vector<Expression *>; // 表达式列表的最终类型
}
$$->emplace_back($1); // 目标结果中多了一个元素。
}
;expression 的规则会比较简单,加减乘除,以及负号取反。这里与普通的规则不同的是,我们需要关心运算符的优先级,以及负号运算符的特殊性。
优先级规则简单,乘除在先,加减在后,如果有括号先计算括号的表达式。
%left '+' '-'
%left '*' '/'%left 表示左结合,就是遇到指定的符号,先跟左边的符号结合。而定义的顺序就是优先级的顺序,越靠后的优先级越高。
负号运算符的特殊性除了它的优先级,还有它的结合性。普通的运算,比如 1+2,是两个数字即两个表达式,一个运算符。而负号的表示形式是 -(1+2),即一个符号,一个表达式。
%nonassoc UMINUS表示 UMINUS 是一个一元运算符,没有结合性。在.y中,放到了 %left '*' '/' 的后面,说明优先级比乘除运算符高。
expression 的规则如下:
expression '+' expression {
$$ = create_arithmetic_expression(ArithmeticExpr::Type::ADD, $1, $3, sql_string, &@$);
}
| expression '-' expression {
$$ = create_arithmetic_expression(ArithmeticExpr::Type::SUB, $1, $3, sql_string, &@$);
}
| expression '*' expression {
$$ = create_arithmetic_expression(ArithmeticExpr::Type::MUL, $1, $3, sql_string, &@$);
}
| expression '/' expression {
$$ = create_arithmetic_expression(ArithmeticExpr::Type::DIV, $1, $3, sql_string, &@$);
}
| LBRACE expression RBRACE { // '(' expression ')'
$$ = $2;
$$->set_name(token_name(sql_string, &@$));
}
// %prec 告诉yacc '-' 负号预算的优先级,等于UMINUS的优先级
| '-' expression %prec UMINUS {
$$ = create_arithmetic_expression(ArithmeticExpr::Type::NEGATIVE, $2, nullptr, sql_string, &@$);
}
| value {
$$ = new ValueExpr(*$1);
$$->set_name(token_name(sql_string, &@$));
delete $1;
}
;create_arithmetic_expression 是一个创建算术表达式的函数,它的实现在.y文件中,不再罗列。
表达式的名称,需要在输出结果中展示出来。我们知道当前的SQL语句,也知道某个token的开始列号与截止列号,就可以计算出来这个表达式对应的SQL命令输入是什么。在 expression 规则描述中,就是 $$->set_name(token_name(sql_string, &@$));,其中 sql_string 就是当前的SQL语句,@$ 是当前的token的位置信息。
抽象表达式类型
上面语法分析中描述的都是算术表达式,但是真实的SQL语句中,像字段名、常量、比较运算、函数、子查询等都是表达式。我们需要定义一个基类,然后派生出各种表达式类型。
这些表达式的定义已经在expression.h中定义,但是没有在语法解析中体现。更完善的做法是在 select 的属性列表、where 条件、insert 的 values等语句中,都使用表达式来表示。
‘-‘ 缺陷
由于在词法分析中,负号’-‘与数字放在一起时,会被认为是一个负值数字,作为一个完整的token返回给语法分析,所以当前的语法分析无法正确的解析下面的表达式:
1 -2;
这个表达式的结果应该是 -1,但是当前的语法分析会认为是两个表达式,一个是1,一个是-2,这样就无法正确的计算出结果。 当前修复此问题的成本较高,需要修改词法分析的规则,所以暂时不做处理。
SQL引擎
SQL层整体架构
数据库在长期发展过程中已经有了成熟的工程结构,对于传统的SQL内核层来说,基本构架图如左图所示,其中oceanBase处理一条SQL请求的架构图如右图所示。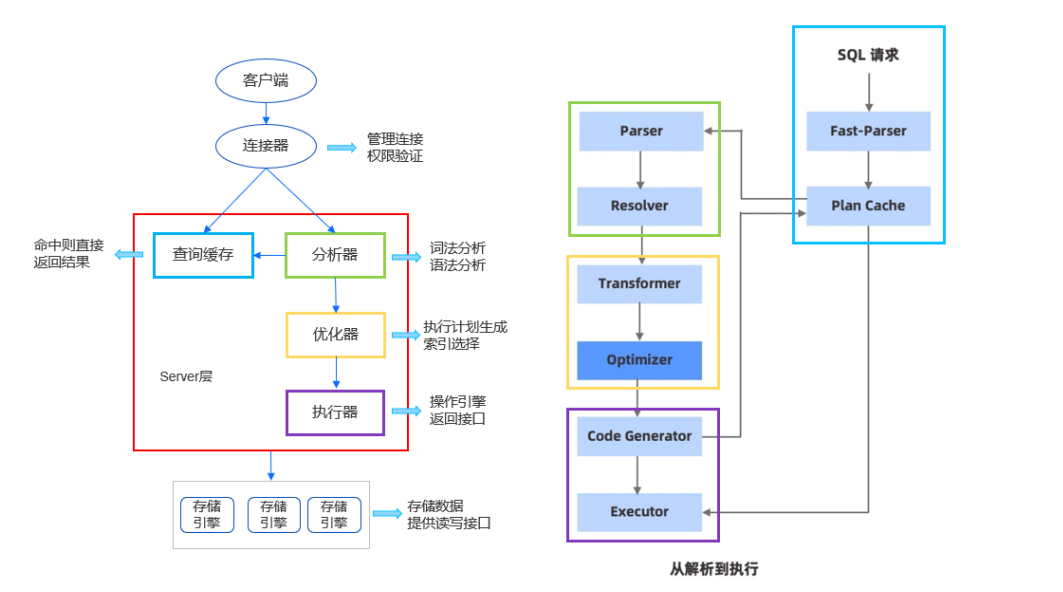
左图中MySQL在SQL层主要处理了查询缓存部分、分析器、优化器、执行器这几部分。现在按照对应的流程模块走一遍。
SQL语句结构
只要接触数据库,不管是使用还是研究内核部分,都应该对SQL语句执行的顺序有了解。
SELECT<字段名>(9)
FROM<表名>(1)
JOIN<表名>(2)
ON<连接条件>〔2)
WHERE<筛选条件>〔5)
GROUP BY<字段名>(4)
HAVING<筛选条件>(5〕
ORDER BY<字段名>(7)
LIMIT<限制行数>(8)
#此处不包含subquery每个SQL语句后面的序号就是其执行的序号,可以看到对于正常书写顺序和执行的顺序是不同的,通常来说这样的执行顺序能够降低操作时的数据量。
Parser和Resolver模块
Parser模块
这部分是编译原理部分的内容,当一条SQL请求到达server端时,首先需要到parser模块,这个模块的作用就是根据Yacc和Flex工具自动生成的语法结构,判断SQL语句是否符合语法结构。
如下图所示,SQL语句SELECT c1+c2 FROM t1 WHERE exists再接着一个子查询,然后子查询是由union all连接的另外两个子查询。Parser模块最终解析出来的是一个逻辑结构图,就像示例图中这样一个树状结构。
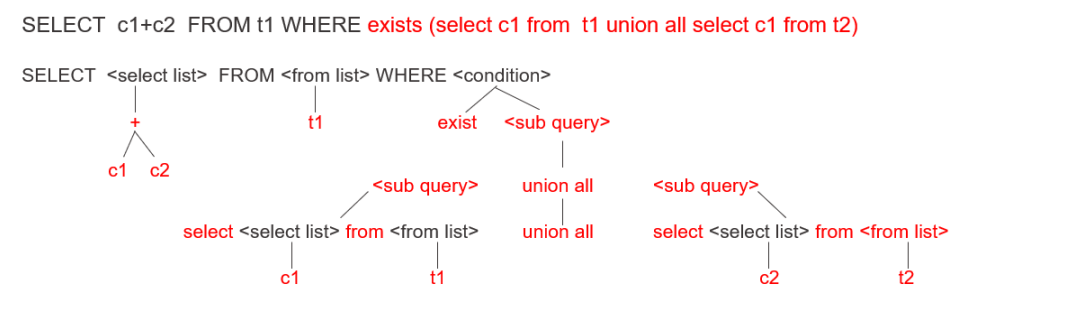
接下来介绍一下具体是如何实现的,无论是SELECT、FROM还是WHERE,都会有自己所附带的一些成分。
select list是一个表达式操作,即 c1 + c2。再递归解析,它的根节点是+,两个子节点分别是参与运算的两个常量 c1 和 c2 。
from list的参数其实是一个relation,也就是一个表名,即t1。
Where代表的是condition条件,这里的condition操作符是exists,exists后面是一sub query。这sub query可以递归地向下去分解,它是由union all所连接起来的两个sub query。同理这两个sub query也可以再递归地向下展开。
一条SQL语句,无论写得多么复杂,本质上就是一层一层嵌套的树状结构。Parser模块这一个部分主要做的就是根据用户所写的语法规则正确的识别,并将一条SQL语句转化为一个语法树的结构。但一条符合语法树规则的SQL不一定是一条“合格”的SQL,数据库中还存在着许多约束,一条SQL还必须满足语义的约束,许多语法的约束以及虚视图的展开都是在Resolver模块中完成的。
Resolver模块
Resolver模块需要对Parser模块所生成的符合语法规则的语法树进一步进行检查其约束,也就是语义解析的部分。
虽然说Resolver模块是对Parser模块的语法树的一个检查转换,但是在执行的时候在这一层,数据库会将其转化为STMT(statement)阶段。
如SQL语句SELECT c1+c2 FROM t1 WHERE exists( seLect c1 from t1 union all seLect c1 from t2)转换成了StatementTree,大家可以观察一下,在OceanBase中Resolver这层是怎么去表示 Statement结构,这个结构是多个OceanBase Statement和表达式对象的集合,多个Statement对象在 OceanBase中可以表达一些查询中的子查询。
Statement结构既不是关系运算的表示,也不是树状结构,而是具体在执行时的工程上的实现。
Transformer和optimizer模块
通过前几节的介绍,了解了一条SQL请求在Parser模块主要关注的是语法树逻辑结构,在Resolver模块主要关注的是符合语义要求的树形的结构。在OceanBase中,数据结构在Resolver层实际上是一个Statement,这也是OceanBase后续进行Transformer和optimizer改写的基础。
不过在Transformer和optimizer层,重点需要关注的是火山模型的结构,Executor模块。这里介绍一个示例来帮助大家理解,示例中SQL的语义是:挑选出某场电影的名字和卖出的票数,并且它的票数需要大于50张。这里假设在七点钟,只有一场电影在播放,并且卖出的票数超过了100张。即当执行这条SQL的时候,会查出这场电影和卖出的票数。
SELECT movie.name,play.ticket
FROM movie
JOIN ptLay
ON movie.time=pLay.time
WHERE pLay.ticket>59;下图所示是这条SQL简单的执行计划。首先分别对两张表进行全部字段的遍历,遍历所有字段后做表连接操作,操作的条件为movie.time=pLay.time,即时间一致。连接之后生成一张新表,再去根据条件play.ticker>59去过滤,最后将需要查询的play.ticker和movie.name给投影出来。
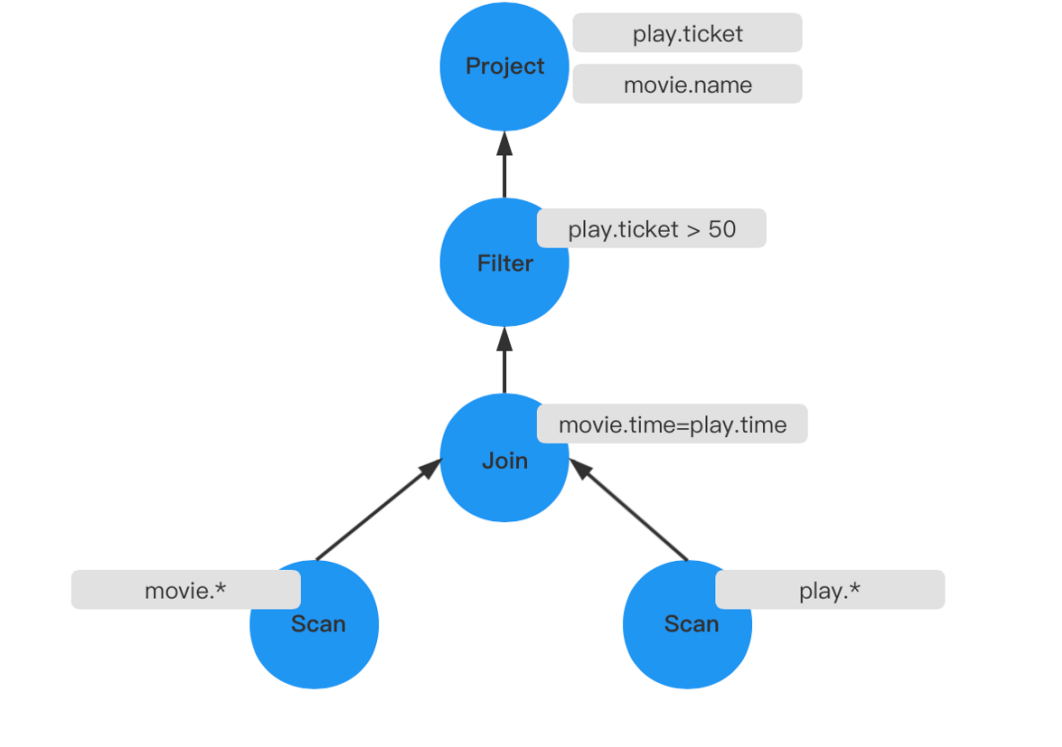
投影操作实际上只需要投影出特定的列,包括在做Join条件时也是要需要一个时间的字段,所以第一个优化是减少遍历属性,可以将上层的投影给去掉,然后将Scan的操作只遍历特定的属性,两张表都是这样,做完这个优化后,就减少了一个投影操作。
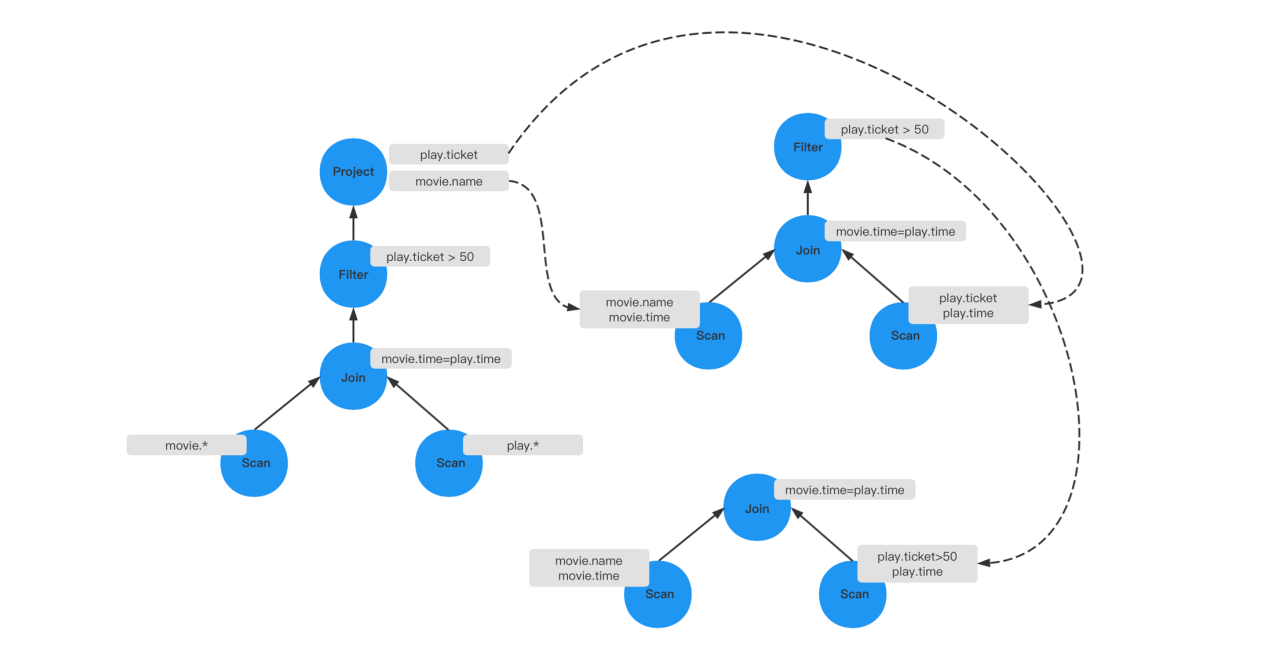
第二个优化是因为最终符合条件的只需要卖出的票数大于50张的场次,所以在遍历Play表的时候,不需要将所 有的电影及对应票数都筛选出来,只需要筛选出票数大于50张的排片。 经过优化之后它由四层的结构变成了两层,只需记历出需要的字段,然后做一个Join操作就可以了。不仅操作路 径变短了,而且表的连接项也变得更少了,相比之前查询计划更优。
这两个模块最重要的部分就是需要如何从一个火山模型的层次调用结构去看是否有更多的优化空间。
Executor模块
Executor模块中最经典的模型是VolcanoModel(火山模型),它是一种基于行的流式迭代模型(Row-BasedStreamingIteratorModel)。在火山模型中,所有的代数运算符(operator)都被看成是一个迭代器,它们都提供一组简单的接口:open( )一next( )一close( ),查询计划树由一个个这样的关系运算符组成,每一次的next( )调用,运算符就返回一行(Row),每一个运算符的next( )都有自己的流控逻辑,数据通过运算符自上而下的next( )符套调用而被动的进行拉取。
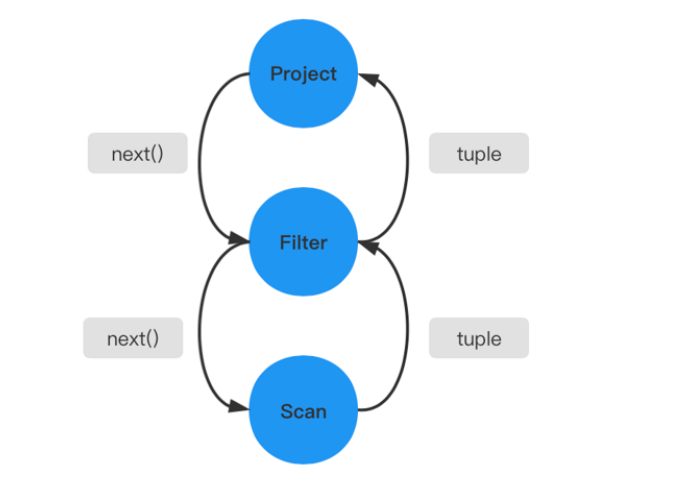
火山模型中每一个运算符都将下层的输入看成是一张表,next()接口的一次调用就获取表中的一行数据,这样设计的优点是:每个运算符之间的代数计算是相互独立的,并且运算符可以伴随查询关系的变化出现在查询计划树的任意位置,这使得运算符的算法实现变得简单并且富有拓展性。
这种设计也会存在一些问题,如果没有一些阻塞性的操作,整个火山模型只需要很少的内存就能运作起来,每次只需要人迭代一个tuple行。但有一些Operator(如sort),它是阻塞性的操作,要拿到所有的tuple之后,才能进行进行运算,这种操作符实际上是破坏了火山模型整体的流水性的运算。
目前火山模型在原先基础上有不断改进,具体内容可以搜索了解。
额外知识补充
SEDA架构模式
具体论文为:SEDA: An Architecture for Well-Conditioned, Scalable Internet Services(分阶段事件驱动架构)
staged event-driven architecture (SEDA) 框架在建模的时候就将负载和资源瓶颈考虑在内,从而可以在高负载的情况下也能工作良好,并且有效防止服务过载。SEDA 架构的基本思想是将业务逻辑切分成一系列通过 queues 连接起来的 stages,组合成一个 data flow 网络去执行。
基于线程并发
最简单直接的方式就是每来一个请求就启动一个线程去处理。这么做的好处是编程模型极其简单,调度隔离之类的问题都交给操作系统来保证了,也比较可靠。缺点是在负载较高的时候,会产生不可忽视的开销。因为物理资源是有限的,尽管操作系统层面做了一层抽象,使得看起来我们可以获得非常多的资源,但是这都是假象,在高负载情况下会暴露无遗。每个线程分到的时间片都是有限的,非常多的线程在频繁的进行上下文切换,缓存在不断的抖动,线程调度的开销随着问题规模增加而增加,锁资源争用,这些因素都会带来性能的急剧下降。而且线程频繁创建和销毁也会带来可观的开销。从作者给的图表来看,超过系统承载能力之后再持续加压,会导致系统性能下降。我们预期通过某些手段能够自保,从而维持在巅峰性能附近。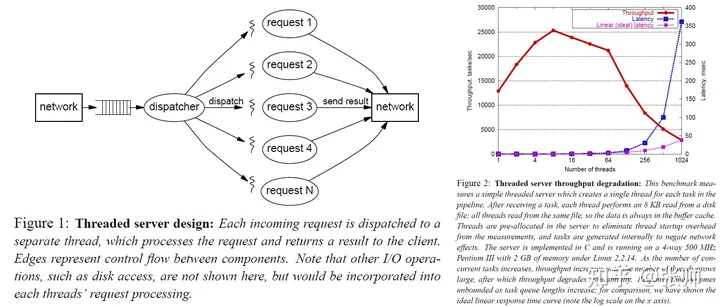
基于线程池并发
一个简单的改进方法就是使用线程池。这样的话至少可以解决线程数量过多带来的问题。作者在这里提到,在高负载情况下,这样会带来公平性问题。
公平性问题在多租户系统中确实是一个非常重要的问题,也是系统规模做到一定程度时必须面对的一个问题。这里稍微啰嗦一下,展开说两句。简单来说,多租户服务的资源利用率是远高于单租户服务的。租户足够多,且足够多样性的情况下,有的用户在忙的时候,通常也有一些用户在空闲。这样就带来了整体利用率上的提升。首先我们要做到公平,这样就不会因为有一个人意外使用了特别多的资源,而影响到其他正常使用服务的用户。否则由于用户体验的下降,用户会拒绝使用你的服务。更进一步的,也许我们需要对用户进行分级服务,高优先级的用户可以抢占使用低优先级用户的资源,当然定价可能也是分级的。
作者提到的公平性问题发生在这样的场景下。负载特别高的情况下,我们处理请求的速度跟不上产生请求的速度。大量的请求堆积在任务分发队列,甚至是网络协议栈上。在这种情况下新来的一个请求,其整体延迟应该是排队等待的延迟加上实际执行处理的延迟。而排队等待延迟是不可控的,并且由于过载的问题没有办法得到妥善的调度,因此有违公平性。更常规的情况是,有部分用户的请求量异常,超出他们自己的配额,但是没有超出整个服务的承载能力,或者超出了整个服务的承载能力,但是不是特别夸张,比如说只超出了一两倍(取决于你业务逻辑的复杂程度)。对于前者,我们通过配额管理,可以在这个请求被调度进行处理的时候,将这个请求拒绝掉,从而避免了执行业务逻辑的负担。通过这种方式,我们可以一定程度上提高我们系统的承载能力。如果负载进一步上升,可能我们拒绝的速度都追不上产生请求的速度,这种情况下,也许我们可以采取网卡队列管理的一些策略,例如 Random Early Discard,进一步提升我们系统的承载能力(但是已经是有损的了)。
作者也举例了一种比较有意思的场景。比如说空闲的时候来了几个比较大的请求,把线程池里面的线程都用上了(但是没有后续排队的请求);然后突然来了一堆小请求,尽管我们如果多一个空闲线程就能处理过来,但是现在没有任何一个活动线程能来得及干这个事情。这可能需要 case-by-case 的去做一些更精细的策略调整,比如说对请求大小进行分类,避免一种请求把所有活动线程都占了。
基于“事件驱动”并发
从作者的大致描述来看,感觉就是一个传统的使用 epoll 驱动的事件模型。几乎所有的 blocking I/O 都被转化成了 event,然后再被投递到各个子模块中继续处理。每个子模块自己使用状态机管理状态,这样 request context 就被状态机管理起来,而不是直接放到 thread context 上了。由于Scheduler的设计和实现过于复杂,针对于不同的应用和系统的逻辑变更需要不同的实现,导致采用这一模型构建出的系统将十分庞大和难以控制。
- 每个子模块需要小心的维护 request context
- 所有的业务逻辑需要尽可能地避免 blocking,否则可能阻塞 event dispatcher
- 每新增一个子模块可能就需要修改 event dispatcher 的逻辑,特别是调度 event 的逻辑(比如说同一类 event 聚合一波一起处理可能会增加缓存命中率进而提高效率)
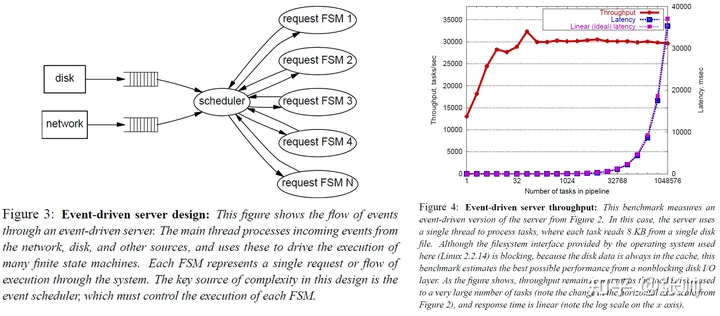
阶段性事件驱动(SEDA)模型

SEDA架构能对有穷状态机进行分析,而后将相关状态聚集在同一Stage中,Stage间采用队列的方式来进行通信。每一个Stage皆完全独立,均拥有自己的线程池,以及为了专门处理到达这一步骤所必须进行的工作。所有的Stage均通过自身事件队列连接在一起,构成完整的请求处理网络。性能控制器和动态线程池依请求的繁忙程度动态来调整线程池的大小,以达到系统资源的最有分配。每一个Stage由下述四部分组成:
(1) 事件队列:用以维持Stage间之通信。
(2) 事件处理器:用以执行请求到这一个Stage中所应执行的工作。
(3) 线程池:用以提供事件处理器且可以并发执行事件处理之环境。
(4) 性能控制器:用以对该Stage资源(线程数、队列长度等等)进行调整。 通过这四部分的协作配合,每一个Stage都可以很好地运行,并且可以控制资源的使用。已经过Stage处理完,若没有后续工作,即可以回收线程池中的线程,来供给其他Stage使用。Stage结构如下图所示。
在SEDA架构中,基本的处理单元称为阶段(Stage),一个阶段由事件队列、动态线程池、事件处理器和一个性能控制器四个组件构成。SEDA将一个请求的处理过程分解为一系列的阶段,阶段之间通过事件队列联系,开发人员只负责每个阶段的服务逻辑以及阶段间的连接逻辑,而由各个阶段自身负责资源管理以及负载适应功能。使用这种解耦拆分可以使系统达到高并发性、对负载变化的良好适应性以及高度的可缩放性。
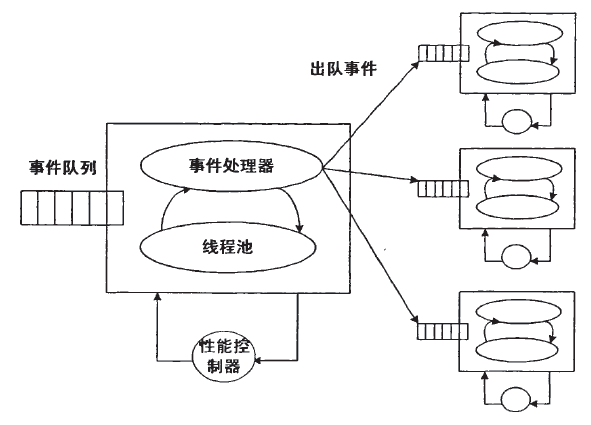
这种做法有点类似于 actor model(这里就不展开介绍了 actor model 了,感兴趣的可以看看 akka 的文档和 erlang)。但是传统的 actor model 是把线程 attach 到 actor 上而非 mailbox 上的。但是确实看起来把运算资源 attach 到 queues 或者说 scheduler 上可能更合理一些。Apache Hadoop 和 Microsoft Orleans 貌似都是这么做的。
论文里还提到了线程池是可以自我调节的,这里提到了可以调节线程池的线程数和一次执行时候的批大小。带自动伸缩功能的线程池其实不算太少见,但是在设计 API 的时候就考虑批执行的 API 还是比较少见的。以个人的经验来看,批执行确实有可能显著的提升计算能力,主要考虑这些方面。
- 更少的锁争用(拿一次锁可以跑一批数据而非只跑一条数据)
- 更好复用一些临时资源
- 更好的缓存利用
- 可能从 SIMD 指令集中受益
在一些特殊的场景中也有可能使用更复杂的策略。
基础代数符号与操作
选择操作符
使用选择操作符时的算法通常是Scan,其中有线性扫描,也有索引扫描。通常对同一张表有多次选择的条件,应该将这多个条件优化到一次。
- 示例1:合并多个选择,该方法适合于对同一张表上有多个相同的选择条件而言,此时可以合并多次的选择,以减少多次过滤带来的消耗。比如条件
where T.a=T.b and T.b=T.c,这个条件是一个和的操作,需要过滤两次。因此在内部可以将它优化成一个过滤条件,直接判断T.a=T.b=T.c,而不是先判断T.a=T.b,再判断T.b=T.c。 - 示例2:分解多个选择,比如SQL语句
select * from T where T.a=35 OR T.b>8,假设 T 表的a和b组上都有各自的索引。这时候可以将这个SQL分解为两个SQL(select * from T where T.a=3 UNION select * from T where T.b>8),各自利用索引加速进行查询,最后再合并结果,而不必因为OR导致索引失效。在实际实现上把OR给改写成UNION是一种很常见的改写。
投影操作符
使用投影操作能够减少列从而减少中间临时关系的内存消耗,如果一个操作最后需要投影,那么完全可以先投影后再做其他操作来减小操作中间的复杂度。
连接操作
链接除了笛卡尔积和链接,还有inner join、left join、right join、full join。其中inner join称为内连接,其余三个称为外连接(outjoin)。一般来说都会将外连接改写成内连接,因为内连接可以有更多的连接顺序选择、基表谓词条件下压,来更好的查询计划提高查询效率。可以看这个系列的博客SQL改写系列

这里列举了几种连接算法的伪码,可以帮助理解每一种连接算法的原理。
- Nest-loop join算法的基本思想就是两个for循环。每次会迭代外表的一行,然后再以此为驱动去迭代内表的每一行tuple,如果满足连接条件,就会加入结果集。这里有一个基本的优化思想,即可以将小表放在外层作为驱动表,这样会减少内表的循环次数,从而也会减少内表的遍历次数。
For t IN Rt:
For s IN Rs:
resutLt.add(t,S)- Index Nest-loop join算法是利用索引加速的一个嵌套循环算法。假设在内表有索引,且是一个等值的,每次驱动外表的一行,内表可以利用等值进行一个索引搜索,就不需要去遍历内表的全部元组,从而减少IO的消耗。
For t IN Rt:
For s IN Rs using index:
resutlt.add(t,S)- Block Nest-loop join算法的基本思想是每次的迭代不再是一行的tuple,而是按块进行连接运算。先读取Rt表的一个Block,再读遍读取Rs的一个Block,然后将这两个表的元组进行连接。这个算法的基本思想就是不再以行为粒度,而是以块为粒度,从而减少IO的消耗。
For Bt IN Rt:
For Bs IN Rs:
For t IN Bt:
For s IN Bs:
resutlt.add(t,S)- merge join算法利用了归并排序的思想,先将两张关联表各自做排序,然后从各自的排序表中去抽取数据到另一个排序表中做一些条件匹配,从而生成结果集,示例中没有把它的伪码写的很详细,但可以说明基本的原理就是归并的思想。
Ra=Sort(Rt)
Rb=Sort(Rs)
Merge_join(Ra,Rb)--resuLt.add(t,S)- hash join算法是将其中一张表先在内存中建立一个哈希表,这张表通常是两张表中比较小的那一张表。需要注意的是,如果这个哈希表比较大,无法一次性构造在内存中,那就需要将这张表分多个Partition写入磁盘,就会多一个写的拆架,也会降低效率。因此hashjoin算法通常适合于较小的表,可以完全存放在内存中。
HT=BuiLd_hash(Rt)
For s IN Rs:
if hask_key(s) found in HT:
resuLt.add(t,s)通常merge join的效率会比hash join差,但如果两张关联的表已经排序好了,此时就不需要做排序操作,这时merge join的效率就不一定比hash join差了。
交、并、差和聚合
交、并、差是涉及到多表的运算,通常用merge join或者 hash join的思想,与之前连接的去标在于在merge或hash的过程汇总去重
聚合操作也是同理,通常通过merge或hash将同一组中的元组放在一起,然后在每个组内进行相应聚合函数的实现。
- 部分聚合,对于count、min、max和sum,可以保留组中目前找到的元组的聚合值。
- 当将部分聚合合并为计数时,将部分聚合相加。
- 对于avg,保留sum和count,并在最后用sum除以count。
启发式规则
在前文介绍的等价规则转换的基础上,加入代价的判断,有些代价不好估计,但有些规则经过长期的验证,已经确认是有效的。如下列举了一些规则,在优化器里面会考虑这些启发式规则带来的优势,尽量去应用这些启发式的规则。
- 选择尽量下推
- 投影尽早下推
- 连接消除避免完全第卡尔积操作
- 连接的一个关系在连接属性上有索引,将这关系放在内层循环中采用索引连接
- 连接的一个参数是排序的,用merge join可能比hash join好
- 多个关系的并或交时,先对最小关系进行组合
- 子查询的消除
- 嵌套连接的消除
- 使用等价调词重写对条件化简

