概述
首先,先问自己一个问题,什么是协程?,为什么需要协程?,能解决什么痛点?
协程,what,why?
什么是协程,现在流行的有几种说法:
- 第一种: “可以暂停和恢复执行” 的函数,其“全部精神就在于控制流的主动让出和恢复”。这种观点来自协程概念的提出者Conway在1963年发表的论文”Design of a separable transition-diagram compiler“
- 第二种:是运行在用户态的线程,避免了向内核态下陷从而提高性能。实现一个用户态线程有两个必须要处理的问题:一是碰着阻塞式I\O会导致整个进程被挂起;二是由于缺乏时钟阻塞,进程需要自己拥有调度线程的能力。如果一种实现使得每个线程需要自己通过调用某个方法,主动交出控制权。那么我们就称这种用户态线程是协作式的,即是协程。
- 第三种:Coroutines are computer program components that generalize subroutines for non-preemptive multitasking, by allowing execution to be suspended and resumed. —— from Wikipieda
所以这几种定义哪个才是协程,还是说他们都对?然后是我们为什么要协程?
- 让原来需要使用异步+回调方式写的非人类代码,用看似同步的方式写出来
- 既要同步编程风格,能够让业务开发人员很便捷地去开发业务逻辑代码,同时能够达到「异步回调模型的性能」。
有栈协程与无栈协程
如今协程已经成为大多数语言的标配,例如 Golang 里的 goroutine,JavaScript 里的 async/await。尽管名称可能不同,但它们都可以被划分为两大类,一类是有栈(stackful)协程,例如 goroutine;一类是无栈(stackless)协程,例如 async/await。
此处「有栈」和「无栈」的含义不是指协程在运行时是否需要栈,对于大多数语言来说,一个函数调用另一个函数,总是存在调用栈的;而是指协程是否可以在其任意嵌套函数中被挂起,此处的嵌套函数读者可以理解为子函数、匿名函数等。显然有栈协程是可以的,而无栈协程则不可以。似乎难以理解?不要慌,让我们先从函数调用栈开始讲起。
函数调用栈
调用栈是一段连续的地址空间,无论是 caller(调用方)还是 callee(被调用方)都位于这段空间之内。而调用栈中一个函数所占用的地址空间我们称之为「栈帧」(stack frame),调用栈便是由若干个栈帧拼接而成的。
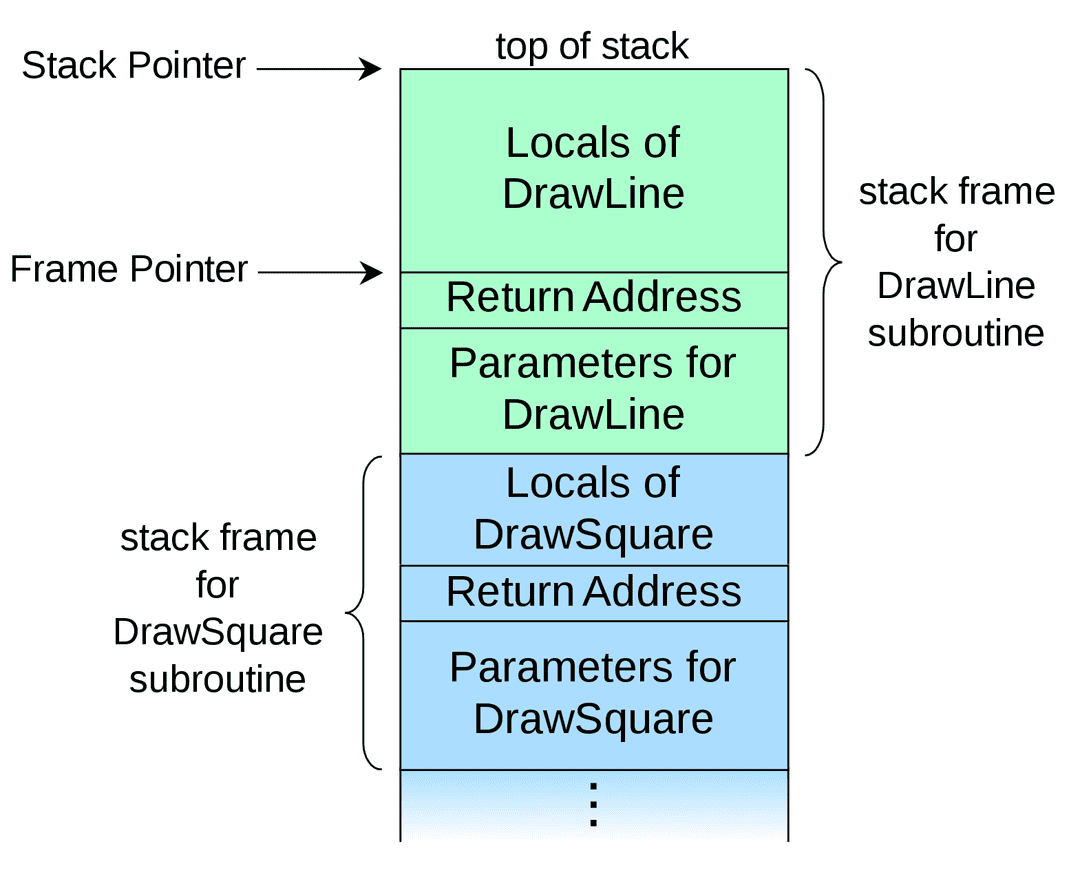
Stack Pointer 即栈顶指针,总是指向调用栈的顶部地址,该地址由 esp 寄存器存储;Frame Pointer 即基址指针,总是指向当前栈帧(当前正在运行的子函数)的底部地址,该地址由 ebp 寄存器存储。Return Address 则在是 callee 返回后,caller 将继续执行的指令所在的地址;而指令地址是由 eip 寄存器负责读取的,且 eip 寄存器总是预先读取了当前栈帧中下一条将要执行的指令的地址。
我们可以很轻易地构造一段 C 代码,然后将其转换为汇编,看看底层究竟做了什么。网页上推荐使用 Compiler Explorer 查看汇编更加简洁清晰。
int callee() { // callee:
// pushl %ebp
// movl %esp, %ebp
// subl $16, %esp
int x = 0; // movl $0, -4(%ebp)
return x; // movl -4(%ebp), %eax
// leave
// ret
}
int caller() { // caller:
// pushl %ebp
// movl %esp, %ebp
callee(); // call callee
return 0; // movl $0, %eax
// popl %ebp
// ret
}当 caller 调用 callee 时,执行了以下步骤(注意注释中的执行顺序:
callee:
// 3. 将 caller 的栈帧底部地址入栈保存
pushl %ebp
// 4. 将此时的调用栈顶部地址作为 callee 的栈帧底部地址
movl %esp, %ebp
// 5. 将调用栈顶部扩展 16 bytes 作为 callee 的栈帧空间;
// 在 x86 平台中,调用栈的地址增长方向是从高位向低位增长的,
// 所以这里用的是 subl 指令而不是 addl 指令
subl $16, %esp
...
caller:
...
// "call callee" 等价于如下两条指令:
// 1. 将 eip 存储的指令地址入栈保存;
// 此时的指令地址即为 caller 的 return address,
// 即 caller 的 "movl $0, %eax" 这条指令所在的地址
// 2. 然后跳转到 callee
pushl %eip
jmp callee
...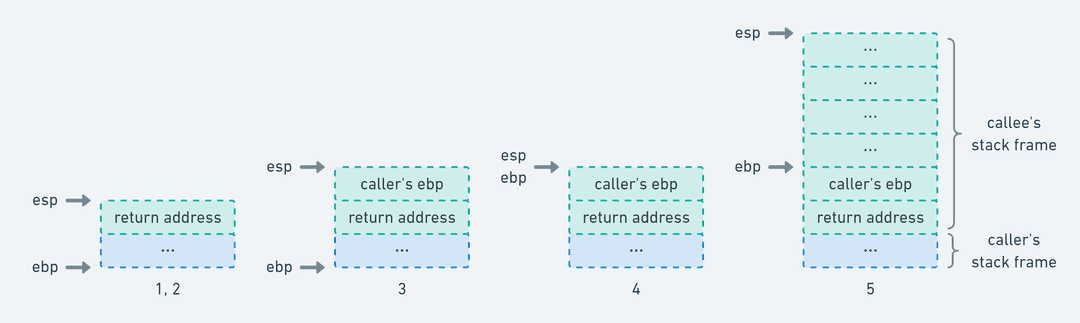 caller 调用 callee 的调用栈变化(忽略传参)
caller 调用 callee 的调用栈变化(忽略传参)
当 callee 返回 caller 时,则执行了以下步骤(注意注释中的执行顺序:
callee:
...
// "leave" 等价于如下两条指令:
// 6. 将调用栈顶部与 callee 栈帧底部对齐,释放 callee 栈帧空间
// 7. 将之前保存的 caller 的栈帧底部地址出栈并赋值给 ebp
movl %ebp, %esp
popl %ebp
// "ret" 等价如下指令:
// 8. 将之前保存的 caller 的 return address 出栈并赋值给 eip,
// 即 caller 的 "movl $0, %eax" 这条指令所在的地址
popl eip
caller:
...
// 9. 从 callee 返回了,继续执行后续指令
movl $0, %eax
...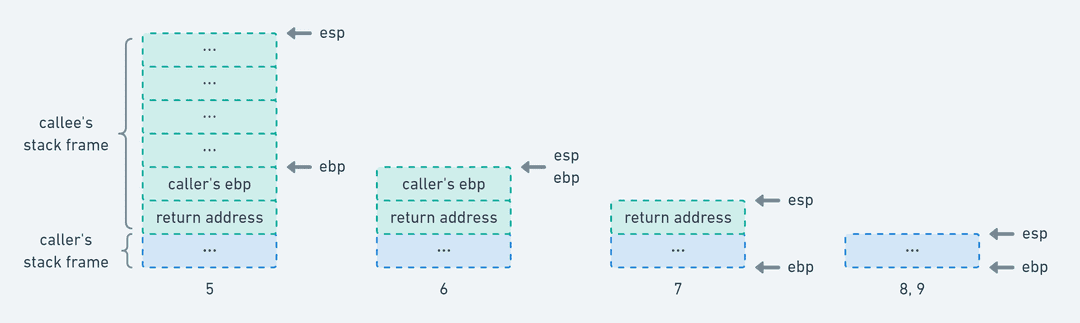 callee 返回 caller 的调用栈变化(忽略传参)
callee 返回 caller 的调用栈变化(忽略传参)
以上便是函数调用栈的大致运行过程了。当然真实的调用栈运行过程要复杂一些,需要带上参数传递等等,对此感兴趣,则推荐阅读这篇文章 C Function Call Conventions and the Stack。
有栈协程
实现一个协程的关键点在于如何保存、恢复和切换上下文。已知函数运行在调用栈上;如果将一个函数作为协程,我们很自然地联想到,保存上下文即是保存从这个函数及其嵌套函数的(连续的)栈帧存储的值,以及此时寄存器存储的值;恢复上下文即是将这些值分别重新写入对应的栈帧和寄存器;而切换上下文无非是保存当前正在运行的函数的上下文,恢复下一个将要运行的函数的上下文。有栈协程便是这种朴素思想下的产物,即类似于内核态线程的实现,不同协程间切换还是要切换对应的栈上下文,只是不用陷入内核而已。
有栈协程是可以在其任意嵌套函数中被挂起的 —— 毕竟它都能保存和恢复自己完整的上下文了,那自然是在哪里被挂起都可以。我们可以自己实现一个简单的例子证明这个事实,同时也有助于我们从底层理解有栈协程的运行过程。
首先我们需要申请一段能存储上下文的内存空间。在保存上下文时,我们可以选择把上下文都拷贝到这段内存;亦或者直接将这段内存作为协程运行时的栈帧空间,这样就能避免拷贝带来的性能损失了。注意,如果申请的内存空间小了,协程在运行时会爆栈;如果大了,则浪费内存;不过具体的分配策略我们就不做过多讨论了。
同时还需要保存寄存器的值。这里便涉及到了函数调用栈中的一个知识点,根据约定,有的寄存器是由 caller 负责保存的,如 eax、ecx 和 edx;而有的寄存器是 callee 负责保存的,如 ebx、edi 和 esi。对于被调用的协程而言,只需要保存 callee 相关的寄存器的值,调用栈相关的 ebp 和 esp 的值,以及 eip 存储的 return address。
// *(ctx + CTX_SIZE - 1) 存储 return address
// *(ctx + CTX_SIZE - 2) 存储 ebx
// *(ctx + CTX_SIZE - 3) 存储 edi
// *(ctx + CTX_SIZE - 4) 存储 esi
// *(ctx + CTX_SIZE - 5) 存储 ebp
// *(ctx + CTX_SIZE - 6) 存储 esp
// 注意 x86 的栈增长方向是从高位向低位增长的,所以寻址是向下偏移的
char **init_ctx(char *func) {
// 动态申请 CTX_SIZE 内存用于存储协程上下文
size_t size = sizeof(char *) * CTX_SIZE;
char **ctx = malloc(size);
memset(ctx, 0, size);
// 将 func 的地址作为其栈帧 return address 的初始值,
// 当 func 第一次被调度时,将从其入口处开始执行
*(ctx + CTX_SIZE - 1) = (char *) func;
// https://github.com/mthli/blog/pull/12
// 需要预留 6 个寄存器内容的存储空间,
// 余下的内存空间均可以作为 func 的栈帧空间
*(ctx + CTX_SIZE - 6) = (char *) (ctx + CTX_SIZE - 7);
return ctx + CTX_SIZE;
}接下来,为了保存和恢复寄存器的值,我们还需要撰写几段汇编代码。假设此时我们已经将存储上下文的内存地址赋值给了 eax,则保存的逻辑如下:
// 依次将各个寄存器的值存储;
// 注意 x86 的栈增长方向是从高位向低位增长的,所以寻址是向下偏移的
movl %ebx, -8(%eax)
movl %edi, -12(%eax)
movl %esi, -16(%eax)
movl %ebp, -20(%eax)
movl %esp, -24(%eax)
// %esp 存储的是当前调用栈的顶部所在的地址,
// (%esp) 是顶部地址所指向的内存区域存储的值,
// 将这个值存储为 return address
movl (%esp), %ecx
movl %ecx, -4(%eax)而与之相对应的恢复逻辑如下:
// 依次将存储的值写入各个寄存器;
// 注意 x86 的栈增长方向是从高位向低位增长的,所以寻址是向下偏移的
movl -8(%eax), %ebx
movl -12(%eax), %edi
movl -16(%eax), %esi
movl -20(%eax), %ebp
movl -24(%eax), %esp
// %esp 存储的是当前调用栈的顶部所在的地址,
// (%esp) 是顶部地址所指向的内存区域存储的值,
// 将存储的 return address 写入到该内存区域
movl -4(%eax), %ecx
movl %ecx, (%esp)而前文已经说过,切换上下文无非是保存当前正在运行的函数的上下文,恢复下一个将要运行的函数的上下文。于是我们可以基于上述两段汇编构造一个 void swap_ctx(char **current, char **next) 函数,分别传入 char **init_ctx(char *func) 构造好的上下文即可实现切换。为了方便使用,我们可以将 swap_ctx() 封装成 yield() 函数,在这个函数里简单实现了不同函数的调度逻辑。于是一个简单的例子便完成了:
char **MAIN_CTX;
char **NEST_CTX;
char **FUNC_CTX_1;
char **FUNC_CTX_2;
void nest_yield() {
yield();
}
void nest() {
// 随机生成一个整数作为 tag
int tag = rand() % 100;
for (int i = 0; i < 3; i++) {
printf("nest, tag: %d, index: %d\n", tag, i);
nest_yield();
}
}
void func() {
// 随机生成一个整数作为 tag
int tag = rand() % 100;
for (int i = 0; i < 3; i++) {
printf("func, tag: %d, index: %d\n", tag, i);
yield();
}
}
int main() {
MAIN_CTX = init_ctx((char *) main);
// 证明 nest() 可以在其任意嵌套函数中被挂起
NEST_CTX = init_ctx((char *) nest);
// 证明同一个函数在不同的栈帧空间上运行
FUNC_CTX_1 = init_ctx((char *) func);
FUNC_CTX_2 = init_ctx((char *) func);
int tag = rand() % 100;
for (int i = 0; i < 3; i++) {
printf("main, tag: %d, index: %d\n", tag, i);
yield();
}
free(MAIN_CTX - CTX_SIZE);
free(NEST_CTX - CTX_SIZE);
free(FUNC_CTX_1 - CTX_SIZE);
free(FUNC_CTX_2 - CTX_SIZE);
return 0;
}完整的代码可通过 这个链接 获得,使用 gcc -m32 stackful.c stackful.s 编译,然后运行 ./a.out 的得到如下结果:
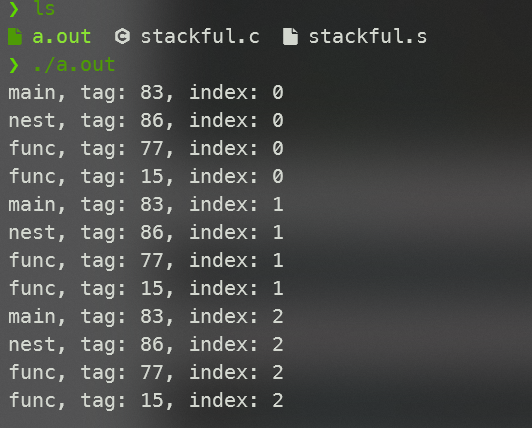
可以注意到 tag 的值在每次调度过程中均未改变,而循环叠加 index 的逻辑也并未因为挂起和恢复受到影响。所以 nest() 的确是可以在其任意嵌套函数中被挂起;同时我们还证明了同一个函数被调用多次时,的确是在不同的栈帧空间上运行的。
无栈协程
相比于有栈协程直接切换栈帧的思路,无栈协程在不改变函数调用栈的情况下,采用类似生成器(generator)的思路实现了上下文切换,此处请直接阅读文章 使用 C 语言实现协程 —— 尽管作者在文中没有说明,但这正是一种无栈协程的实现。无栈协程的本质就是一个状态机(state machine),它可以理解为在另一个角度去看问题,即同一协程协程的切换本质不过是指令指针寄存器的改变。
此外我们还可以通过译文提供的 coroutine.h 看到,作者通过 C 语言的宏将所有协程的变量统一包装进了一个结构体,然后再为这个结构体申请内存空间,从而实现了分配确定大小的内存空间,避免了内存浪费 —— 而这正是有栈协程所做不到的。
从执行时栈的角度来看,其实所有的协程共用的都是一个栈,即系统栈,也就也不必我们自行去给协程分配栈,因为是函数调用,我们当然也不必去显示的保存寄存器的值,而且相比有栈协程把局部变量放在新开的空间上,无栈协程直接使用系统栈使得CPU cache局部性更好,同时也使得无栈协程的中断和函数返回几乎没有区别,这样也可以凸显出无栈协程的高效。
对称协程和非对称协程
其实对于“对称”这个名词,阐述的实际是协程之间的关系,用大白话来说就是对称协程就是说协程之间人人平等,没有谁调用谁一说,大家都是一样的,而非对称协程就是协程之间存在明显的调用关系。
简单来说就是这样:
- 对称协程 Symmetric Coroutine:任何一个协程都是相互独立且平等的,调度权可以在任意协程之间转移。
- 非对称协程 Asymmetric Coroutine:协程出让调度权的目标只能是它的调用者,即协程之间存在调用和被调用关系。
回到开头的问题,协程分为无栈协程和有栈协程两种,无栈指可挂起/恢复的函数,有栈协程则相当于用户态线程。有栈协程切换的成本是用户态线程切换的成本,而无栈协程切换的成本则相当于函数调用的成本。
- 无栈协程和线程的区别:无栈协程只能被线程调用,本身并不抢占内核调度,而线程则可抢占内核调度。
- 协程函数与普通函数的区别:普通函数执行完返回,则结束,协程函数可以运行到一半,返回并保留上下文;下次唤醒时恢复上下文,可以接着执行。

