概述
Memory Order不难理解,需要的只是重新建立一种世界观,需要的只是强迫自己接受那些从来没关注过的东西,就像两个铁球同时落地一样。
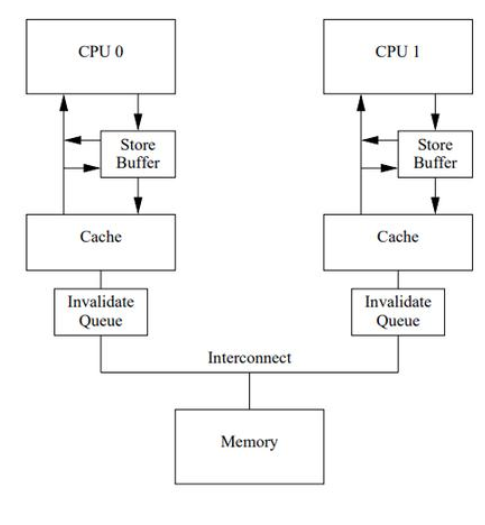
架构
1)store buffer,这个是用于存储cpu产生的临时值,它是cpu的私有区,其它核是看不到的,换句话讲,它会导致在整个系统中,同一个内存值数据,它会有多个副本的存在,也就是会出现不同的cpu看到的值是不一样的,也就是会导致数据一致性问题。
2)invalidate queue,这个一般在弱序系统中比较常见,它用于加速类似MESI这种cache一致性协议的共识过程,比如说,cpu0在同步store buffer数据到cache时,它会发送Read Invalidate消息,而cpu1并不是立即处理的,它可以先把Read Invalidate的消息先放在invalidate queue里,然后就立马回应ACK返回了,这样处理的好处就是,对于cpu0来说 ,它能更快处理Read Invalidate的共识过程,但是导致的结果,就是cpu1它因为不是及时处理的,所以对于cpu1来说,它看到的值可能不是最新的,也就是它会导致跟store buffer存在一样的问题,数据一致性问题。
3)cache,对于cache来说,不同系统结构采取的方式有可能不一样,l1 cache,l2cache,有些系统甚至有l3 cache,l4 cache,甚至有victim cache等等,各cache之间数据处理策略也会有差异,比如有些采用inclusive方式,有些采用exclusive方式,甚至有些采用NINE方式,也就是混合模式,Non-Inclusive-Non-Exclusive方式。虽然cache的实现方式多种多样,但是有一点是通识的,进入cache后,可以认为数据进入了公共可见区,也就是但凡进入cache的数据,都会走一个cache cycle,它会根据不同策略,做处理。但这里要明白的是,虽然数据进入了公共可见区,但读端是不是立即能读取到这个值,还取决于读端的硬件结构,比如上面说的Invalidate queue的存在,所以对于这样的弱序系统来说,对于读端,要想读取公共可见区的同一个值,它都需要使用内存屏障来做同步处理,而不是简单的一个汇编读就可以了。
什么是 Memory Order
简单来说,就是 CPU 访问内存的顺序。为什么要研究这个顺序呢?因为 CPU 并不是按照我们写的程序的先后顺序来访问内存的,在编译和执行阶段,都会进行一定程度的指令重排,CPU 随便乱序执行,以提升执行效率。
为什么感知不到 Memory Order
我们在日常不考虑 Memory Order 写代码的时候,想用原子变量就直接 atomic<int> ,然后对这个变量做运算。实际上,C++ 在这里规定,不显式的写 memory_order_xxx ,就已经隐含了最强的 Memory Order。
int a{0};
atomic<int> b{0};
// Thread A
a = 6;
b = 7;
// Thread B
if (b == 7) {
assert(a == 6);
}在 A 线程,我写了 a 在 b 之前 set,那么读到了 b 的时候,a 的值肯定已经被 set 过了。实际上,在 C++ 的语义上,允许更弱的内存模型,如果这里不用默认的最强 Memory Order,而用相对最弱的 relaxed,Thread B 中的 assert 是有可能 fail 的。
另外,在单线程内,编译器也遵循 as-if 规则,不会做让程序员感知到影响执行效果的优化。
C++ 语义
ref:std::memory_order - cppreference.com
在 C++ 语义上,一共暴露了 4 种 Memory Order:
- relaxed
- release-acquire
- release-consume
- sc (sequential consistency)
relaxed
其中,relaxed 最好理解,在 C++ 语义层面,允许任何 reorder。例如:
// x == 0 && y == 0
// Thread 1:
r1 = y.load(std::memory_order_relaxed); // A
x.store(r1, std::memory_order_relaxed); // B
// Thread 2:
r2 = x.load(std::memory_order_relaxed); // C
y.store(42, std::memory_order_relaxed); // D这里面,CD 可以 reorder,因此可能的执行顺序是 DABC,这样 r1 和 r2 可以都是 42。
release-acquire
假设在 A 线程 release store x 变量,在 B 线程 acquire load x 变量。在 C++ 语义层面,可以确保:
- 如果 B 线程的 acquire load x 能看到 x 变量被 release store x 了,那么 B 线程的这个 acquire load x 可以看到 A 线程在 release store x 之前的所有 store。
- B 线程在 acquire load x 之后的所有 load,都可以看到这个 acquire load x。
总结这两点,得出一个更强的结论:如果 B 线程的 acquire load x 能看到 x 变量被 release store x 了,那么 B 线程在 acquire load x 之后的所有 load ,都可以看到 A 线程 release store x 之前所有的 store。
同时,还有:
- 在 acquire 线程中,任何 acquire load 之后的读写不能拿到 acquire load 之前。
- 在 release 线程中,任何 release store 之前的读写不能拿到 release store 之后。
release-consume
与 release-acquire 不同的是,release-consume 可以只同步依赖的变量。也就是说,在 consume load x 的时候,保证能看到x.store(k, mo_release)之前所有与 k 有关的变量 store 即可。
sc
sc 比 release-acquire 更强,拥有 total order。
具体强在 2 个例子。
第一个例子:
// a == 0 && b == 0
// Thread 1
x.store(1,std::memory_order_release);
// Thread 2
y.store(1,std::memory_order_release);
// Thread 3
int a = x.load(std::memory_order_acquire);
int b = y.load(std::memory_order_acquire);
// Thread 4
int c = y.load(std::memory_order_acquire);
int d = x.load(std::memory_order_acquire);如上,如果采取 release-acquire 模式,thread 3 和 thread 4 的视图可能会不一样。在 Thread 3 中,x 可以早于 y load;而在 Thread 4 中,y 可以早于 x load。因此,可能 a == c == 1;而 b == d == 0。两个线程可能两者会维护不一样的视图,没有 total order,只要满足 release-acquire 原则就行了。
而如果采取 memory_order_seq_cst ,必须全局维护一个视图,不可能存在上述情况。
第二个例子:
// x == 0 && y == 0
// Thread 1
x.store(1,std::memory_order_release);
int c = y.load(std::memory_order_acquire);
// Thread 2
y.store(1,std::memory_order_release);
int d = x.load(std::memory_order_acquire);回忆一下,release-acquire 只要求:在 acquire 线程中,任何 acquire load 之后的读写不能拿到 acquire load 之前;在 release 线程中,任何 release store 之前的读写不能拿到 release store 之后。但是有一种 reorder 是允许的,就是可以把 store 拿到 load 之后,把 load 拿到 store 之前。如上:Thread 1 和 Thread 2 都可以把 load 拿到 store 之前,得到 c == d == 0。
而如果采取 memory_order_seq_cst ,同样地,必须全局维护一个视图,不可能存在上述情况。
Use Cases
对于 relaxed 语义而言,最常见的应用是各种计数器。因为对计数器的 store 和 load,几乎不依赖其他任何变量,就单纯的 emit 一下即可。
对于 acquire-release 而言,最常见的是在有锁编程:lock 的时候,必须是先获取锁,然后再访问数据; unlock 的时候,必须先写完数据,再释放锁。这就是典型的 acquire-release 语义。
对于 sc,当依赖多个变量的时候,可能必须要求这些变量有 total order,每个线程持有不同的视图可能会造成非预期的错误。
例如:
- Thread A 的逻辑是,while 死循环,当 x == true 的时候退出死循环,判断 y 是不是 true,是 true 的话 ++z。
- Thread B 的逻辑是,while 死循环,当 y == true 的时候退出死循环,判断 x 是不是 true,是 true 的话 ++z。
这里,如果用 acquire-release 语义,并且 x 和 y 是单独的两个线程来 store,就很有可能,在 Thread A 看来 x == true && y == false。在 Thread B 看来 y == true && x == false。这样 z 一次都没有 ++。
因此“当一个变量的访问,依赖其他 >= 2 个变量的判断条件”的时候,这 >= 2 个变量最好都用 sc 保护。
x86 Memory Order 语义
并不是所有的 ISA 都支持任何程度的 reorder,有些 ISA 的默认 memory order 也可能足够强,例如 x86。
x86 并不是 relaxed memory model,而是异常的 strong,甚至可以保证 total store order。
x86 的 memory order 语义如下:
- load-load 和 store-store 都不能 reorder。
- load-store 不能 reorder。
- store-load 可以 reorder。
- thread a 的 store 和 thread b 的 store,在 thread a 和 thread b 中可以看到不同的顺序。
- thread a 的 store 和 thread b 的 store,在 thread c 和 thread d 中必须看到一致的顺序。
- store 的可见性可以传递。
- store 和 load 指令,都不能在 lock 指令前后 reorder。
C++ Memory Order 语义和 x86 Memory Order 语义的对应关系
当编程语言的语义要求比 ISA 强的时候(编程语言不允许某种 reorder,而 ISA 默认是允许的),ISA 需要对指令进行额外的 barrier 包装以支持编程语言的语义。
反之,如果 ISA 默认支持的语义足够强,ban 掉的情况比编程语言的语义要求的还多,那么就不需要 ISA 生成额外的指令了。只是编程语言的语义中承认的“哪种情况可以 reorder”,在 ISA 层面上有可能不会发生。
relaxed
对于 relaxed,C++ 规定任何语句都可以 reorder,然而 x86 限制了 load-load、load-store、store-store 都不能 reorder。因此对于 relaxed 而言,指定了 relaxed 的 store 和 load 指令,只剩下了 store-load 可以 reorder。因此上面 C++ 语义中,relaxed 举的例子是不可能发生的。
当然地,为了实现 relaxed 语义,不需要任何额外指令。
release-acquire
对于 x86 而言,由于不存在 store-store、load-load reorder,因此直接保证了“acquire load 可以看到 release store 之前的所有 store”以及“acquire load 之后的所有 load 都可以看到这个 acquire load” 这两个在 C++ Memory Order 语义上对 acquire-release 的要求,不需要任何额外指令。
另外,x86 语义是允许 store-load reorder(见 x86 memory order 语义 3)。不过,不用担心 x86 这个允许 reorder 的设定比较宽松,以至于 x86 上需要更多的同步指令来实现 release-acquire 语义——事实上,release-acquire 语义本身也是允许 store-load reorder 的
- acquire 语义是,任何 acquire 之后的读写不能拿到 load 前面,限制了 load-load 和 load-store 不能 reorder。
- release 语义是,任何 release 之前的读写不能拿到 store 后面,限制了 load-store 和 store-store 不能 reorder。
正好,acqurie-release 语义没限制 x86 语义允许的 store-load reorder。store 可以拿到 load 后面,load 也可以拿到 store 前面。因此,acquire-release 语义,对于 x86 来讲,是天然支持的,不需要额外指令。
可以认为,每一条 x86 的指令都是保证 release-acquire 语义的。
release-consume
普遍理性而论,正经的编译器和 ISA 都尊重这种数据依赖的先后顺序。唯一不尊重的就是 DEC Alpha。不需要太考虑 release-consume,直接当成 release-acquire 来看待。
因此,和 acquire-release 语义一样,对于 x86 来讲,不需要额外指令。
sc
最强内存顺序memory_order_seq_cst会补充x86 不满足 存储-加载顺序的缺失。
x86 Memory Order 语义和 x86 Memory Ordering 硬件模型的对应关系
关于上述 x86 Memory Order 语义,有以下的硬件解释:
load-load、store-store 和 load-store 都不能 reorder
由于 load 操作是原子的、瞬发的,因此 load-load、load-store 是不能 reorder 的。
由于 Write Buffer 是 FIFO 的,而且 Write Buffer flush 到 Shared Memory 也是按照 FIFO 有序的,并且 Shared Memory 保证强一致性,任何 flush 都可以被瞬间看到,因此 store-store 是不能 reorder 的。
store-load 可以 reorder
体现在硬件上,是由于 store-load 指令可以拆成 3 部分:
- 把 x 放到 Write Buffer
- 瞬时的 load y
- 把 Write Buffer flush 到 Shared Memory
因此其他线程从最终的表现来看(只有 flush 到 Shared Memory,其他线程才能看到),是先 load 了 y,后 store 了 x。
thread a 的 store 和 thread b 的 store,在 thread a 和 thread b 中可以看到不同的顺序
体现在硬件上,由于 Write Buffer flush 的时间不确定,因此,Thread a 的 store,目前还在 Thread a 的 Write Buffer 中,没有写到 Shared Memory;同时,Thread b 的 store,目前还在 Thread b 的 Write Buffer 中,没有写到 Shared Memory。
此时,Thread a 可以看到自己最近的 store,而 Thread b 可以看到自己最近的 store,而互相的 store 是看不到的。
thread a 的 store 和 thread b 的 store,在 thread c 和 thread d 中必须看到一致的顺序
由于 Thread c 看到了 Thread a 的 store,说明 Thread a 的 store 已经 flush 到了 Shared Memory 中。而 Shared Memory 是强一致的,Thread c 能看到的瞬间,Thread d 必须能看到。并且 Write Buffer 的 flush 操作是有序的,所以 store 如果被其他 Thread 看见了,那么此时这个 store 必然是有 total order 的。
store 的可见性可以传递
如果 Thread 2 看到了 Thread 1 的 store,那么 Thread 3 必然也可以看到 Thread 1 的 store,这是 Shared Memory 是强一致的直接结论。
任何 store 和 load 指令,都不能在 lock 指令前后 reorder
由于 LOCK 指令上一个全局的 Memory 锁,因此没有人可以读写任何 Memory,之后的读写都是 ban 掉的。而 LOCK 的同时,当前 Thread 的 Write Buffer 全部 flush 到 Shared Memory,因此 LOCK 释放的时候,可以保证当前 Thread 任何 store 命令都执行完了,而 load 命令是瞬发的,本来就会在任何指令之前执行完。
基本上可以认为,把上图中的 Write Buffer 拿掉(或者说,每次 store 都写穿 Write Buffer,直接到内存里),那么上面的硬件模型,就是天然满足 sc 的,所有指令都有 sc 语义保证,根本不需要 Lock 这个东西。
同样的,也可以说,x86 模型就是 sc 的模型加上了一个 FIFO Write Buffer,以及为了支持 sc 语义,能够让 store 原子地写穿 FIFO Write Buffer 的一个 Lock。
小结
推荐阅读这个回答:如何理解 C++11 的六种 memory order?,同时,除了无锁并发外很少使用这个,不是必要掌握!,从 The Go Memory Model 可以看到, golang 是非常不鼓励使用基于原子操作来实现同步的:
Programs that modify data being simultaneously accessed by multiple goroutines must serialize such access.
To serialize access, protect the data with channel operations or other synchronization primitives such as those in the sync and sync/atomic packages.
If you must read the rest of this document to understand the behavior of your program, you are being too clever.
Don’t be clever.

